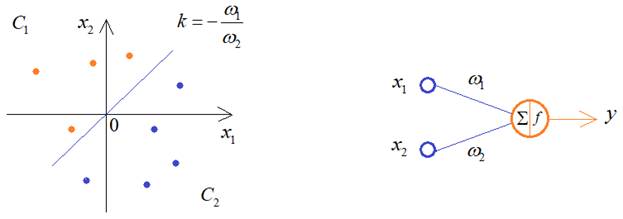|
Переобучение (overfitting). Критерии останова обученияКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs В курсе по машинному обучению мы с вами подробно говорили об эффекте переобучения моделей и некоторыми распространенными способами борьбы с ним: https://proproprogs.ru/ml/ml-lineynaya-model-ponyatie-pereobucheniya Все это в равной степени касается и нейронных сетей. Давайте вначале посмотрим, как их структура влияет на степень переобученности. А на последующих занятиях изучим некоторые популярные техники борьбы с переобучением НС, таких как Dropout и BatchNormalization. Итак, предположим, что у нас есть два класса линейно-разделимых образов:
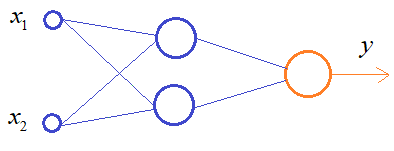
Для их различения достаточно одного нейрона, который будет описывать разделяющую линию. Но, что будет, если взять сеть с большим числом нейронов, для решения этой же задачи?
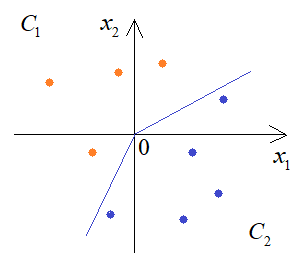
В процессе обучения она способна формировать уже более сложную разделяющую линию, например, следующим образом:
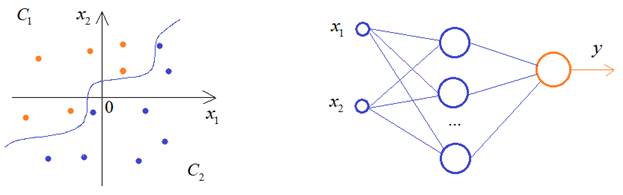
Если продолжить увеличивать число нейронов скрытого слоя, то будем получать все более сложную закономерность разделения двух классов:
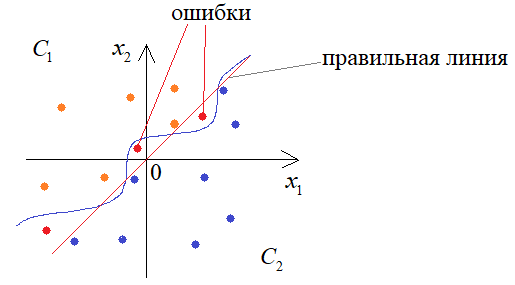
К чему это в итоге приведет? На обучающем множестве, конечно, все будет хорошо, но в процессе эксплуатации такой сети будем получать массу ошибок из-за слишком точного описания моделью граничных образов обучающей выборки:
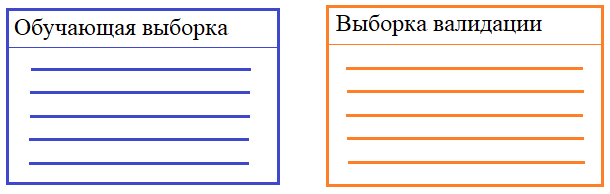
Этот эффект, как раз, и называется переобучением (overfitting). В результате слишком сильной постройки модели под образы выборки теряется ее обобщающая способность. И все из-за слишком большого числа нейронов. Такой вывод, на первый взгляд, может показаться несколько неожиданным. Казалось бы, чем больше нейронов, тем качественнее она должна работать. Но на практике часто имеем обратный эффект: избыток нейронов ухудшает обобщающие способности сети. В идеале, их количество должно быть ровно столько, сколько необходимо для решения поставленной задачи. Но как определить, сколько их нужно? Здесь, опять же, нет универсального ответа. Это определяется опытным путем, подбирая такое разумное количество нейронов, при котором получается приемлемое качество решения текущей задачи. Выборка валидацииРаз НС может переобучиться, спрашивается, как можно контролировать этот эффект непосредственно в процессе обучения. Для этого часто используют следующий прием. Обучающая выборка разбивается на два независимых множества: непосредственно обучающие и валидационные (проверочные).
