|
Множества set и multiset в C++Курс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Мы продолжаем тему множеств. На предыдущем занятии мы увидели, как можно представлять упорядоченные множества на базе бинарных деревьев, а также выполнять операции с ними. Здесь же рассмотрим, как использовать эту структуру данных (то есть множества) в своих программах на языке C++. В этом языке есть два класса set и multiset стандартной библиотеки шаблонов STL, которые представляют собой упорядоченные множества. Чтобы воспользоваться этими классами, вначале нам нужно подключить заголовок set с помощью директивы #include следующим образом: #include <set>После этого в функции main() можно определить объект-множество, например, так: int main() { setlocale(LC_ALL, "ru"); using namespace std; set<int> s; return 0; } Здесь в угловых скобках после имени класса set, как всегда, указывается тип данных, который хранят элементы множества. Для простоты я по-прежнему использую целочисленный тип int. Если далее написать s и поставить точку, то интегрированная среда покажет набор методов для данного контейнера. Основных совсем немного и некоторые из них вам уже должны быть знакомы из рассмотрения подобных коллекций на предыдущих занятиях.
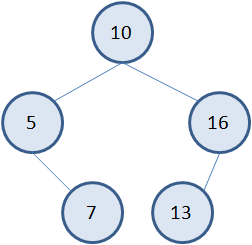
Начнем с метода insert(). При вызове этого метода формируется бинарное дерево с соответствующими значениями. Например: s.insert(10); s.insert(5); s.insert(7); s.insert(16); s.insert(13); Все эти значения будут храниться в узлах следующего бинарного дерева:
Давайте теперь посмотрим, как будет осуществляться перебор этих значений в множестве. Для этого воспользуемся циклом for следующим образом: for (auto& item : s) { cout << item << endl; } Видим на экране упорядоченные значения по возрастанию: 5, 7, 10, 13, 16 И вы уже знаете, как это можно было получить. При обходе бинарного дерева по алгоритму LNR (сначала левая ветвь, затем, вершина, потом правая ветвь), как раз получается упорядоченная по возрастанию последовательность значений. Разумеется, само дерево, при этом, должно формироваться по правилу: меньшие значения заносятся в левое поддерево, а большие – в правое поддерево. Так как множество set не может содержать дублирующие значения, то при попытке добавить существующее значение: s.insert(16); ничего не изменится, это значение будет просто проигнорировано. Вообще, метод insert() возвращает пару (итератор на элемент, булево значение): auto it = s.insert(2); Если добавление не было выполнено (например, при добавлении уже существующего значения), то второй элемент принимает значение false, а первый – итератор на существующий элемент. Если же добавление произошло успешно, то первое значение – итератор на добавленный элемент, а второй элемент принимает значение true. Помимо добавления новых элементов командой insert(), можно сразу инициализировать множество некоторыми начальными значениями, например, так: set<int> s = {10, 5, 7, 16, 13}; Далее, если нам нужно найти какое-либо значение в множестве, то для этого используется метод find(): auto it = s.find(5); Данный метод возвращает итератор на найденный элемент, либо значение s.end(), если элемент не был найден. То есть, мы можем использовать такую проверку: if (it != s.end()) cout << *it << endl; else cout << "число не найдено" << endl; Скорость работы данного метода составляет O(log n), т.к. используется алгоритм бинарного поиска. Для удаления какого-либо значения из множества используется метод erase(): s.erase(13); При удалении несуществующего элемента: s.erase(133); ничего не происходит, множество остается без изменений. Вообще, метод erase() возвращает 0, если удаление не было выполнено (например, при удалении несуществующего значения) и 1, если удаление выполнено успешно: auto res = s.erase(5); Контейнер multisetВ библиотеке STL есть еще одна похожая коллекция multiset, которая тоже представляет множество, но с возможностью хранить повторяющиеся значения. Для ее использования в программе нужно подключить тот же заголовок set: #include <set>И, затем, в программе создать объект этого класса, подобно классу set: multiset<int> ms; ms.insert(1); ms.insert(1); ms.insert(5); ms.insert(7); ms.insert(16); ms.insert(13); for (auto& item : ms) { cout << item << endl; } Так как в множестве могут присутствовать повторяющиеся значения, то дополнительно имеются методы lower_bound() и upper_bound(): multiset<int> ms = { 0, 2, 2, 2, 2, 13, 16, 7, 5 }; auto it1 = ms.lower_bound(2); auto it2 = ms.upper_bound(2); cout << *it1 << endl; cout << *it2 << endl; которые возвращают итератор на первое найденное значение 2 и на следующее значение после последней 2. Если значение не найдено, то итератор равен ms.end(). Также есть метод equal_range(), который возвращает диапазон итераторов для указанного значения. Например: auto r = ms.equal_range(2); for (auto it = r.first; it != r.second; ++it) cout << *it << " " << endl; Будут выведены все двойки. Операции над множествами в C++В заключение этого занятия продемонстрирую возможность использования основных операций над множествами. Для этого подключим еще один заголовок: #include <algorithm>В нем содержатся различные функции для выполнения операций над коллекциями, в том числе, и над множествами. Далее, сформируем два множества: set<int> setA = { 1, 3, 4, 5, 7 }; set<int> setB = { 0, 2, 3, 5, 4 }; и третье пустое для хранения результата: set<int> setC; Теперь мы можем использовать четыре функции:
для выполнения соответствующих операций. Давайте посмотрим, как это делается. Предположим, мы хотим вычислить пересечение двух множеств setA&setB. При вызове функции set_intersection() необходимо передать итераторы на диапазон элементов множеств setA и setB, которые будут участвовать в вычислении операции пересечения. В самом простом и распространенном варианте мы указываем начало множеств и до конца: set_intersection(setA.begin(), setA.end(), setB.begin(), setB.end(), inserter(setC, setC.begin())); В последний аргумент передается итератор для вставки значений в множество setC. Обратите внимание, что этот итератор формируется с помощью функции inserter() стандартной библиотеки. (Если это не совсем понятно, то данный момент можно просто запомнить, этого пока будет достаточно). После вывода значений множества setC в консоль: for (auto& item : setC) cout << item << " "; cout << endl; увидим значения: 3, 4, 5 По аналогии выполняются три остальные функции: set_union(setA.begin(), setA.end(), setB.begin(), setB.end(), inserter(setC, setC.begin())); set_difference(setA.begin(), setA.end(), setB.begin(), setB.end(), inserter(setC, setC.begin())); set_symmetric_difference(setA.begin(), setA.end(), setB.begin(), setB.end(), inserter(setC, setC.begin())); Вот базовые принципы использования множеств стандартной библиотеки в программах на С++. Курс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Видео по теме |