|
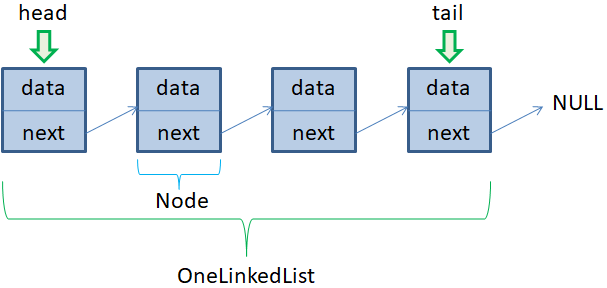
Делаем односвязный список на С++Курс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Мы продолжаем знакомиться с односвязными списками. На прошлом занятии мы в целом увидели структуру и основные операции с такими списками. На этом закрепим материал и реализуем односвязные списки на языке С++. В стандартной библиотеке С++ уже есть готовая реализация односвязных списков: std::forward_list а также стеки и очереди, которые основаны на таких списках, но это уже несколько другие структуры данных и о них мы еще будем говорить. Однако, на этом занятии мы с нуля создадим односвязный список на С++. Почему я выбрал именно этот язык? На мой взгляд, он очень хорошо подходит, для демонстрации всех нюансов создания и работы с объектами в памяти компьютера. А потому, мы сможем буквально заглянуть «под капот» односвязного списка, сделанного на С++. Вначале я напомню его общую структуру. У нас имеется набор объектов, в которых хранятся некоторые данные (data) и ссылка next на следующий объект. Если next равен NULL, то следующего объекта нет и это конец списка.
Отдельный объект этого списка мы определим через класс Node, а работу со списком в целом – через класс OneLinkedList. Вначале объявим класс Node следующим образом: class Node { public: double data; Node* next; public: Node(double data) { this->data = data; this->next = NULL; } }; Каждый объект этого класса будет иметь две публичные переменные: data – хранимое вещественное значение; next – указатель на следующий объект класса Node. Также имеется конструктор Node с одним параметром data и в момент создания объекта сохраняется переданное значение data, а указатель next принимает значение NULL. Далее объявим класс OneLinkedList, который будет управлять работой односвязного списка: class OneLinkedList { public: Node* head, * tail; public: OneLinkedList() { this->head = this->tail = NULL; } ~OneLinkedList() { while (head != NULL) pop_front(); } }; В нем определены указатели head и tail на первый и последний объекты списка, а также конструктор с деструктором. В конструкторе мы инициализируем указатели head и tail значением NULL, т.к. изначально список пустой, а в деструкторе выполняем удаление всех элементов списка (освобождаем память, которую они занимают). Давайте сразу пропишем метод pop_front(), который удаляет первый элемент односвязного списка. Как мы с вами говорили, сначала нужно переместить указатель head на следующий элемент, а затем, освободить память первого элемента: void pop_front() { if (head == NULL) return; if (head == tail) { delete tail; head = tail = NULL; return; } Node* node = head; head = node->next; delete node; } Вначале мы проверяем, есть ли вообще элементы в связном списке, и если их нет, то выполняется команда return, которая завершает метод. Далее, идет проверка, что в списке всего один элемент. Тогда указатели head и tail приравниваются значению NULL и освобождается память из под первого элемента. Если же в списке более одного элемента, то выполняем перемещение указателя head на следующий элемент и освобождаем память первого элемента. Следующий метод push_back() служит для добавления элемента в конец односвязного списка. Делается это достаточно просто: void push_back(double data) { Node* node = new Node(data); if (head == NULL) head = node; if (tail != NULL) tail->next = node; tail = node; } Параметр data содержит число, которое сохраняется в добавляемом элементе. Затем, создается сам элемент в памяти компьютера и на него ведет указатель node. После этого делаем проверку, если добавляется первый элемент, то указатель head должен ссылаться на этот объект. Следующая проверка, если tail ссылается на существующий объект, то указатель next этого объекта должен вести на добавляемый. В конце мы перемещаем указатель tail в конец списка, т.е. присваиваем ему значение node. Похожим образом работает метод добавления элемента в начало списка: void push_front(double data) { Node* node = new Node(data); node->next = head; head = node; if (tail == NULL) tail = node; } Здесь data – по-прежнему параметр, содержащий вещественное число для сохранения его в добавляемом элементе. Затем, создается новый объект списка. Указатель next этого объекта должен вести на объект head. После этого указатель head перемещаем на начало списка и еще проверяем, если добавляется первый элемент в список (tail равен NULL), то tail должен быть равен node. Следующий метод pop_back() выполняет удаление последнего элемента односвязного списка: void pop_back() { if (tail == NULL) return; if (head == tail) { delete tail; head = tail = NULL; return; } Node* node = head; for (; node->next != tail; node = node->next); node->next = NULL; delete tail; tail = node; } Вначале делаем проверку на наличие последнего элемента. Если его нет, то метод завершается. Далее, если в списке всего один элемент, то освобождаем из под него память и указатели head и tail приравниваем NULL. Если же в списке более одного элемента, то с помощью цикла for переходим к предпоследнему, устанавливаем у него указатель next на значение NULL, освобождаем память из под последнего элемента и указатель tail присваиваем значение node – адрес последнего элемента. Следующий метод getAt() возвращает указатель на элемент с индексом k: Node* getAt(int k) { if (k < 0) return NULL; Node* node = head; int n = 0; while (node && n != k && node->next) { node = node->next; n++; } return (n == k) ? node : NULL; } Если значение k меньше нуля, то возвращается NULL, т.к. такого индекса не существует. Далее, создаем временный указатель node, который изначально равен указателю head. Также создается счетчик n для индексов. Запускается цикл, в котором проверяем, существует ли объект node и если да, то дополнительно проверяем, чтобы n было не равно k и указатель next текущего объекта был не равен NULL. То есть, если будет найден элемент с индексом k, то цикл завершится. Также цикл завершится если будет достигнут конец списка. В конце возвращаем либо адрес найденного элемента, если n равно k, либо значение NULL, если объект с указанным индексом отсутствует в списке. Следующий метод insert() выполняет вставку элемента в односвязный список: void insert(int k, double data) { Node* left = getAt(k); if (left == NULL) return; Node* right = left->next; Node* node = new Node(data); left->next = node; node->next = right; if (right == NULL) tail = node; } При его вызове мы указываем индекс элемента, после которого предполагается вставить новый элемент, и значение data, которое сохраняется в новом элементе. Вначале получаем адрес элемента с индексом k с помощью метода getAt(). Если такого объекта нет, то метод insert() завершает свою работу. Иначе через указатель right сохраняем адрес следующего после left объекта, создаем новый объект Node с данными data. Указатель next объекта left приравниваем node, а у node next приравниваем right. В итоге настраиваем все необходимые связи односвязного списка. В конце делаем проверку, если right равен NULL, то вставляется последний элемент (в конец списка), значит, нужно переместить указатель tail в конец, т.е. присвоить ему значение node. Последний метод erase() удаляет элемент с индексом k из односвязного списка: void erase(int k) { if (k < 0) return; if (k == 0) { pop_front(); return; } Node* left = getAt(k - 1); Node* node = left->next; if (node == NULL) return; Node* right = node->next; left->next = right; if (node == tail) tail = left; delete node; } Вначале проверяем корректность индекса, если он отрицателен, то метод завершает свою работу. Если k равен нулю, то удаляется первый элемент, а для этого уже есть метод pop_front(). Его мы и вызываем. В противном случае, получаем указатель на k-1 элемент. Затем, указатель node указывает на k-й удаляемый элемент. Если он не существует, то метод erase() завершает свою работу. Иначе формируем еще один указатель right на объект после удаляемого. Далее, указатель next должен ссылаться на right и в конце проверка, если удаляется последний элемент, то tail нужно перевести на предпоследний. В конце освобождаем память из под удаляемого элемента. Все, мы с вами описали все основные методы для работы с односвязным списком. Давайте теперь протестируем его работу. Для этого в функции main() создадим объект класса OneLinkedList и запишем в него несколько элементов с помощью методов push_front() и push_back(): int main() { OneLinkedList lst; lst.push_front(1); lst.push_back(2); Node* n = lst.getAt(0); double d = (n != NULL) ? n->data : 0; std::cout << d << std::endl; lst.erase(1); lst.insert(0, 5); lst.insert(0, 2); lst.pop_back(); for (Node* node = lst.head; node != NULL; node = node->next) { std::cout << node->data << " "; } std::cout << std::endl; return 0; } Далее, возьмем объект по индексу 0 и выведем значение data на экран монитора. Причем, сделаем проверку, если объект не существует, то data будет равна 0. После этого удалим элемент с индексом 1, вставим элемент с индексом 0 и еще раз повторим эту же операцию. Удалим последний элемент. И, наконец, с помощью цикла for выведем значения всех элементов в консоль. Если все было сделано верно, то мы должны увидеть на экране соответствующие значения элементов односвязного списка lst. Вот пример того, как можно реализовать на С++ односвязный список. Надеюсь, из этого занятия вы лучше поняли его структуру и принцип работы основных команд. Курс по структурам данных: https://stepik.org/a/134212?utm_source=proproprogs Видео по теме |