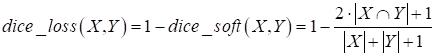|
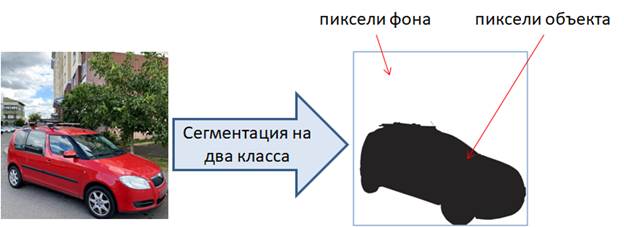
Реализация U-Net для семантической сегментации изображенийКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии мы с вами реализуем сеть U-Net, с которой подробно познакомились на предыдущем занятии, для задачи бинарной сегментации автомобилей на изображении.
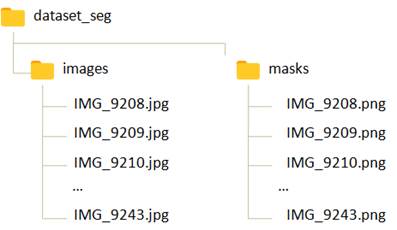
Для этого воспользуемся уже подготовленной выборкой следующей структуры:
В папке images располагаются полноцветные изображения 512x512 пикселей каждое, в которых присутствуют автомобили разных марок. А в папке masks цветные изображения масок автомобилей. Пиксели фона соответствуют белому цвету, а различные части автомобиля – своими отдельными цветами. Названия файлов исходных изображений и масок совпадают. Для работы с этой выборкой в PyTorch определим следующий класс: class SegmentDataset(data.Dataset): def __init__(self, path, transform_img=None, transform_mask=None): self.path = path self.transform_img = transform_img self.transform_mask = transform_mask path = os.path.join(self.path, 'images') list_files = os.listdir(path) self.length = len(list_files) self.images = list(map(lambda _x: os.path.join(path, _x), list_files)) path = os.path.join(self.path, 'masks') list_files = os.listdir(path) self.masks = list(map(lambda _x: os.path.join(path, _x), list_files)) def __getitem__(self, item): path_img, path_mask = self.images[item], self.masks[item] img = Image.open(path_img).convert('RGB') mask = Image.open(path_mask).convert('L') # grayscale if self.transform_img: img = self.transform_img(img) if self.transform_mask: mask = self.transform_mask(mask) mask[mask < 250] = 1 mask[mask >= 250] = 0 return img, mask def __len__(self): return self.length В инициализатор класса SegmentDataset передается путь к корневому каталогу dataset_reg и трансформации отдельно для изображений и масок. Далее, с помощью функции os.listdir() формируется список из файлов изображений, который затем сохраняется в свойстве images в виде списка с полными путями к изображениям. То же самое выполняется для папки masks, только результат сохраняется в свойстве masks. Метод __getitem__ возвращает объект выборки по указанному индексу item. Для этого извлекаются пути к соответствующему файлу изображения и маски. Затем, изображения загружаются, причем первое остается в формате RGB, а маску преобразовываем в градации серого, т.к. нам нужно будет только разделение на фон и пиксели автомобиля. Это преобразование делается после применения трансформации к маске. Команда: mask[mask < 250] = 1 присваивает единицы всем пикселям, значения которых меньше 250 (пиксели объекта автомобиля), а команда: mask[mask >= 250] = 0 присваивает 0 всем пикселям со значением больше или равным 250. Это пиксели фона. В результате тензор mask будет содержать либо значения 1, относящиеся к автомобилю, либо значения 0, относящиеся к фону. В конце метод __getitem__ возвращает пару (изображение, маска). Последний магический метод __len__ просто возвращает размер выборки. В результате получаем класс SegmentDataset для работы с выборкой бинарной сегментации автомобилей на изображениях. Описание модели U-Net на PyTorchСледующим шагом объявим модель U-Net в соответствии со структурой, рассмотренной на предыдущем занятии. Пусть класс называется UNetModel и наследуется от базового класса Module фреймворка PyTorch: class UNetModel(nn.Module): ... Внутри этого класса объявим вспомогательную модель, реализующую два подряд идущих сверточных слоя. Она нам пригодится, т.к. в модели U-Net много таких блоков. Чтобы каждый раз их не прописывать целиком, мы это сделаем через вспомогательный вложенный класс _TwoConvLayers: class UNetModel(nn.Module): class _TwoConvLayers(nn.Module): def __init__(self, in_channels, out_channels): super().__init__() self.model = nn.Sequential( nn.Conv2d(in_channels, out_channels, 3, padding=1, bias=False), nn.ReLU(inplace=True), nn.BatchNorm2d(out_channels), nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False), nn.ReLU(inplace=True), nn.BatchNorm2d(out_channels), ) def forward(self, x): return self.model(x)
