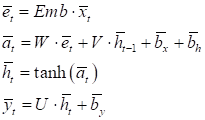|
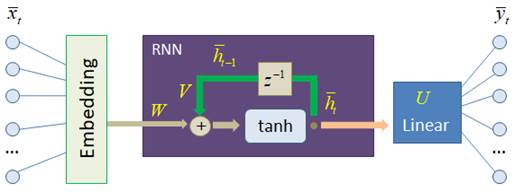
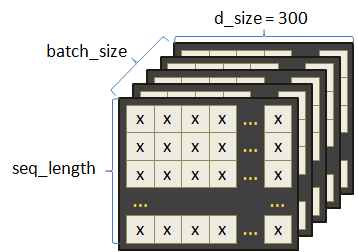
Прогноз слов рекуррентной нейронной сетьюКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии мы с вами создадим и обучим рекуррентную нейронную сеть для построения прогнозов слов. На вход рекуррентного слоя будут подаваться эмбеддинги слов, а на выходе в линейном слое число нейронов будет равно размеру словаря:
По наибольшему выходному значению будет определяться порядковый номер прогнозируемого слова. Задача, в целом, аналогична прогнозу символов, только вместо отдельных букв здесь подаются слова. Embedding-слой в PyTorchКонечно, фреймворк PyTorch уже содержит класс nn.Embedding, с помощью которого можно формировать Embedding-слои. Он имеет следующие основные параметры:
И, по сути, реализует обычный полносвязный слой без смещений (bias):
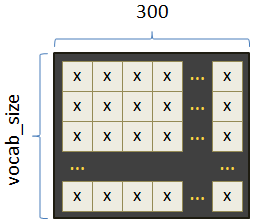
Весовые коэффициенты этой сети и есть embedding-векторы, которые хранятся в матрице:
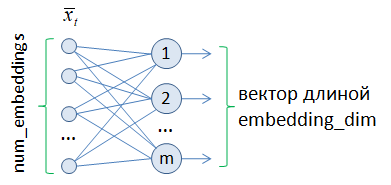
На вход embedding-слоя предполагается подавать целое число – порядковый номер объекта (например, слова или символа), а на выходе выдается его векторное представление. Во фреймворке PyTorch воспользоваться классом nn.Embedding можно следующим образом. Вначале создается объект этого класса с указанием входной и выходной размерностей, например: embedding = nn.Embedding(10, 4) А, затем, подать на вход этого слоя тензор типа long: h = torch.tensor([1], dtype=torch.long) vect = embedding(h) Переменная vect будет ссылаться на embedding-вектор. Как видите, все достаточно просто. Применение обученного Embedding-слояКонечно, создавая таким образом embedding-слой, он будет выдавать векторы со случайными значениями, так как является необученным. Мы же будем применять обученный вариант этого слоя для слов русского языка с длиной каждого embedding-вектора в 300 элементов:
Но откуда мы возьмем эти векторы? На просторах интернета можно найти обученные векторные представления слов. В частности, по ссылке: https://github.com/natasha/natasha можно перейти на страницу проекта «Наташа», который посвящен обработке естественного русского языка. Здесь же в описании сказано, что для его использования нужно выполнить установку этого пакета с помощью команды: pip install natasha Далее, в самом низу этой страницы есть ссылки на отдельные модули этого пакета. Нас интересует модуль Navec, отвечающий за embedding: https://github.com/natasha/navec На этой странице есть уже готовые сформированные модели в файлах:
Мы воспользуемся первым из них и скачаем на свой компьютер в рабочий каталог проекта. Ниже на странице показано, как можно использовать этот модуль в своем проекте. Вначале загружается обученная модель: from navec import Navec path = 'navec_hudlit_v1_12B_500K_300d_100q.tar' navec = Navec.load(path) А, затем, можно получить embedding-вектор почти любого русского слова: vec = navec['машина'] Также можно проверить наличие слова в словаре: 'машина' in navec и получить порядковый номер слова в словаре navec: indx = navec.vocab['автомобиль'] Как видите, пользоваться модулем Navec очень просто и удобно. Класс WordsDataset формирования обучающей выборкиСледующим шагом объявим класс с именем WordsDataset для формирования обучающей выборки. В целом, формат входных данных будет иметь тот же вид, что и при прогнозировании символов, только теперь в строках будут не one-hot векторы, а embedding-векторы с выхода модуля Navec:
Класс WordsDataset будет иметь следующий вид: class WordsDataset(data.Dataset): def __init__(self, path, navec_emb, prev_words=3): self.prev_words = prev_words self.navec_emb = navec_emb with open(path, 'r', encoding='utf-8') as f: self.text = f.read() self.text = self.text.replace('\ufeff', '') # убираем первый невидимый символ self.text = self.text.replace('\n', ' ') self.text = re.sub(r'[^А-яA-z- ]', '', self.text) # удаляем все неразрешенные символы self.words = self.text.lower().split() self.words = [word for word in self.words if word in self.navec_emb] # оставляем слова, которые есть в словаре vocab = set(self.words) self.int_to_word = dict(enumerate((vocab))) self.word_to_int = {b: a for a, b in self.int_to_word.items()} self.vocab_size = len(vocab) def __getitem__(self, item): _data = torch.vstack([torch.tensor(self.navec_emb[self.words[x]]) for x in range(item, item+self.prev_words)]) word = self.words[item+self.prev_words] t = self.word_to_int[word] return _data, t def __len__(self): return len(self.words) - 1 - self.prev_words В инициализатор класса передается путь к файлу с обучающим текстом, объект класса Navec и число слов, по которым будет делаться прогноз (по умолчанию три). В самом инициализаторе читается текстовый файл, из него удаляются все неинформативные символы, полученная строка переводится в нижний регистр и разделяется по пробелам. На выходе получаем список слов self.words. В этом списке оставляем только те слова, которые есть в словаре Navec. После этого формируем свой словарь self.vocab из уникальных слов и два вспомогательных словаря:
