|
Тензоры. Индексирование и срезыКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии познакомимся со способами считывания и записи значений в тензоры PyTorch. В целом синтаксис очень похож на обращение к элементам списков языка Python. Давайте рассмотрим все на конкретных примерах. Предположим, что имеется одномерный тензор: a = torch.arange(12) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) И мы хотим прочитать отдельные его элементы. Это можно сделать путем обращения к нужному элементу тензора по индексу, например, так: a[2] # tensor(2) Если нам нужно конкретное значение, а не тензор, то можно дополнительно вызвать метод item: a[2].item() # 2
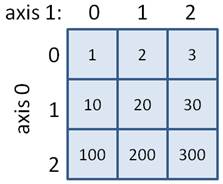
Помимо положительных индексов существуют еще и отрицательные, которые отсчитывают элементы с конца списка, например: a[-1] # последнее значение 11 a[-2] # предпоследнее значение 10 Если мы выходим за пределы тензора и указываем несуществующий индекс, то возникает исключение (ошибка): a[12] # ошибка, последний индекс 11 Соответственно, если нужно изменить значение какого-либо элемента, то ему просто присваивается это новое значение: a[0] = 100 # первый элемент равен 100 Как видите, здесь применяется тот же синтаксис, что и при работе с обычными списками Python. То же касается и срезов. Мы можем выделять и менять сразу группу элементов тензора. Общий синтаксис срезов выглядит так: <имя тензора>[start:stop:step] Давайте посмотрим примеры использования этой конструкции: b = a[2:4] # tensor([2, 3]) Здесь указан начальный индекс 2, конечный индекс 4 и по умолчанию берется шаг, равный 1. На выходе получаем массив из двух значений 2 и 3. Последний граничный индекс 4 не включается в срез. Обратите внимание, в PyTorch срезы возвращают новое представление того же самого тензора, то есть, данные, на которые ссылаются переменные a и b одни и те же. Мы в этом можем легко убедиться, выполнив команду: b[0] = -100 Это приводит к изменению соответствующего элемента тензора a: tensor([ 100, 1, -100, 3, 4, 5, 6, 7, 8, 9, 10, 11]) Поэтому срезы – это не копии тензоров, а лишь создание их нового представления. Это сделано специально для экономии памяти. Другие примеры срезов: a[3:] # tensor([ 3, 4, 5, 6, 7, 8, 9, 10, 11]) a[:5] # tensor([ 100, 1, -100, 3, 4]) a[-5: -1] # tensor([ 7, 8, 9, 10]) a[:] # tensor([ 100, 1, -100, 3, 4, 5, 6, 7, 8, 9, 10, 11]) a[1:6:2] # tensor([1, 3, 5]) a[::2] # tensor([ 100, -100, 4, 6, 8, 10]) a[::-1] # ошибка Я, думаю, общий принцип использования одномерных срезов понятен. Разумеется, срезам можно присваивать новые значения. Например, так: a[:4] = torch.IntTensor([-1, -2, -3, -4]) # tensor([-1, -2, -3, -4, 4, 5, 6, 7, 8, 9, 10, 11]) a[4::2] = torch.IntTensor([10, 20, 30, 40]) # tensor([-1, -2, -3, -4, 10, 5, 20, 7, 30, 9, 40, 11]) Индексация и срезы многомерных тензоровВ базовом варианте индексация и срезы многомерных тензоров работает так же как и в одномерных, только индексы указываются для каждой оси. Например, объявим двумерный тензор: x = torch.IntTensor([(1, 2, 3), (10, 20, 30), (100, 200, 300)])
Для обращения к центральному значению 20 нужно выбрать вторую строку и второй столбец, имеем: x[1, 1] # tensor(20, dtype=torch.int32) Чтобы взять последнюю строку и последний столбец, можно использовать отрицательные индексы: x[-1, -1] # tensor(300, dtype=torch.int32) Если же указать только один индекс, то получим строку: x[0] # tensor([1, 2, 3]) Эта запись эквивалентна следующей: x[0, :] # tensor([1, 2, 3]) То есть, не указывая какие-либо индексы, PyTorch автоматически подставляет вместо них полные срезы. Для извлечения столбцов мы уже должны явно указать полный срез в качестве первого индекса: x[:,1] # tensor([ 2, 20, 200]) У тензоров более высокой размерности картина индексации, в целом выглядит похожим образом. Например, создадим четырехмерный тензор: a = torch.arange(1, 82).view(3, 3, 3, 3) Тогда для обращения к конкретному элементу следует указывать четыре индекса: a[1, 2, 0, 1] # tensor(47) Для выделения многомерного среза, можно использовать такую запись: a[:, 1, :, :] # тензор 3x3x3 или, так: a[0, 0] # двумерный тензор 3x3 Это эквивалентно записи: a[0, 0, :, :] Если же нужно задать два последних индекса, то полные срезы у первых двух осей указывать обязательно: a[:, :, 1, 1] # тензор 3x3 a[0:2, 0:2, 1, 1] # тензор 2x2 Пакет PyTorch позволяет множество полных подряд идущих срезов заменять троеточиями. Например, вместо a[:, :, 1, 1] можно использовать запись: a[..., 1, 1] # эквивалент a[:, :, 1, 1] Это бывает удобно, когда у тензора много размерностей и нам нужны только последние индексы. Списочная индексацияПомимо указания у тензоров обычных индексов или срезов в PyTorch существует еще один способ индексирования – через списки или целочисленные тензоры. Чтобы лучше понять, о чем идет речь, рассмотрим этот механизм на примерах. Для простоты возьмем одномерный тензор с какими-нибудь значениями: a = torch.arange(1, 9) # tensor([1, 2, 3, 4, 5, 6, 7, 8]) Далее смотрите, если указать обычный числовой индекс, то получим одно значение соответствующего элемента: a[0] # tensor(1) Но, если вместо числового индекса указать список: b = a[[0]] # tensor([1]) то на выходе уже получим копию тензора из одного первого значения. То есть, выполняя операцию: b[0] = 100 изменение тензора b не приведет к изменению тензора a. А что будет, если в списке указать несколько индексов? Например, так: a[[0, 1, 7, 5]] # tensor([1, 2, 8, 6]) На выходе получаем новый тензор, состоящий из соответствующих значений. Или, можно сделать даже так: a[[0, 0, 1, 1, 1, 2, 3, 4, 5, 6, 7]] # tensor([1, 1, 2, 2, 2, 3, 4, 5, 6, 7, 8]) То есть, мы здесь имеем, фактически, способ формирования новых тензоров на основе других. В списке достаточно перечислить индексы нужных элементов и на выходе формируется тензор с соответствующими значениями. В ряде случаев такая операция бывает очень удобной. Кроме обычных списков языка Python мы можем использовать целочисленные или булевы тензоры, например, так: indx = torch.IntTensor([0, 0, 1, 1, 1, 2]) a[indx] # tensor([1, 1, 2, 2, 2, 3]) bIndx = torch.BoolTensor([True, True, False, False, False, True, False, False]) a[bIndx] # tensor([1, 2, 6]) В результате остаются только те элементы, которым соответствуют индексы True. Причем, длина тензора bIndx должна совпадать с длиной тензора a, иначе произойдет ошибка. Последний вариант списочной индексации используется очень часто. Например, мы можем сформировать тензор индексов путем какой-либо булевой операции над тензором, например: i = a > 5 # tensor([False, False, False, False, False, True, True, True]) А, затем, использовать его, чтобы оставить только нужные элементы: a[i] # tensor([6, 7, 8]) Или, все это можно записать короче в одну строчку: a[a > 5] # tensor([6, 7, 8]) Как видите, это невероятно удобный механизм обработки тензоров в PyTorch. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |