|
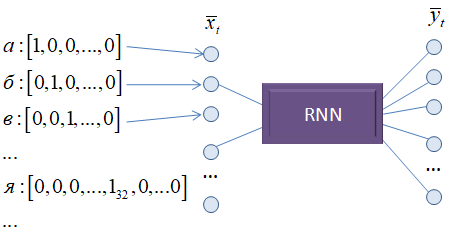
Понятие эмбеддинга. Embedding словКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На прошлом занятии мы построили рекуррентную нейронную сеть, которая пыталась делать прогноз следующего символа. При этом сами символы кодировались one-hot векторами:
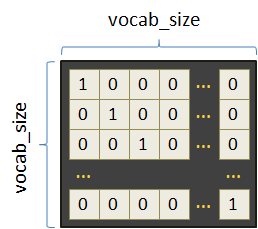
В результате в памяти приходилось хранить все эти векторы для каждого символа, то есть, таблицу размером vocab_size x vocab_size, где vocab_size – количество уникальных символов алфавита:
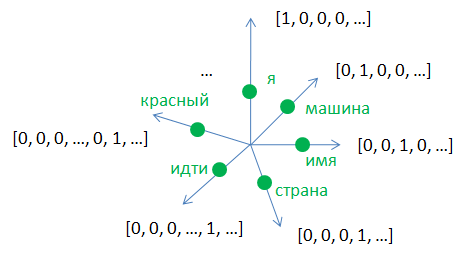
Все это не так критично, пока не касаемся слов и предложений. Количество уникальных символов, как правило, не велико. Но что если мы собираемся на вход сети подавать отдельные слова и делать прогноз следующего слова? В этом случае размер словаря vocab_size существенно возрастает. Да и само разреженное представление слов в виде one-hot векторов не особо информативно, т.к. оно не показывает взаимосвязи между словами. Каждый one-hot вектор можно воспринимать, как ортонормированную координатную ось многомерной системы координат размерностью vocab_size. А сами слова располагаются на расстоянии 1 от ее центра:
Тогда евклидово расстояние между любой пары слов будет равно:
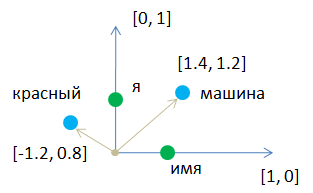
Как следствие, это расстояние ничего не говорит нам о близости любых двух слов, закодированных one-hot векторами. Было бы хорошо, с одной стороны, сократить размерность пространства и использовать его во всей полноте. А с другой стороны, повысить информативность векторного представления слов. Сократить размерность пространства vocab_size с сохранением уникального представления каждого слова, очевидно можно. Если мы для простоты рассмотрим двумерную систему координат с двумя one-hot векторами, то помимо двух слов «я» и «имя» на самих осях можно добавить произвольное число слов в пределах этого двумерного пространства:
Получаем более компактное представление слов произвольными двумерными векторами. Мало того, их теперь можно подобрать так, чтобы близкие по смыслу слова располагались рядом в этом пространстве и мы могли бы, например, по простой евклидовой метрике определять их семантическую (смысловую) близость. Произвольное векторное представление слов получило название embedding слов. Вообще эмбеддинг (embedding) – это векторное представление объекта, отражающий смысл этого объекта. В данном случае объектами являются отдельные слова. Но это может быть изображение, звук, последовательность ДНК и вообще любой прикладной объект. Поэтому сейчас подчеркивается, что мы говорим об эмбеддинге именно слов, а не чего то еще. Word2vecИтак, как же нам сформировать векторы заданного размера, располагающие близкие по смыслу слова рядом друг с другом? Это отдельная задача, которая имеет множество способов решений. Эти подходы объединяются под одним общим названием word2vec (слова в векторы). Один из первых подходов формирования компактного векторного представления слов известен еще до времен активного применения нейронных сетей. Брался реальный текст и для каждого центрального слова оценивался его контекст. Часто это были два предыдущих и два следующих слова:
В таблице для каждого центрального слова запоминалось число вхождений различных уникальных слов, попадающих в его контекст.
Полученные векторы уже лучше отражали близость слов, чем простое one-hot кодирование. Но размеры этих векторов все еще равны размеру словаря. Для сокращения их размеров и сохранения сформированной информации можно применить один из известных методов сокращения размерности, например, алгоритмы PCA (метод главных компонент) или SVD (сингулярное разложение матриц). Об этих методах мы с вами уже подробно говорили на курсе по машинному обучению. Оба позволяют сократить размерность векторов и приводят к примерно одинаковому результату. Word2vec нейронными сетямиКонечно, широкое использование нейронных сетей не обошло стороной и задачу эмбеддинга во всех ее проявлениях (от изображений, до обработки естественного языка). Вместо явного вычисления векторов слов, эту задачу возложили на нейронные сети. Один из самых простых и очевидных подходов заключается в следующем.
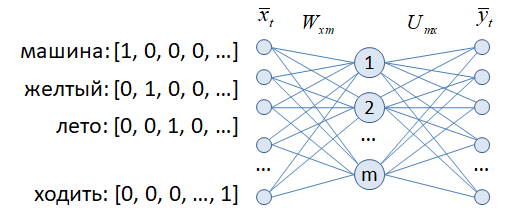
На вход обычной полносвязной НС подается слово, закодированное с помощью one-hot вектора. То есть, число входов соответствует размеру словаря. Далее, идет скрытый слой с линейной функцией активации, как правило, с много меньшим числом m нейронов, чем размер словаря. А затем, выходной слой по размерам в точности равный входному. При подаче очередного слова на выходе требуется получить все слова из его контекста. То есть, два предыдущих и два следующих после него слова. Причем, процесс обучения для каждого центрального слова выполняют следующим образом. Пусть в нашем примере подается слово «первых». Его контекст состоит из двух предыдущих слов «один», «из» и двух последующих «подходов», «формирования». Поэтому сначала обучаем его на получение первого слова из контекста «один», затем, на второе «из» и так по порядку для всех четырех слов. В результате сеть должна обучиться так, чтобы слова из контекста этого слова были наиболее вероятными (формировались наибольшие значения на соответствующих выходах сети). Такой подход обучения контекста по центральному слову получил название skip-gram. Существует и противоположный подход CBOW, когда делается прогноз центрального слова по его контексту. Оба метода приводят к примерно одинаковым результатам эмбеддинга. После обучения
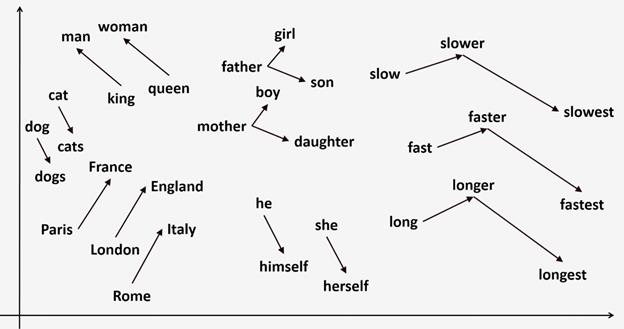
сети строки матрицы Вот пример одного из возможных embedding слов английского алфавита, представленный в двумерном пространстве (то есть, полученные векторы были уменьшены до двух с помощью одного из методов сокращения размерности):
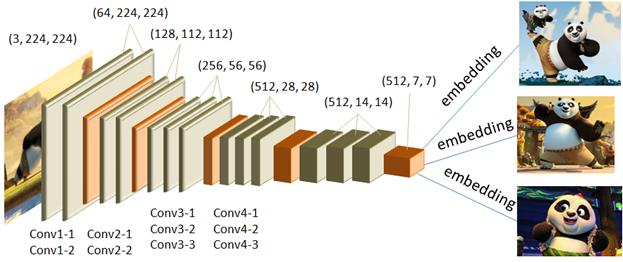
Как видите, близкие по смыслу слова действительно располагаются рядом друг с другом. Embedding изображенийНаряду с embedding слов по аналогии можно выделять и embedding изображений. Один из самых простых способов – это взять уже обученную глубокую НС, например, VGG-16 или 19 или ResNet и вектор последнего сверточного слоя, как раз будет содержать общую компактную информацию о входном изображении:
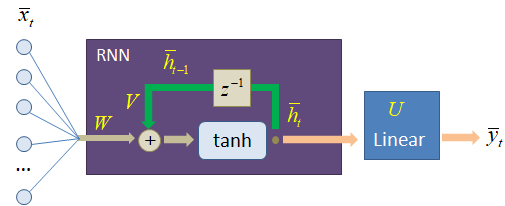
И можно ожидать, что близкие по содержанию изображения будут иметь близкие эмбеддинг-векторы. То есть, похожие изображения можно находить, например, по евклидовому расстоянию между векторами с последнего сверточного слоя. Применение embedding слов на практикеНо давайте вернемся к эмбеддингу слов и посмотрим, что нам дает применение этих векторов в моделях нейронных сетей. На предыдущем занятии мы с вами реализовывали следующую рекуррентную сеть для прогноза отдельных символов, представленных one-hot векторами:
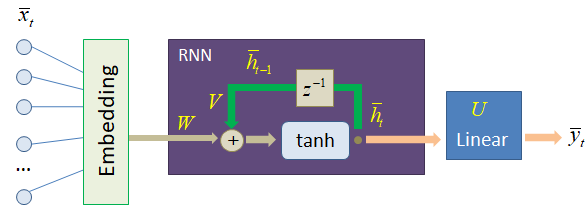
И в самом начале этот one-hot вектор пропускался через полносвязный слой с весами матрицы W, уменьшая размерность входного вектора до 64 – размера вектора скрытого состояния. Получается, что матрица W здесь играет роль embedding-слоя, упаковывая one-hot векторы в более компактное представление. И это действительно так. Слой W можно воспринимать, как одну из возможных реализаций embedding-кодирования входной информации. Однако когда мы работаем с гораздо большим объемом словаря, например, словами, то лучше выделить отдельно embedding-слой в обучаемой модели:
Но что это нам дает? Это же обычный линейный полносвязный слой, за которым идет еще один линейный полносвязный, а значит, их комбинация не дает ничего нового? Все верно, если мы в дальнейшем будем обучать Embedding слой, то нашей модели это ничего не даст. Однако формирование векторного представления слов – это отдельная задача, которая может быть решена другими средствами, например, другой моделью. И такие решения на просторах интернета существуют, в том числе и для русского языка. То есть, мы можем воспользоваться уже обученным Embedding-слоем и лишь дообучить нашу модель на поставленную задачу, например, прогноза слов. Это некий аналог transfer learning (трансферного обучения). В результате сети настроиться на компактное и более информативное представление подаваемых слов с выхода embedding-слоя будет куда проще чем, если бы слова были представлены обычными one-hot векторами. В этом ценность отдельного embedding-слоя. На следующем занятии мы с вами воспользуемся уже готовым обученным вариантом векторного представления слов и обучим рекуррентную нейронную сеть выдавать прогноз следующего слова последовательности. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |