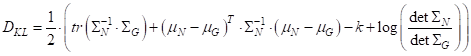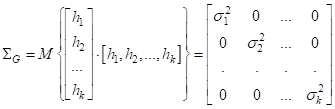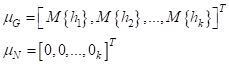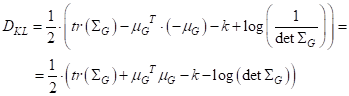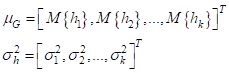|
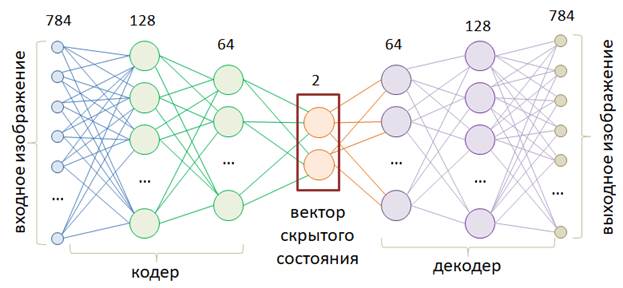
Вариационные автоэнкодеры (VAE)Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущем занятии мы с вами познакомились с работой простого автоэнкодера, который воспроизводил изображения цифр по вектору скрытого состояния. Давайте теперь внимательнее посмотрим на область, которую формирует кодер при преобразовании таких изображений. Для этого воспользуемся простой полносвязной НС с двумя нейронами для описания вектора скрытого состояния:
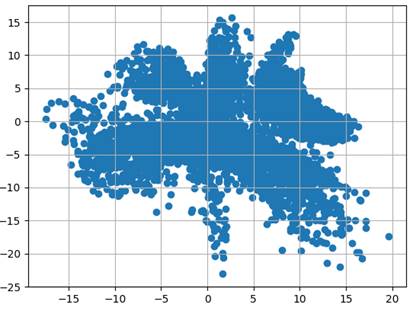
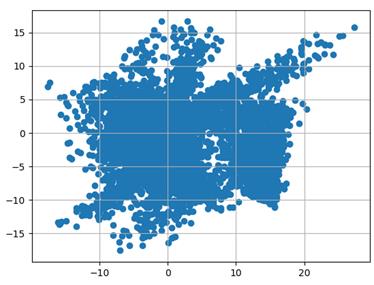
Модель автоэнкодера определим следующим образом: class AutoEncoderMNIST(nn.Module): def __init__(self, input_dim, output_dim, hidden_dim): super().__init__() self.hidden_dim = hidden_dim self.encoder = nn.Sequential( nn.Linear(input_dim, 128), nn.ELU(inplace=True), nn.Linear(128, 64), nn.ELU(inplace=True), nn.Linear(64, self.hidden_dim) ) self.decoder = nn.Sequential( nn.Linear(self.hidden_dim, 64), nn.ELU(inplace=True), nn.Linear(64, 128), nn.ELU(inplace=True), nn.Linear(128, output_dim), nn.Sigmoid() ) def forward(self, x): h = self.encoder(x) x = self.decoder(h) return x, h И обучим ее стандартным образом, так, как мы это делали на предыдущем занятии. С сохранением результата в файле 'model_vae.tar': st = model.state_dict() torch.save(st, 'model_vae.tar') После этого переведем модель в режим эксплуатации и сформируем набор из всех тестовых данных: d_test = torchvision.datasets.MNIST(r'C:\datasets\mnist', download=True, train=False, transform=transforms) x_data = transforms(d_test.data).view(len(d_test), -1) А, затем, пропустим их только через кодер и отобразим в двумерном пространстве полученные значения векторов скрытого состояния: h = model.encoder(x_data) h = h.detach().numpy() plt.scatter(h[:, 0], h[:, 1]) plt.grid() plt.show() На графике увидим следующее распределение точек на выходе кодера для тестового набора изображений:
Это характерная картина формирования модельной области отображения входного сигнала в пространство скрытого состояния. Что из этого следует? Если мы будем брать точки в пределах сформированной области, то, скорее всего, на выходе декодера будут получаться осмысленные изображения цифр. Если же брать точку за пределами этой области, то очень вероятно получим какое-то неопределенное изображение. Например, для точки с координатами
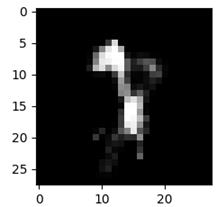
получим следующее изображение: h = torch.tensor([-40, -20], dtype=torch.float32) predict = model.decoder(h.unsqueeze(0)) predict = predict.detach().squeeze(0).view(28, 28) dec_img = predict.numpy() plt.imshow(dec_img, cmap='gray') plt.show()
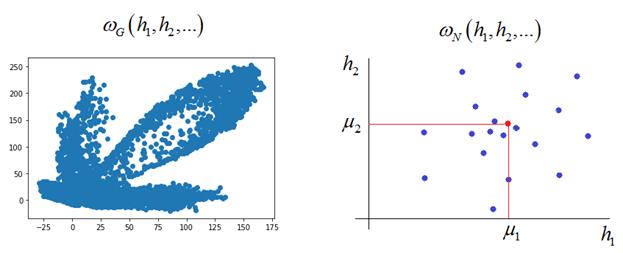
Напоминает смесь каких-то цифр и выглядит не очень. Из-за этого автоэнкодеры в чистом виде не практичны для генерации произвольных изображений. То есть, мы не можем брать произвольные точки в области скрытого состояния, чтобы гарантированно получать осмысленные изображения. Чтобы решить эту проблему пространство состояний скрытого вектора должно быть компактным и представлять единую цельную область без существенных разделений. Именно эту цель преследуют вариационные автоэнкодеры: Variational Autoencoders (VAE) Они пытаются сформировать область точек скрытого пространства в соответствии с заданным законом распределения. Часто выбирают нормальное (гауссовское) распределение, так как оно наиболее просто с вычислительной точки зрения, имеет понятную, приемлемую форму и полностью определяется двумя параметрами: математическое ожидание, дисперсия Например, в
случае двумерного вектора скрытого пространства
Такой подход даст нам уверенную надежду, что любая точка, взятая в пределах полученного распределения, будет давать на выходе декодера осмысленные, понятные изображения. То есть, мы будем понимать как выбирать точки в скрытом пространстве для генерации новых полноценных изображений. Это ключевое отличие вариационного автоэнкодера от обычных автоэнкодеров. Более того, эту же картину можно интерпретировать как преобразование входного пространства большей размерности в компактное скрытое пространство признаков меньшей размерности. Часто это упрощает дальнейший анализ исходных данных. Первый шаг, который мы можем сделать в направлении формирования компактного распределения векторов скрытого состояния – это добавить слои Batch Normalization после каждого полносвязного слоя в кодере: class AutoEncoderMNIST(nn.Module): def __init__(self, input_dim, output_dim, hidden_dim): super().__init__() self.hidden_dim = hidden_dim self.encoder = nn.Sequential( nn.Linear(input_dim, 128, bias=False), nn.ELU(inplace=True), nn.BatchNorm1d(128), nn.Linear(128, 64, bias=False), nn.ELU(inplace=True), nn.BatchNorm1d(64), nn.Linear(64, self.hidden_dim) ) ... В результате получим следующее распределение векторов h:
Уже лучше, однако, этот ход не гарантирует требуемое нам распределение. Поэтому далее мы сформулируем критерий и построим новую архитектуру автоэнкодера, который будет давать нужное нам распределение векторов скрытого состояния. Дивергенция Кульбака-ЛейблераИтак, у нас есть
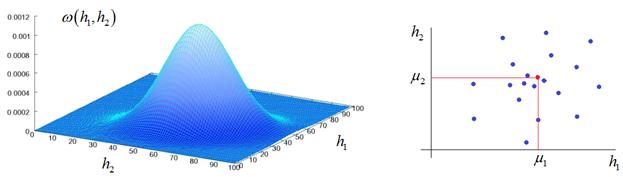
формируемое и желаемое распределения точек скрытого пространства. Обозначим их
через
Задачей
алгоритма обучения будет не только точно воспроизвести входной сигнал, но и
распределить точки скрытого пространства как можно ближе к распределению
то расстояние Кульбака-Лейблера для этого случая записывается относительно просто, по следующей формуле:
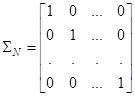
Здесь
Здесь по главной диагонали стоят дисперсии соответствующих величин. Вторую ковариационную матрицу желаемого распределения можно взять единичной:
Это будет означать, что многомерная гауссовская ПРВ будет иметь одинаковые дисперсии по всем направлениям (осям), равные 1. И вектор СВ состоит также из независимых величин. Выбор такой ковариационной матрицы очень удобен, т.к. мы сможем ее сократить в критерии качества Кульбака-Лейблера. Далее, векторы
Мы здесь для
желаемого нормального распределения МО всюду выбрали равные нулю. Это значит,
центр многомерного распределения
Если кто не знает
Итак, мера расхождения двух гауссовых ПРВ у нас есть. И эта мера зависит от векторов МО и дисперсии:
Но кодер на выходе выдает не эти величины, а непосредственно вектор скрытого состояния
Как же нам
вычислять МО и дисперсии текущего распределения и сделать так, чтобы алгоритм
обратного распространения ошибки мог использовать эту информацию при обучении VAE? Для этого
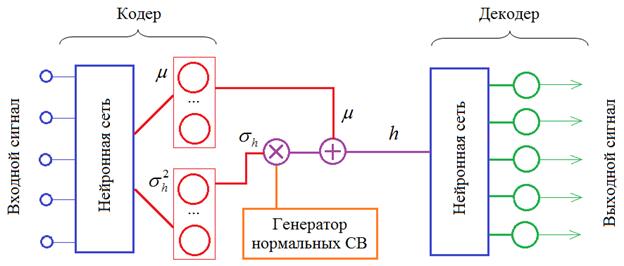
кодер будет формировать не сам вектор h, а векторы
Здесь генератор
НСВ выдает величины с нулевым вектором МО и единичными дисперсиями. Поэтому,
после поэлементного умножения на
То есть, в
процессе обучения нейроны кодера будут выдавать векторы МО и дисперсии для
каждого входного наблюдения
Законы физики «заставляют» ее течь по ложбинке, а не по возвышенностям. Также и при обучении НС: нейроны приобретают те признаки, которым легче обучиться. Структура вариационного автоэнкодера как раз способствует формированию МО и дисперсии на этих группах нейронов в процессе обучение автоэнкодера. Теперь, имея эти оценки, можно использовать меру Кульбака-Лейблера для определения соответствия текущего распределения заданному, а также еще один критерий для соответствия входного сигнала выходному. То есть, в процессе обучения VAE будут минимизироваться сразу два этих критерия. Первый будет способствовать формированию правильного распределения векторов h скрытого пространства. А второй – соответствию выходного сигнала входному. Здесь можно так же взять меру минимума среднего квадрата ошибок рассогласования:
где
На следующем занятии мы реализует этот вариационный автоэнкодер и посмотрим к каким результатам он приводит. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |