|
Применение классов Dataset и DataloaderКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Давайте представим, что у нас имеется следующая организация выборки изображений рукописных цифр:
https://github.com/selfedu-rus/neuro-pytorch/blob/main/dataset.rar Я ее сформировал из стандартной БД MNIST с помощью следующего скрипта: https://github.com/selfedu-rus/neuro-pytorch/blob/main/dataset_class_gen.py В подкаталогах class_0, class_1 и так далее располагаются изображения цифр размером 28 x 28 пикселей в градациях серого (один цветовой канал). Вот примеры этих изображений разных классов:
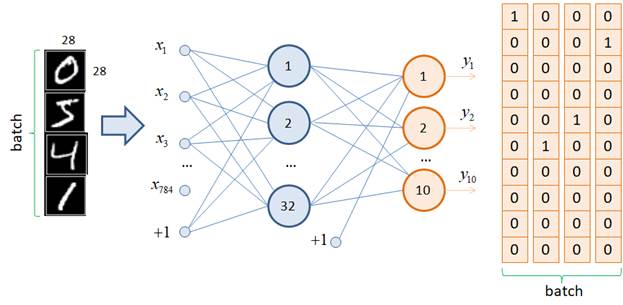
Наша задача обучить полносвязную нейронную сеть прямого распространения классифицировать эти изображения. Сама сеть, для примера, будет иметь следующую структуру:
На ее вход будет подаваться тензор размерностью: (batch_size, 784) То есть, все
изображения размером 28 x 28 пикселей вытягиваются в одномерный
тензор, состоящий из 784 = 28 * 28 элементов. На выходе сеть имеет 10 нейронов
с выходами 0: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 5: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0] 4: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0] 1: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] Возможно, у вас здесь возникает вопрос. А почему бы на выходе сети оставить только один нейрон, который будет выдавать числа от 0 до 9 – метки классов. Причина в том, что нейронной сети проще распределять классы по отдельным выходным нейронам, чем в виде одного числа. Поэтому в задачах многоклассовой классификации, как правило, на последнем слое столько нейронов, сколько классов следует определять. Реализация класса DatasetИтак, формат входных и выходных данных мы с вами определили. Давайте теперь опишем реализацию класса Dataset, который бы выдавал такие данные. Первым делом пропишем необходимые импорты: import os import json from PIL import Image import torch import torch.utils.data as data import torchvision.transforms.v2 as tfs По ходу изложения вам будет понятно назначение каждого из них. Следом сформируем свой собственный класс с именем DigitDataset, унаследованный от стандартного класса Dataset: class DigitDataset(data.Dataset): def __init__(self, path, train=True, transform=None): self.path = os.path.join(path, "train" if train else "test") self.transform = transform with open(os.path.join(path, "format.json"), "r") as fp: self.format = json.load(fp) self.length = 0 # размер выборки self.files = [] # список с информацией о файлах изображений self.targets = torch.eye(10) for _dir, _target in self.format.items(): path = os.path.join(self.path, _dir) list_files = os.listdir(path) self.length += len(list_files) self.files.extend(map(lambda _x: (os.path.join(path, _x), _target), list_files)) def __getitem__(self, item): path_file, target = self.files[item] t = self.targets[target] img = Image.open(path_file) return img, t def __len__(self): return self.length В инициализатор через параметр path передается путь к корневой папке dataset с файлами изображений выборки; параметр train определяет тип выборки (обучающая или тестовая); последний параметр transform будет содержать возможные трансформации для изображений. Пока пусть он принимает значение None. Затем, в локальном свойстве self.path сохраняется маршрут до папок с классами изображений (class_0, class_1, …), а в переменной self.transform – объект с возможными преобразованиями (пока значение None). Далее, из указанного каталога читается файл format.json и его содержимое преобразуется в словарь с сохранением в переменной self.format. В цикле перебираются элементы этого словаря и выполняется подсчет числа файлов в каталогах. А в список self.files добавляются кортежи в формате: (путь к файлу изображения, класс изображения) После этого формируем наборы тензоров для всех возможных меток классов в виде one-hot векторов и сохраняем в переменной self.targets. На этом инициализация объекта класса DigitDataset завершается. Все созданные переменные впоследствии используются в двух последующих магических методах. В методе __getitem__ по индексу item извлекаются путь к файлу и его метка. Затем, определяется требуемый выходной тензор