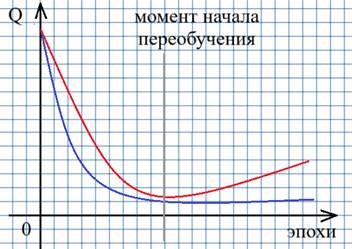
НС по-прежнему обучается на образах обучающей выборки. Но дополнительно после каждой эпохи вычисляется критерий качества работы НС по валидационной выборке. Получаем два графика показателя качества. Один построен по тренировочному множеству, а другой – по валидационному:
Если на какой-то итерации графики начинают расходиться, то делается вывод, что НС начинает переобучаться и дальнейший процесс обучения лучше остановить. Тогда текущие весовые коэффициенты будут соответствовать границе переобучения и есть шанс, что такая НС пока еще обладает достаточно хорошей обобщающей способностью. Здесь у вас может возникнуть вопрос: зачем мы разбиваем обучающую выборку, а не используем в качестве проверочного множества тестовое? Тем более, что на тестовом как раз и проверяется качество работы сети?
Дело в том, что как только какая-либо выборка прямо или косвенно участвует в обучении, то она уже не может являться объективным и независимым показателем качества работы НС. Поэтому для объективной проверки качества необходима третья выборка – тестовая. И это распространенная практика при обучении НС, которой следует придерживаться при исследованиях и разработки своих собственных архитектур НС. Использование выборки валидацииДавайте добавим выборку валидации в главный цикл обучения НС. Сами выборки можно сформировать следующим образом: dataset_mnist = torchvision.datasets.MNIST(r'C:\datasets\mnist', download=True, train=True, transform=transforms) d_train, d_val = data.random_split(dataset_mnist, [0.7, 0.3]) train_data = data.DataLoader(d_train, batch_size=32, shuffle=True) train_data_val = data.DataLoader(d_val, batch_size=32, shuffle=False) Здесь используется стандартный dataset класса MNIST с полной загрузкой всех изображений в память устройства. Это заметно ускоряет процесс обучения. Затем этот dataset с помощью функции random_split() делится на две части в пропорции: 70% - для обучающей выборки; 30% - для проверочной. Сама функция берется из ветки: torch.utils.data Первое слово random (в функции random_split) означает, что образы выбираются случайно, а не по порядку, что важно в процессе обучения и проверки (валидации). После формирования выборок запишем главный цикл обучения следующим образом: epochs = 30 loss_lst_val = [] # список значений потерь при валидации loss_lst = [] # список значений потерь при обучении for _e in range(epochs): model.train() loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=False) for x_train, y_train in train_tqdm: x_train = x_train.to(device) y_train = y_train.to(device) predict = model(x_train) loss = loss_function(predict, y_train) optimizer.zero_grad() loss.backward() optimizer.step() lm_count += 1 loss_mean = 1/lm_count * loss.item() + (1 - 1/lm_count) * loss_mean train_tqdm.set_description(f"Epoch [{_e+1}/{epochs}], loss_mean={loss_mean:.3f}") # валидация модели model.eval() Q_val = 0 count_val = 0 for x_val, y_val in train_data_val: with torch.no_grad(): p = model(x_val) loss = loss_function(p, y_val) Q_val += loss.item() count_val += 1 Q_val /= count_val loss_lst.append(loss_mean) loss_lst_val.append(Q_val) print(f" | loss_mean={loss_mean:.3f}, Q_val={Q_val:.3f}") В самом конце выведем графики полученных значений функции потерь при обучении и валидации: import matplotlib.pyplot as plt … # вывод графиков plt.plot(loss_lst) plt.plot(loss_lst_val) plt.grid() plt.show() По графикам можно судить, что НС несколько переобучается. Критерии останова процесса обученияВ заключение этого занятия рассмотрим критерии останова процесса обучения. Один из них мы с вами только что определили:
Но это лишь один из критериев. Кроме него часто используют еще несколько. Они следующие:
Конечно, критерии останова могут быть и другими. Я здесь привел лишь распространенные варианты, которые чаще всего используются на практике. Но, в каждой конкретной ситуации могут быть сформулированы свои критерии останова обучения сети.
Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |