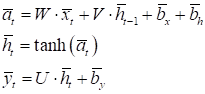|
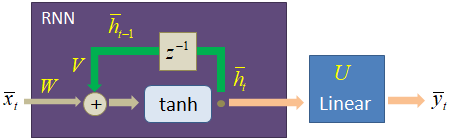
Рекуррентная сеть для прогноза символовКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs У нас с вами все готово для непосредственной реализации нейронной сети, которая будет строить прогнозы символов. Модель сети будет иметь следующую структуру:
А ее работа определяться следующими формулами:
То есть, здесь добавился еще один полносвязный слой после рекуррентного слоя. На уровне фреймворка PyTorch эту модель можно описать с помощью следующего класса: class TextRNN(nn.Module): def __init__(self, in_features, out_features): super().__init__() self.hidden_size = 64 self.in_features = in_features self.out_features = out_features self.rnn = nn.RNN(in_features, self.hidden_size, batch_first=True) self.out = nn.Linear(self.hidden_size, out_features) def forward(self, x): x, h = self.rnn(x) y = self.out(h) return y В инициализаторе модели через параметр in_features будет передаваться размер используемого алфавита (словаря); через параметр out_features – число прогнозируемых символов (число выходов с последнего полносвязного слоя). В самом классе фиксируется размер вектора скрытого состояния, равным 64. Затем, создаются два слоя: рекуррентный и полносвязный. В методе forward описывается порядок обработки входного тензора x, размеры которого: (batch_size, sq_length, x_data) Он последовательно пропускается через два слоя, между которыми нет никакой функции активации, так как тензор h уже пропущен через гиперболический тангенс и сразу же его пропускать через другую нелинейную функцию особого смысла нет. На выходе тензор y будет иметь размерность: (1, batch_size, x_data) Класс CharsDataset формирования обучающей выборкиСледующим шагом объявим класс с именем CharsDataset для формирования обучающей выборки. На предыдущем занятии мы с вами подробно рассмотрели формат входных данных и теперь согласно ему создадим обучающий набор. Класс CharsDataset будет иметь следующий вид: class CharsDataset(data.Dataset): def __init__(self, path, prev_chars=3): self.prev_chars = prev_chars with open(path, 'r', encoding='utf-8') as f: self.text = f.read() self.text = self.text.replace('\ufeff', '') # убираем первый невидимый символ self.text = re.sub(r'[^А-яA-z0-9.,?;: ]', '', self.text) # заменяем все неразрешенные символы на пустые символы self.text = self.text.lower() self.alphabet = set(self.text) self.int_to_alpha = dict(enumerate(sorted(self.alphabet))) self.alpha_to_int = {b: a for a, b in self.int_to_alpha.items()} self.num_characters = len(self.alphabet) self.onehots = torch.eye(self.num_characters) def __getitem__(self, item): _data = torch.vstack([self.onehots[self.alpha_to_int[self.text[x]]] for x in range(item, item+self.prev_chars)]) ch = self.text[item+self.prev_chars] t = self.alpha_to_int[ch] return _data, t def __len__(self): return len(self.text) - 1 - self.prev_chars В методе __init__ передается путь к текстовому файлу и число символов, на основе которых будет выполняться прогноз следующего символа. Затем, читается файл целиком, в котором оставляются только указанные символы. Все остальные будут удалены. Текст переводится в нижний регистр для уменьшения размера алфавита и, как следствие, упрощение работы нейронной сети. После этого, на основе полученной текстовой строки, выделяются уникальные символы, которые и образуют алфавит (словарь). На основе этого упорядоченного набора формируется два словаря:
