|
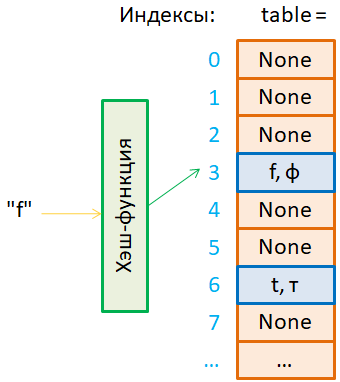
Метод открытой адресации. Двойное хэшированиеКурс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Мы продолжаем тему по хэш-таблицам. Это занятие начнем с рассмотрения метода открытой адресации для разрешения коллизий. При использовании этого метода предполагается данные (ключ, значение) хранить непосредственно в ячейках хэш-таблицы. Если ячейка пуста, то в нее записывается какое-либо предопределенное значение, например, None. То есть, мы отказываемся от дополнительного хранения указателей, и это приводит к некоторой экономии памяти. В результате мы имеем возможность формировать более длинные таблицы и, тем самым, уменьшать вероятность возникновения коллизий.
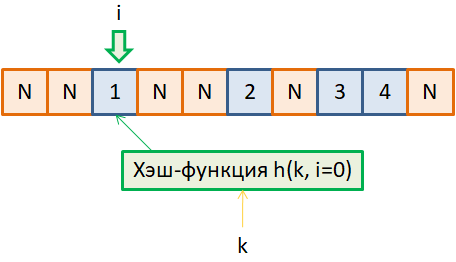
Но коллизии все равно будут появляться. Спрашивается, как с ними бороться в такой ситуации? Давайте вначале я продемонстрирую это на простом примере, а затем, мы его обобщим. Разрешение коллизий линейным исследованиемПредположим, у
нас есть некоторая хэш-функция
При этом
Вот принцип работы такой модифицированной хэш-функции с дополнительным параметром i. Но зачем нам все это понадобилось и как с помощью такой функции можно бороться с коллизиями? Для этого давайте вернемся к хэш-таблице и предположим, что в ней уже записано несколько ключей:
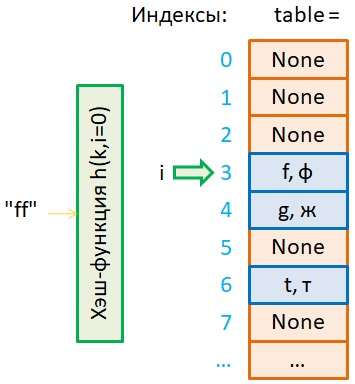
Мы подаем на
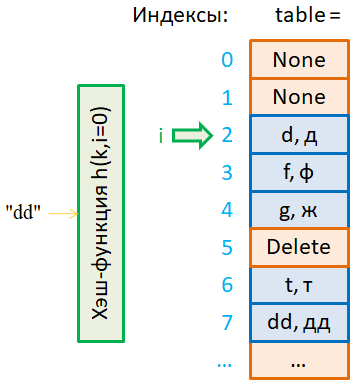
вход хэш-функции Главным недостатком этого метода разрешения коллизий является формирование длинных последовательностей занятых ячеек в хэш-таблице, то есть, образуются существенные неравномерности ее заполнения. А это, в свою очередь, негативно сказывается на скорости вставки, поиска и удаления ключей. Как это можно исправить, речь пойдет далее, а сейчас посмотрим, как работает алгоритм вставки (добавления) нового ключа. Алгоритмы поиска ключейПусть у нас имеется все та же хэш-таблица с открытой адресацией и мы хотим получить значение по ключу «ff». Вначале хэш-функция с параметром i=0 выдает значение 3. Так как в этой ячейке хранится другой ключ, то начинаем поиск, увеличивая параметр i каждый раз на единицу. В ячейке 5 находим искомый ключ и возвращаем его значение «фф». Давайте, теперь посмотрим, как будет происходить поиск не существующего ключа «dd». Предположим, хэш-функция выдала значение индекса 2. Там записан ключ «d». Это не то, что нам нужно. Поэтому мы начинаем поиск, увеличивая параметр i на единицу. Пока мы проходим по заполненным ячейкам, поиск продолжается, но как только встретили первую пустую, поиск завершается и делается вывод, что такого ключа в таблице нет. Я думаю, вы догадались, почему это так. Вспомним, когда происходит добавление ключей, то новый ключ при коллизии добавляется в первую попавшуюся пустую ячейку. Поэтому, если на этапе исследования попадается пустая ячейка, значит, указанного ключа просто нет в таблице. Благодаря этому, нам не нужно просматривать весь массив в надежде найти нужный ключ и это значительно ускоряет процесс поиска. Алгоритм удаления ключейЕсли же нам нужно удалить какой-либо ключ, то действуем аналогичным образом. Сначала по алгоритму поиска находим нужный ключ. Если он присутствует в таблице, то в ячейку записываем значение, нет, не None, а другую предопределенную константу Delete. Почему так? Дело вот в чем. Предположим, что после удаления ключа «ff» мы хотим найти ключ «dd». Пусть в этом случае хэш-функция возвращает 2-й индекс:
Тогда, при последовательном проходе, мы, дойдя до ячейки 5, остановились бы и сделали вывод, что ключа «dd» нет в таблице, тогда как он есть, просто ранее был удален ключ «ff» и нарушилась целостность последовательности заполненных ячеек. Чтобы этого не было, мы используем другую константу Delete, которая означает, что ячейка пуста, но поиск последующих ключей все равно нужно продолжать, пока либо не найдем искомый ключ, либо не дойдем до ячейки со значением None. Вот такая тонкость имеется в алгоритме удаления и последующего поиска ключей с учетом удаленных элементов. Разрешение коллизий квадратичным исследованиемИтак, мы с вами только что познакомились с методом разрешения коллизий линейным исследованием, когда используется открытая адресация, то есть хранение данных непосредственно в ячейках хэш-таблицы. Это метод можно обобщить и в общем случае определить некоторую хэш-функцию:
которая бы
перебирала ячейки массива при изменении параметра Как же сделать так, чтобы перебор ячеек был нелинейным? Первое, что приходит в голову – это воспользоваться квадратической функцией и индексы последующих ячеек искать по правилу:
где a, b – некоторые
положительные константы. Причем значения a, b и m нужно выбирать
так, чтобы при изменении i в диапазоне [0; m-1] функция Двойное хэшированиеНо все же, как
бы нам так построить хэш-функцию
где Внимательный
слушатель может заметить, что не при любых смещениях
Чтобы избежать
такого эффекта, значение функции
где ЗаключениеИтак, на последних занятиях мы познакомились с принципами формирования хороших хэш-функций, которые минимизируют вероятность коллизий. Рассмотрели метод универсального хэширования, который минимизирует вероятность образования длинных цепочек в хэш-таблицах при попытке подобрать проблемный набор ключей. Узнали о втором способе хранения данных в массиве по методу открытой адресации и разобрали способы разрешения коллизий в таких хэш-таблицах, в частности, с помощью метода двойного хэширования. Как видите, реализации хэш-таблиц могут быть самыми разными. Начиная от способа хранения данных в таблице, выбора хэш-функции и заканчивая методами разрешения коллизий. Многое здесь зависит от прикладной задачи и от предпочтений и опыта разработчика. Поэтому нет какого-то единого алгоритма создания хэш-таблиц, в каждой задаче, в каждом языке программирования они могут быть реализованы по-разному. Но общий принцип их построения вы теперь знаете. Курс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Видео по теме |