В переменной self.vocab_size сохраняем общий размер словаря. Следующий метод __getitem__ возвращает набор embedding-векторов слов, по которым делается прогноз и порядковый номер прогнозируемого слова. Здесь все по аналогии с программой прогноза символов. С помощью функции torch.vstack объединяются embedding-тензоры слов в единый набор – тензор _data. Далее, в переменной t сохраняется порядковый номер целевого (прогнозируемого) слова. Обе переменные _data и t возвращаются в виде кортежа. Последний метод __len__ возвращает объем обучающей выборки за вычетом прогнозного слова и предыдущих self.prev_words слов, по которым деляется прогноз. Класс WordsRNN модели рекуррентной сетиСледующим шагом объявим класс модели без отдельного embedding-слоя, так как он у нас уже реализован в виде объекта класса Navec и на вход рекуррентного слоя сразу будут подаваться embedding-векторы слов: class WordsRNN(nn.Module): def __init__(self, in_features, out_features): super().__init__() self.hidden_size = 256 self.in_features = in_features self.out_features = out_features self.rnn = nn.RNN(in_features, self.hidden_size, batch_first=True) self.out = nn.Linear(self.hidden_size, out_features) def forward(self, x): x, h = self.rnn(x) y = self.out(h) return y В этом классе модели все практически так же, как и в предыдущей модели прогноза символов. Обучение рекуррентной моделиТеперь все готово для формирования обучающей выборки, модели и ее обучения. Вначале сформируем объект класса Navec, который отвечает за формирование embedding-векторов слов: path = 'navec_hudlit_v1_12B_500K_300d_100q.tar' navec = Navec.load(path) Обратите внимание, здесь использован файл navec_hudlit_v1_12B_500K_300d_100q.tar, который должен быть предварительно скачан в рабочий каталог проекта. Далее сформируем объекты обучающей выборки и создадим модель: d_train = WordsDataset("text_2", navec, prev_words=3) train_data = data.DataLoader(d_train, batch_size=8, shuffle=False) model = WordsRNN(300, d_train.vocab_size) В качестве текстового файла для обучения использован заготовленный файл text_2, который можно скачать по ссылке: text_2: https://github.com/selfedu-rus/neuro-pytorch Затем объявим оптимизатор, функцию потерь кросс-энтропия, т.к. решается задача многоклассовой классификации, установим число эпох 20 и переведем модель в режим обучения: optimizer = optim.Adam(params=model.parameters(), lr=0.001, weight_decay=0.0001) loss_func = nn.CrossEntropyLoss() epochs = 20 model.train() Обратите внимание на параметр weight_decay=0.0001 оптимизатора Adam. Напомню, что он служит для «включения» L2-регуляризатора с целью уменьшения эффекта переобучения модели. Наконец, запишем главный цикл обучения: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: predict = model(x_train).squeeze(0) loss = loss_func(predict, y_train.long()) optimizer.zero_grad() loss.backward() optimizer.step() lm_count += 1 loss_mean = 1/lm_count * loss.item() + (1 - 1/lm_count) * loss_mean train_tqdm.set_description(f"Epoch [{_e+1}/{epochs}], loss_mean={loss_mean:.3f}") Здесь все стандартно и нет ничего нового. После обучения сохраним модель: st = model.state_dict() torch.save(st, 'model_rnn_words.tar') И выполним прогноз десяти слов: model.eval() predict = "подумал встал и снова лег".lower().split() total = 10 for _ in range(total): _data = torch.vstack([torch.tensor(d_train.navec_emb[predict[-x]]) for x in range(d_train.prev_words, 0, -1)]) p = model(_data.unsqueeze(0)).squeeze(0) indx = torch.argmax(p, dim=1) predict.append(d_train.int_to_word[indx.item()]) print(" ".join(predict)) После запуска программы модель выдаст следующий текст: подумал встал и снова лег вс и тихо и очень рад что прежний путь переменил Получилось довольно оригинально. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |