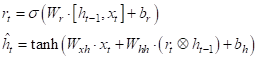|
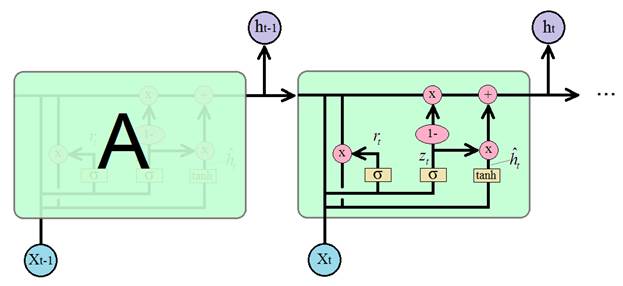
Рекуррентный блок GRUКурс по нейронным сетям: https://stepik.org/a/227582 На предыдущих занятиях мы с вами познакомились с рекуррентной архитектурой LSTM-блока. Она эффективна при анализе долгосрочного контента, но имеет и существенный недостаток – большое число настраиваемых параметров (весовых коэффициентов). Это приводит к большим затратам памяти и длительному процессу обучения таких сетей. Поэтому в 2014 году было предложено упрощение LSTM, которое стало известно под названием управляемые рекуррентные блоки: Gated Recurrent Units (GRU) По эффективности блоки GRU сравнимы с LSTM во многих практических задачах: моделирования музыкальных и речевых сигналов, обработка текста и так далее. Существует несколько вариантов этого блока и, как всегда, мы рассмотрим их классическую, базовую архитектуру:
Работа этого
блока (ячейки) похожа на блок LSTM, только здесь долгосрочный элемент
памяти объединен с вектором скрытого состояния
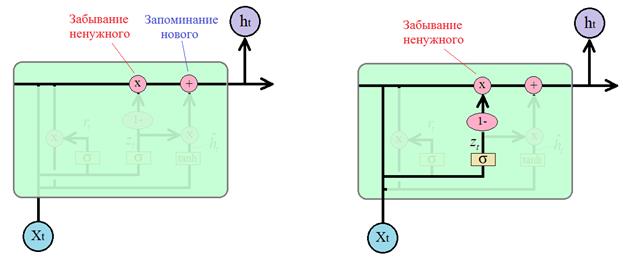
Для определения что забыть, а что оставить, используется вектор
который, затем,
поэлементно вычитается из 1 и умножается на вектор предыдущего состояния
Почему мы здесь делаем это вычитание? Чтобы противоположную информацию использовать как маркер для добавления нового в соседней ветке. Если ее полностью расписать, то получится следующая операция:
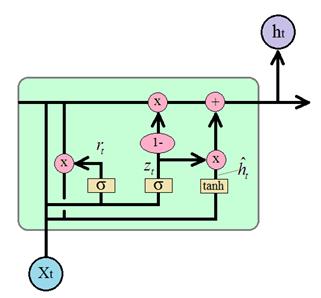
И вычисленная
величина добавляется как то, что нужно «запомнить» в векторе скрытого состояния
для следующей итерации. В итоге, вычисление
Эта формула и определяет принцип работы ячейки GRU. Если кто из вас знаком с калмановской фильтрацией случайных сигналов, то полученная формула очень похожа на реализацию фильтра Калмана, только в нелинейном исполнении. В некотором смысле она работает по этому же принципу: отбрасывает случайные (незначительные) детали и сохраняет главное (важное). Какую же сеть LSTM или GRU выбирать для практического применения? Все зависит от поставленной задачи, но общая рекомендация такая: сначала лучше воспользоваться сетью GRU, так как она быстрее обучается и если точность решения задачи оказывается недостаточной, то есть смысл попробовать сеть LSTM. Общим преимуществом сетей LSTM и GRU является решение проблемы исчезающего градиента, характерная для простейшей рекуррентной НС, когда при увеличении числа итераций величина градиента стремится к нулю. В LSTM и GRU благодаря сохранению долгосрочного контента градиент перестает быстро затухать в процессе обучения. Одним из общих недостатков блоков LSTM и GRU является их большая склонность к переобучению. Так как каждая ячейка содержит большое число нейронов, то сеть, на их основе также получается большой. А это, как мы знаем, прямой путь к переобучению. Чтобы этого избежать, во-первых, нужно контролировать эффект переобучения по выборке валидации. И, во-вторых, применять инструменты: Dropout и Batch Normalization Причем, в PyTorch Dropout можно использовать и для внутренних слоев в блоке, используя параметр:
По умолчанию этот параметр равен нулю, то есть, dropout отключен. Инструмент Batch Normalization используется только между слоями (внутри ячеек он не применяется). Использование блока GRU в PyTorchДавайте посмотрим, как можно создавать и использовать такие блок GRU в PyTorch. Чтобы создать GRU-слой следует воспользоваться классом: torch.nn.GRU который принимает те же параметры, что и ранее рассмотренный класс LSTM:
Для примера давайте создадим такой слой и пропустим через него тензор x размерностью: (batch_size, sq_length, d_size) import torch import torch.nn as nn rnn = nn.GRU(10, 20, batch_first=True) x = torch.randn(7, 3, 10) # (batch_size, sq_length, d_size) y, h = rnn(x) print('y:', y.size()) print('h:', h.size()) В консоли увидим строчки: y: torch.Size([7, 3, 20])
Если же слой будет двунаправленным: rnn = nn.GRU(10, 20, batch_first=True, bidirectional=True) то тензоры y, h будут иметь размеры: y:
torch.Size([7, 3, 40])
Как видите, здесь все работает по аналогии с RNN-слоем. В качестве рабочего примера давайте в программе прогноза слов заменим RNN-слой на GRU и посмотрим, что получится. Класс модели в этом случае будет иметь вид: class WordsRNN(nn.Module): def __init__(self, in_features, out_features): super().__init__() self.hidden_size = 64 self.in_features = in_features self.out_features = out_features self.rnn = nn.GRU(in_features, self.hidden_size, batch_first=True) self.out = nn.Linear(self.hidden_size, out_features) def forward(self, x): x, h = self.rnn(x) y = self.out(h) return y После 20 эпох обучения, получим: подумал встал и снова лег тем другим шутя и думать о форме плана и как Вот принцип работы GRU-блока и пример его использования во фреймворке PyTorch. Курс по нейронным сетям: https://stepik.org/a/227582 Видео по теме |