Эти коллекции нам впоследствии понадобятся при формировании One-hot векторов и прогнозов. Далее, запоминаем общее количество символов в полученном алфавите и формируем набор one-hot векторов. В методе __getitem__ должны вернуть один образ выборки по индексу item. Для этого с помощью генератора списков формируем набор one-hot векторов с подаваемыми prev_chars символами и объединяем их в единый тензор с помощью функции torch.vstack. В переменной ch сохраняем следующий (целевой) символ и с помощью коллекции self.alpha_to_int получаем его порядковый номер. В результате имеем набор входных данных _data и целевого значения t, которые возвращаем в виде кортежа. Магический метод __len__ возвращает общий размер обучающей выборки, вычисленный как размер текстовой строки за вычетом последнего прогнозного символа и длины подаваемой на вход последовательности. Обучение рекуррентной нейронной сетиТеперь мы можем приступить непосредственно к обучению нашей модели рекуррентной нейронной сети. Вначале сформируем объекты для работы с выборкой: d_train = CharsDataset("train_data_true", prev_chars=10) train_data = data.DataLoader(d_train, batch_size=8, shuffle=False) Я решил не перемешивать выборку, чтобы текстовые фрагменты следовали строго друг за другом. Хотя вполне можно и перемешать. На корректности обучения это не скажется, т.к. каждый образ выборки содержит все предыдущие символы и целевое значение, которое следует спрогнозировать. Далее определим саму модель с размером входных данных, равным размеру алфавита и выходными данными того же размера: model = TextRNN(d_train.num_characters, d_train.num_characters) После этого зададим оптимизатор, функцию потерь в виде перекрестной кросс-энтропии, т.к. решается задача многоклассовой классификации, число эпох и переведем модель в режим обучения: optimizer = optim.Adam(params=model.parameters(), lr=0.001) loss_func = nn.CrossEntropyLoss() epochs = 100 model.train() Затем, знакомый нам главный цикл обучения: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: predict = model(x_train).squeeze(0) loss = loss_func(predict, y_train.long()) optimizer.zero_grad() loss.backward() optimizer.step() lm_count += 1 loss_mean = 1/lm_count * loss.item() + (1 - 1/lm_count) * loss_mean train_tqdm.set_description(f"Epoch [{_e+1}/{epochs}], loss_mean={loss_mean:.3f}") В целом, он здесь записан в неизменном виде, единственное, мы передаем в функцию потерь одно число – порядковый номер прогнозируемого символа. Это вполне допустимо делать, т.к. оно будет автоматически преобразовано к one-hot вектору. Сохраним обученную модель: st = model.state_dict() torch.save(st, 'model_rnn_1.tar') Переведем ее в режим эксплуатации и выполним прогноз символов: model.eval() predict = "Мой дядя самых".lower() total = 40 for _ in range(total): _data = torch.vstack([d_train.onehots[d_train.alpha_to_int[predict[-x]]] for x in range(d_train.prev_chars, 0, -1)]) p = model(_data.unsqueeze(0)).squeeze(0) indx = torch.argmax(p, dim=1) predict += d_train.int_to_alpha[indx.item()] print(predict) В качестве начальной фразы здесь записано "Мой дядя самых", а дальше будет прогнозироваться total = 40 символов. В цикле формируется набор входных данных _data ровно так, как это мы делали в классе CharsDataset. Данные подаются на вход модели и на выходе получаем тензор p размерностью: (1, x_data) С помощью функции torch.argmax определяем индекс наибольшего значения и выбираем соответствующий ему символ из словаря int_to_alpha, который добавляем в конец строки predict. Далее, этот спрогнозированный символ будет использоваться наряду с остальными в качестве основы для прогноза следующего символа. После запуска этой программы, модель обучится за 100 эпох и выдаст следующий результат: мой дядя самых опредде, что.тымо мочто в игскитай, тол Не особо вразумительно, но и не совсем безумно. Сеть действительно пытается что-то уловить в данных и сделать прогноз. Конечно, это всего лишь учебный пример, показывающий каким образом можно формировать обучающую выборку и тензоры для подачи входных данных. Также подробно мы с вами изучили работу рекуррентного слоя и его реализацию на PyTorch. И, наконец, попробовали обучить рекуррентную нейронную сеть. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |