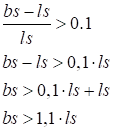|
Сохранение и загрузка моделей. Функции torch.save() и torch.load()Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs С помощью фреймворка PyTorch можно создавать довольно крупные НС, которые, как правило, обучаются длительное время. Соответственно, встает вопрос сохранения обученных моделей на диск и их последующая загрузка. Давайте посмотрим, как это делается на примере ранее созданной модели распознавания изображений цифр: neuro_net_21.py: https://github.com/selfedu-rus/neuro-pytorch Если непосредственно после создания модели: model = DigitNN(28 * 28, 32, 10) вызвать метод state_dict: st = model.state_dict() То переменная st будет ссылаться на словарь состояний модели model. В данном случае он будет иметь вид: st = {OrderedDict: 4} OrderedDict(
То есть, содержать веса связей и смещений (biases) текущей модели. Затем, все эти данные (словарь) можно сохранить на диске с помощью функции save фреймворка PyTorch: torch.save(st, 'model_dnn.tar') В результате в текущем каталоге появится архивный файл 'model_dnn.tar' с сохраненными весами связей. Эти данные могут быть загружены в любую НС с такой же структурой, и она станет распознавать изображения цифр, как это делала сохраненная модель. Для этого вначале вызывается функция load: state_model = torch.load('model_dnn.tar', weights_only=True) Параметр weights_only=True означает, что выполняется загрузка примитивных типов данных, например: словарей, тензоров, списков, строк и т.п. В данном случае мы используем словарь. После загрузки словарь состояний state_model передается в любую подходящую модель (той же архитектуры): model.load_state_dict(state_model) Вот общий принцип записи данных в файл и их последующей загрузки. Причем сохранять можно вообще произвольные данные. Например, создадим тензор: tf = torch.tensor([1, 2, 3]) и сохраним его: torch.save(tf, "ex.tar") Выполним загрузку данных из этого же файла: t = torch.load("ex.tar", weights_only=True) и видим, что t – это такой же тензор, что и tf. То есть, функция load() сразу возвращает объект ранее сохраненного типа. Как пример, создадим строку: s = "hello" и также сохраним ее в файл: torch.save(s, "ex.tar") После загрузки: t = torch.load("ex.tar", weights_only=True) видим, что t – это строка с соответствующим содержимым. И так можно делать со всеми стандартными типами данных. Однако при работе с тензорами и моделями НС есть один важный нюанс. Если тензор изначально расположен на графическом процессоре: device = torch.device("cuda" if torch.cuda.is_available() else "cpu") tf = torch.tensor([1, 2, 3], device=device) То при его сохранении и последующей загрузке: torch.save(tf, "ex.tar") t = torch.load("ex.tar", weights_only=True) Тензор t также окажется на GPU. Если нам нужно другое или вполне определенное его расположение, то дополнительно это можно указать через параметр map_location, например, так: t = torch.load("ex.tar", weights_only=True, map_location="cpu") Теперь тензор t будет расположен на CPU. Иногда такое явное указание типа устройства бывает очень полезным. Сохранение состояния модели в процессе обученияИтак, как в целом выполнять сохранение и загрузку тензоров, словарей и других встроенных типов данных, мы с вами разобрались. Все это применяется не только для сохранения полностью обученных моделей, но и для формирования контрольных точек в процессе самого обучения, когда обучение затягивается на дни или даже месяцы. Как вы понимаете, при длительной работе программ могут происходить самые разные непредвиденные ситуации, из-за которых процесс обучения может прерваться. И начинать все заново было бы очень неприятно. Поэтому на практике формируют промежуточные контрольные точки (check point) с текущими весами модели. Если происходит непредвиденная остановка, то достаточно загрузить сохраненную модель и продолжить процесс обучения. Давайте рассмотрим пример того, как это можно было бы сделать. Перед главным циклом обучения введем вспомогательную переменную: best_loss = 1e10 # заведомо высокое значение А в самом цикле на каждой эпохе будем сравнивать превышение значения best_loss над значением средних потерь loss_mean на 10% для определения значимых улучшений: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: ... if best_loss > loss_mean * 1.1: best_loss = loss_mean st = model.state_dict() torch.save(st, f'model_dnn_{_e}.tar') Выражение best_loss > loss_mean * 1.1 математически можно получить следующим образом:
Если теперь на текущей эпохе предыдущие потери окажутся на 10% выше, чем текущие средние, то формируется контрольная точка (сохраняются веса модели). Соответственно, файл с самым большим номером будет содержать лучшие значения весов связей. Конечно, величина 10% взята с позиции здравого смысла. Это не какое-то строгое значение. Вполне можно выбрать 15%, 20% или даже 5% в зависимости от протекания процесса обучения и решаемой задачи. Сохранение и загрузка дополнительных объектовПомимо модели НС сохранять в файле можно и некоторые другие объекты фреймворка PyTorch. Как это делается с тензорами, вы уже видели. Но помимо них аналогичные операции допустимо выполнять с объектом трансформации, оптимизатором. Например, сформируем следующий общий словарь состояния модели: model_state_dict = { 'tfs': transforms.state_dict(), 'opt': optimizer.state_dict(), 'model': model.state_dict(), } И будем сохранять его в главном цикле обучения: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: ... if best_loss > loss_mean * 1.1: best_loss = loss_mean model_state_dict['model'] = model.state_dict() torch.save(model_state_dict, f'model_dnn_{_e}.tar') После обучения (например, в другом модуле) загрузим эти данные: model_data = torch.load('model_dnn_1.tar', weights_only=True) model.load_state_dict(model_data['model']) transforms.load_state_dict(model_data['tfs']) optimizer.load_state_dict(model_data['opt']) В результате мы сохранили, а затем, загрузили данные по модели, преобразованиям и оптимизатору. Как видите, все достаточно просто и удобно. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |