|
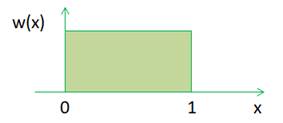
Модуль random стандартной библиотекиКурс по Python: https://stepik.org/course/100707?utm_source=proproprogs На этом занятии речь пойдет о модуле random стандартной библиотеки. Еще раз отмечу, что в Python имеется множество предустановленных модулей, которые поставляются вместе с интерпретатором языка. Подробно обо всех их можно почитать на странице официальной документации: https://docs.python.org/3/library/index.html Здесь много разных модулей и, программируя на Python, вы так или иначе будете с ними знакомиться. Среди них есть и модуль random. Откроем страницу с его описанием и видим здесь множество различных функций для генерации случайных значений (а точнее, псевдослучайных, то есть, их, все же можно просчитать). Я расскажу о некоторых из функций этого модуля, которые наиболее часто используются на практике. Вначале, для использования этого модуля, его нужно импортировать. Как это делать мы с вами уже подробно говорили. В самом простом случае, можно записать: import random И, далее, из пространства имен random можно выбирать самые разные функции этого модуля. Вначале я воспользуюсь функцией random(): a = random.random() print(a) Она при каждом вызове выдает случайное значение в диапазоне [0.0; 1.0). Обратите внимание, что числа подчиняются равномерному закону распределения, то есть, в диапазоне [0.0; 1.0) они могут принимать любое значение с равной вероятностью.
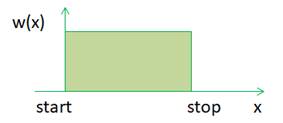
Другая похожая функция uniform(a, b) также генерирует случайные значения по равномерному закону, но в диапазоне от a до b: a = random.uniform(1, 5) Если нам нужно моделировать целочисленные случайные значения с тем же равномерным распределением, то можно использовать или функцию: a = random.randint(-3, 7) # [-3; 7] или функцию randrange: a = random.randrange(5) b = random.randrange(-3, 10, 2)
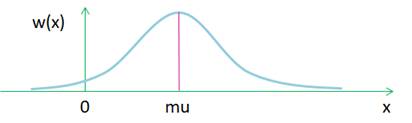
Однако часто на практике требуются случайные величины с другим законом распределения – гауссовским (или, еще говорят, нормальным). Закон распределения имеет следующий вид и определяется двумя параметрами: математическим ожиданием (средним значением) и среднеквадратическим отклонением (мерой разброса относительно МО).
Особенность этих величин в том, что они чаще появляются в области МО и реже на более дальних расстояниях. Ценность этого распределения в том, что ему часто подчиняются многие реальные события: колебания цен на нефть, и различных товаров, шумы при радиопередачах, погрешности измерений различных значений и т.п. Это распределение окружает нас повсюду! И, конечно же, нужно уметь его моделировать. Для этого в Python существует функция gauss(mu, sigma): a = random.gauss(0, 3.5) Во второй части этого занятия я расскажу о функциях модуля random при работе с последовательностями. Предположим, у нас имеется список: lst = [4, 5, 0, -1, 10, 76, 3] и мы хотим выбрать из него один элемент случайным образом. Для этого можно воспользоваться функцией: a = random.choice(lst) print(a) После запуска видим случайно выбранное значение из списка lst. Следующая функция shuffle() перемешивает элементы списка случайным образом: random.shuffle(lst) print(lst) Причем, меняет сам список, поэтому работает только с изменяемыми коллекциями. Третья функция sample() возвращает новый список с указанным числом неповторяющихся элементов, выбранных случайным образом из списка: a = random.sample(lst, 3) print(a) Разумеется, максимальное число элементов не может превышать число элементов в списке lst. И последнее, что я хочу отметить в работе с псевдослучайными величинами, это возможность формировать одинаковые случайные последовательности чисел при каждом новом запуске программы. О чем здесь речь? Смотрите, если мы, например, генерируем несколько целочисленных случайных величин: a = [random.randint(0, 10) for i in range(20)] print(a) То, запуская программу снова и снова, будем видеть разные случайные значения в списке a. Часто именно так и должен работать генератор случайных величин. Но иногда требуется, чтобы каждый запуск программы приводил к одной и той же последовательности случайных чисел. Например, для повторяемости результатов экспериментов на разных компьютерах. Для этого нужно зафиксировать, так называемое, зерно генератора случайных чисел с помощью функции seed(), следующим образом: random.seed(123) Здесь число 123 – это, как раз и есть значение зерна. Оно задает начальное состояние датчика чисел, поэтому, запуская программу, каждый раз будем видеть одни и те же случайные числа в списке a. Если выбрать другое значение зерна, то изменится и последовательность СВ. Это бывает очень удобно, не сохраняя последовательность случайных чисел, указывать только значение зерна для их генератора. Вот такие возможности существуют в библиотеке random, которые следует знать и, по мере необходимости, применять на практике. Курс по Python: https://stepik.org/course/100707?utm_source=proproprogs Видео по теме |