Содержимое вложенного класса вам уже должно быть понятно. В инициализаторе будем указывать число входных и выходных каналов, затем обязательно следует вызвать инициализатор базового класса и следом я определил последовательную модель из двух сверточных слоев с функцией активации ReLU и слоем BatchNorm2d после каждого из них. Ровно в соответствии с приведенной структурой сети U-Net. Метод forward определяет алгоритм обработки входного тензора и в данном случае он просто пропускается через последовательность двух сверточных слоев. Далее, блоки с двумя свертками и слоем MaxPooling я также опишу отдельным вложенным классом, чтобы не реализовывать каждый из них отдельно: class UNetModel(nn.Module): ... class _EncoderBlock(nn.Module): def __init__(self, in_channels, out_channels): super().__init__() self.block = UNetModel._TwoConvLayers(in_channels, out_channels) self.max_pool = nn.MaxPool2d(2) def forward(self, x): x = self.block(x) y = self.max_pool(x) return y, x
В инициализаторе класса _EncoderBlock создаются два сверточных слоя с ReLU и Batch Normalization согласно модели только что описанного класса _TwoConvLayers. И еще один слой MaxPool2d с ядром 2x2 и шагом stride=2. В методе forward входной тензор последовательно пропускается через модель _TwoConvLayers и слой MaxPool2d. При этом выходное значение с выходного слоя двух сверток сохраняется в переменной x, а выход со слоя MaxPool2d – в переменной y. Обе эти переменные (тензоры) возвращаются методом forward в виде кортежа (y, x). В дальнейшем нам понадобятся оба этих значения при реализации связей skip connections в сети U-Net. Наконец, в представленной архитектуре U-Net имеются четыре одинаковых по структуре блока при восстановлении сигнала (формировании маски):
Опишем их с помощью вложенного класса _DecoderBlock: class UNetModel(nn.Module): ... class _DecoderBlock(nn.Module): def __init__(self, in_channels, out_channels): super().__init__() self.transpose = nn.ConvTranspose2d(in_channels, out_channels, 2, stride=2) self.block = UNetModel._TwoConvLayers(in_channels, out_channels) def forward(self, x, y): x = self.transpose(x) u = torch.cat([x, y], dim=1) u = self.block(u) return u В инициализаторе регистрируем слой ConvTranspose2d, модель TwoConvLayers с двумя подряд идущими сверточными слоями и слой MaxPool2d. Затем, в методе forward, который принимает два тензора x, y (см. рисунок), сигнал x подается на слой ConvTranspose2d, а затем, результат объединяется с тензором y, переданным по skip connection. Причем объединение происходит по второй оси – по каналам (dim=1). Результат объединения пропускается через два сверточных слоя и формируется выходное значение. Все вспомогательные модели мы с вами описали, теперь можно воспользоваться ими для определения архитектуры сети U-Net целиком. Для этого в инициализаторе класса UNetModel создадим (зарегистрируем) все необходимые блоки и слои следующим образом: class UNetModel(nn.Module): ... def __init__(self, in_channels=3, num_classes=1): super().__init__() self.enc_block1 = self._EncoderBlock(in_channels, 64) self.enc_block2 = self._EncoderBlock(64, 128) self.enc_block3 = self._EncoderBlock(128, 256) self.enc_block4 = self._EncoderBlock(256, 512) self.bottleneck = self._TwoConvLayers(512, 1024) self.dec_block1 = self._DecoderBlock(1024, 512) self.dec_block2 = self._DecoderBlock(512, 256) self.dec_block3 = self._DecoderBlock(256, 128) self.dec_block4 = self._DecoderBlock(128, 64) self.out = nn.Conv2d(64, num_classes, 1) Параметр in_channels определяет число каналов входных изображений. Так как планируется подавать полноцветные RGB-изображения, то in_channels равен трем. Параметр num_classes – число выходных каналов для маски. Мы решаем задачу бинарной сегментации, поэтому достаточно одного выходного канала. Далее последовательно создаются четыре блока _EncoderBlock со сверточными слоями и MaxPool2d, затем два сверточных слоя с 1024 каналами, которые расположены в основании модели U-Net. После этого еще четыре блока _DecoderBlock для формирования итоговой маски. Последним идет сверточный слой с числом выходных каналов и ядром 1x1. Метод forward сети U-Net последовательно пропускает входное изображение по объявленным блокам и формирует выходной тензор – результат сегментации: class UNetModel(nn.Module): ... def forward(self, x): x, y1 = self.enc_block1(x) x, y2 = self.enc_block2(x) x, y3 = self.enc_block3(x) x, y4 = self.enc_block4(x) x = self.bottleneck(x) x = self.dec_block1(x, y4) x = self.dec_block2(x, y3) x = self.dec_block3(x, y2) x = self.dec_block4(x, y1) return self.out(x) Dice coefficient - критерий качества сегментации изображенийПосле описания модели U-Net ее следует обучить по сформированной выборке. Но вначале следует определиться с критерием качества, который будет использоваться в процессе обучения. Так как решается задача бинарной сегментации, то логично было бы воспользоваться уже знакомой нам функцией потерь бинарной кросс-энтропией: loss_1 = nn.BCEWithLogitsLoss() Однако она хорошо подходит для сбалансированных классов. В нашем же случае площадь объекта на изображении может быть много меньше остального фона, а значит, классы могут быть сильно не сбалансированными. В связи с этим в задачах сегментации применяется еще один критерий под названием dice coefficient, который математически можно записать в виде:
где X – результат сегментации сетью U-Net; Y – целевая маска (требуемый тензор). В числителе записывается количество совпадающих значений между множествами X и Y (точками выделяемых объектов), умноженное на 2, а в знаменателе – суммарный размер множеств X и Y, то есть, количество точек, относящихся к объектам. Итоговую функцию потерь можно записать следующим образом:
Единица в числителе и знаменателе добавлена, чтобы исключить деление на ноль и точные граничные значения 0 и 1 функции dice_loss, чтобы улучшить сходимость градиентного алгоритма. В программе мы реализуем эту функцию в виде отдельного класса: class SoftDiceLoss(nn.Module): def __init__(self, smooth=1): super().__init__() self.smooth = smooth def forward(self, logits, targets): num = targets.size(0) probs = nn.functional.sigmoid(logits) m1 = probs.view(num, -1) m2 = targets.view(num, -1) intersection = (m1 * m2) score = 2 * (intersection.sum(1) + self.smooth) / (m1.sum(1) + m2.sum(1) + self.smooth) score = 1 - score.sum() / num return score В методе forward тензор logits – это результат формирования маски сетью U-Net. Так как последний слой не содержит функции активации, то мы применяем функцию sigmoid к выходам этой сети, чтобы интерпретировать результаты в терминах вероятности отнесения пиксела к фону или объекту. Значение меньше 0,5 означает фон, а большее – объект. Далее, вытягиваем тензоры по батчам и вычисляем умножение целевого тензора на результирующий. Напомню, что в целевом тензоре у нас только два возможных значения: 0 и 1. Поэтому при умножении будут выделяться только результаты пересечения пикселей объектов. Также при суммировании целевого тензора будет подсчитываться количество пикселей, относящихся только к объекту (пиксели фона равны нулю). В результате, функция потерь будет тем меньше, чем точнее выходной тензор будет описывать целевой. Обучение сети U-NetТеперь у нас все готово, чтобы обучить сеть U-Net и оценить качество ее работы. Вначале запишем преобразования, которые будут применяться к загружаемым изображениям и маскам: tr_img = tfs_v2.Compose([tfs_v2.ToImage(), tfs_v2.ToDtype(torch.float32, scale=True)]) tr_mask = tfs_v2.Compose([tfs_v2.ToImage(), tfs_v2.ToDtype(torch.float32)]) Затем, сформируем обучающую выборку и саму модель: d_train = SegmentDataset(r"dataset_seg", transform_img=tr_img, transform_mask=tr_mask) train_data = data.DataLoader(d_train, batch_size=2, shuffle=True) model = UNetModel() После этого зададим оптимизатор, два вида функций потерь, число эпох и переведем модель в режим обучения: optimizer = optim.RMSprop(params=model.parameters(), lr=0.001) loss_1 = nn.BCEWithLogitsLoss() loss_2 = SoftDiceLoss() epochs = 10 model.train() Ниже запишем уже знакомый нам цикл обучения нейронной сети: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: predict = model(x_train) loss = loss_1(predict, y_train) + loss_2(predict, y_train) optimizer.zero_grad() loss.backward() optimizer.step() lm_count += 1 loss_mean = 1/lm_count * loss.item() + (1 - 1/lm_count) * loss_mean train_tqdm.set_description(f"Epoch [{_e+1}/{epochs}], loss_mean={loss_mean:.3f}") Здесь все абсолютно стандартно, кроме вычисления функции потерь. Она складывается из двух функций loss_1 и loss2, то есть, минимизируется и бинарная кросс-энтропия и максимизируется коэффициент dice. После обучения сохраним коэффициенты модели: st = model.state_dict() torch.save(st, 'model_unet_seg.tar') И выполним тестирование ее работы на подготовленном изображении с машиной: img = Image.open(r"car_1.jpg").convert('RGB') img = tr_img(img).unsqueeze(0) p = model(img).squeeze(0) x = nn.functional.sigmoid(p.permute(1, 2, 0)) x = x.detach().numpy() * 255 x = np.clip(x, 0, 255).astype('uint8') plt.imshow(x, cmap='gray') plt.show() После обучения в консоли увидим результаты по десяти эпохам: Epoch [1/10],
loss_mean=1.457:
100%|██████████|
10/10 [01:48<00:00, 10.89s/it]
И следующий результат сегментации изображения, не участвующего в обучении:
Конечно, не самый лучший результат, но это исключительно учебный пример, в котором использовалась весьма ограниченная выборка в 20 изображений и всего 10 эпох обучения. Кроме того, сама структура сети U-Net может быть значительно улучшена за счет встраивания в нее предобученных глубоких сетей, например, ResNet или VGG. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |



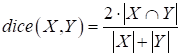 ,
,