t и выполняется непосредственно загрузка изображения. То есть, до момента запроса конкретного образа из выборки, изображение хранится на диске и только когда оно потребовалось, происходит его загрузка в память. В результате в памяти в один момент времени хранятся лишь несколько образов из всей выборки. Это позволяет использовать огромные объемы обучающих данных, при разумных затратах оперативной памяти устройства. После того, как изображение загружено, возвращается кортеж в формате: (изображение, целевое значение) Второй магический метод __len__ очень прост. Он возвращает ранее вычисленное значение self.length, то есть, размер всей выборки. Давайте посмотрим, как можно воспользоваться этим классом. Создадим объект командой: d_train = DigitDataset("dataset") Здесь "dataset" – это каталог с определенной структурой папок и файлов. После этого выполним следующие команды: img, target = d_train[10] length = len(d_train) Должны получить изображение PIL с целевым выходным тензором и длину length в 60000 образов. Использование класса DataloaderОднако на вход нейронной сети нам нужно подавать не по одному образу, а сразу пакет (batch) образов, да еще и выбранных в случайном порядке. Как мы уже знаем, для этой роли разработан класс Dataloader фреймворка PyTorch. Воспользуемся им следующим образом: train_data = data.DataLoader(d_train, batch_size=32, shuffle=True) Мы связали его с набором данных d_train, указали размер batch в 32 элемента с перемешиванием (shuffle=True). Попробуем получить первый батч через объект-генератор train_data: it = iter(train_data) x, y = next(it) И при выполнении функции next получим ошибку. В батч тензора PyTorch объекты PIL не могут быть занесены. Предварительно их нужно преобразовать (трансформировать) в тензоры. Как раз здесь нам понадобится параметр transform, который был заранее прописан в инициализаторе. Первым делом из ветки: torchvision.transforms.v2 возьмем класс ToImage, который специально разработан для этой цели, и создадим его объект: to_tensor = tfs.ToImage() # PILToTensor (альтернатива) Далее, при создании объекта d_train укажем этот тип преобразования: d_train = DigitDataset("dataset", transform=to_tensor) И в методе __getitem__ класса DigitDataset добавим две строчки: def __getitem__(self, item): path_file, target = self.files[item] t = self.targets[target] img = Image.open(path_file) if self.transform: img = self.transform(img).ravel().float() / 255.0 return img, t Обратите внимание, после перевода изображения в тензор дополнительно вызывается метод ravel(), который вытягивает все изображение 28 x 28 пикселей в одну строку размером 784 элемента. Затем преобразуем все значения к типу float32 и нормируем значения в диапазон [0; 1]. Такая нормировка часто улучшает качество и скорость обучения НС. Именно в таком формате мы будем подавать изображения на вход нейронной сети. Если теперь повторить команды: it = iter(train_data) x, y = next(it) то переменная x будет являться тензором размерностью: (32, 784) а переменная y с размерностью: (32, 10) Мало того, если посмотреть на содержимое тензора y: tensor([[0., 0., 0., 0., 0., 0., 0.,
1., 0., 0.],
то увидим разные метки классов, что говорит о случайном наборе выбранных данных. Конечно, те из вас, кто хорошо знаком с PyTorch знают, что если нам нужна именно выборка MNIST, а не какая-то другая, произвольная, то сформировать объект Dataset для нее можно с помощью двух команд: mnist_train = torchvision.datasets.MNIST(r'C:\datasets\mnist', download=True, train=True) mnist_test = torchvision.datasets.MNIST(r'C:\datasets\mnist', download=True, train=False) А затем, на их основе сформировать объекты класса DataLoader: train_data = data.DataLoader(mnist_train, batch_size=32, shuffle=True) test_data = data.DataLoader(mnist_test, batch_size=500) Но мы исходим из того, что работаем не со стандартными выборками, а своими собственными, которые организованы в виде набора каталогов классов изображений. А MNIST был взят, как пример, чтобы не создавать свой набор из 60000 изображений. На следующем занятии воспользуемся полученной выборкой и обучим нейронную сеть классифицировать изображения цифр. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |