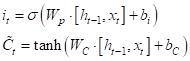|
LSTM - долгая краткосрочная памятьКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs До сих пор мы с
вами использовали простой RNN-слой, в котором выходной тензор с
некоторыми преобразованиями снова подавался на вход. И, как мы уже отмечали, в
такой конструкции вектор скрытого состояния довольно быстро теряет информацию о
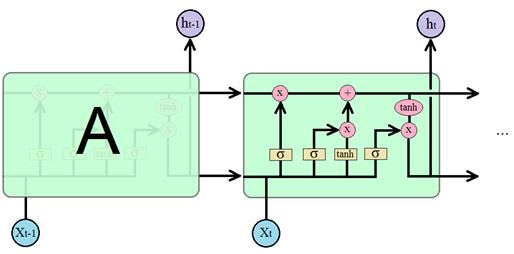
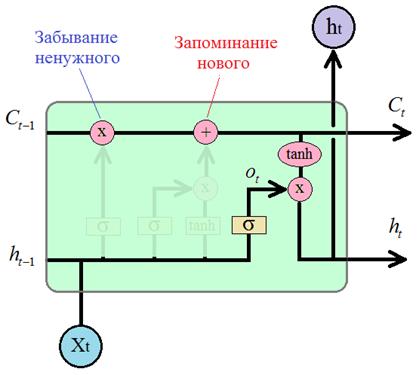
начальных входных элементах подаваемой последовательности. То есть, вектор Я очень люблю программировать, …, поэтому в будущем хочу стать программистом. слова о программировании встречаются и вначале и в конце длинного предложения. А посередке может идти незначащий фрагмент. Следовательно, чтобы сеть имела возможность корректно обрабатывать подобные последовательности, она должна четко схватывать нужный контекст, не обращая внимания на второстепенный. Простейшая архитектура RNN-слоя плохо учитывает такие моменты. Хотя, исследователи говорят, что это скорее недостаток алгоритма обучения, а не архитектуры. Было показано на простых задачах, что теоретически веса можно настроить так, чтобы сеть корректно учитывала даже длинный и сложный контекст. Но на практике этого достичь, как правило, не удается. Поэтому не удивительно, что в 1997 году Зеппом Хохрайтер и Юргеном Шмидхубером (Jürgen Schmidhuber) была предложена другая архитектура известная под названием «долгая краткосрочная память»: LSTM (Long short-term memory) которая при обучении способна схватывать существенные детали, как далекого прошлого контекста, так и относительно недавнего. Эта архитектура была основной «рабочей лошадкой» рекуррентных сетей вплоть до 2017 года. И сегодня остается весьма востребованной во многих прикладных задачах. Давайте с ней познакомимся поближе. Архитектура LSTM блокаВ базовом исполнении рекуррентный LSTM слой можно изобразить следующим образом:
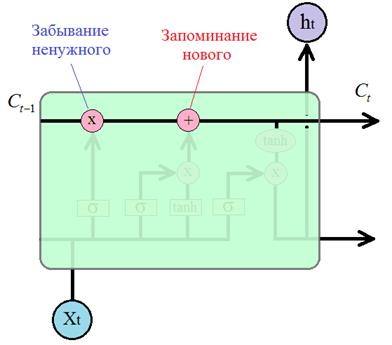
Давайте теперь разберем принцип работы этой ячейки. Отличительной чертой архитектуры LSTM является наличие вот этой верхней связи, по которой, как бы движется вектор контекста (буква C – от слова context):
Благодаря ее
наличию LSTM-блок имеет
возможность сохранять и передавать долгосрочный контекст дальше по рекурсии.
Естественно, возникают вопросы: как и почему при поэлементном умножении
происходит забывание чего-то ненужного, а при поэлементном сложении –
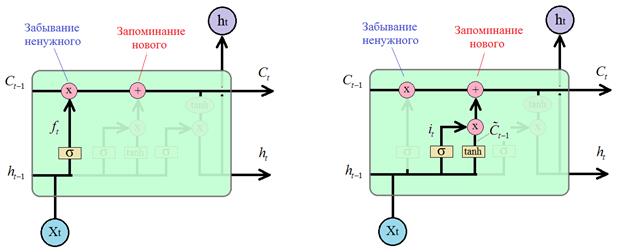
запоминание чего-то нового? Сначала разберемся с забыванием. На вход операции
умножения поступают два вектора: один
Из этого рисунка
видно, что вектор
Здесь
И при
поэлементном умножении из вектора Теперь
посмотрим, как происходит обновление контекста при поэлементном сложении. То,
что сеть будет добавлять, формируется по только что описанному принципу.
Сначала вычисляется оценочный вектор и вектор контекста для текущего элемента
а, затем, они поэлементно умножаются:
Благодаря этому
умножению из вектора добавочного контекста будет удаляться ненужная для
долгосрочного запоминания информация. И, далее, сформированный вектор
Так в блоке LSTM меняется долгосрочный контекст от итерации к итерации. Наконец,
последний этап работы блока – это формирование выходного скрытого состояния
Принцип все тот же, сначала формируется оценочный вектор с помощью полносвязного слоя с сигмоидальной функцией активации:
Далее, вектор
долгосрочного контекста (памяти)
Конечно, слушая о порядке работы блока LSTM и описание примера, невольно напрашивается вопрос: почему сеть будет работать именно так, как мы полагаем? Почему бы после корректного обучения ей не работать как-то иначе, по другим принципам, используя ту же самую архитектуру? Здесь есть один важный момент. Элементы LSTM-блока при обучении будут приобретать те признаки, которым их легче обучить. Например, гораздо проще реализовать «забывание» контекста через умножение, чем через сложение, поэтому именно умножение в итоге будет отвечать за «забывание». А сложение – за добавление чего-то нового. Здесь разделение обязанностей происходит по принципу: что проще, то и делается. Это как вода, которая течет по своему руслу. Ей же никто не говорил течь именно по ложбинке? Это определяется законами физики, главным образом гравитацией, в результате которой мы наблюдаем именно такое ее поведение – ей «проще» течь по руслу, чем по холмам. Также и весовые коэффициенты НС приобретают функциональность, которую им проще реализовывать. В результате, архитектура LSTM работает в целом так, как задумано ее создателями. На самом деле вся эта магия хорошо сочетается с алгоритмом градиентного спуска и если детально разобрать процесс обучения НС, то это станет вполне очевидным фактом. Использование LSTM-слоя в PyTorchИтак, мы рассмотрели с вами лишь базовую архитектуру LSTM-блока. На практике применяют различные их модификации. Но все они работают по похожему принципу. Давайте посмотрим, как можно создавать и использовать такие блоки в PyTorch. Чтобы создать LSTM-слой следует воспользоваться классом: torch.nn.LSTM который принимает практически те же параметры, что и ранее рассмотренный класс RNN:
Для примера давайте создадим такой слой и пропустим через него тензор x размерностью: (batch_size, sq_length, d_size) import torch import torch.nn as nn rnn = nn.LSTM(10, 16, batch_first=True) x = torch.randn(1, 5, 10) # (batch_size, sq_length, d_size) y, (h, c) = rnn(x) print('y:', y.size()) print('h:', h.size()) print('c:', c.size()) В консоли увидим строчки: y: torch.Size([1, 5, 16])
Если же слой будет двунаправленным: rnn = nn.LSTM(10, 16, batch_first=True, bidirectional=True) то тензоры y, h, c будут иметь размеры: y:
torch.Size([1, 5, 32])
Как видите, здесь все работает по аналогии с RNN-слоем, только дополнительно появляется тензор долгосрочного контекста c. В качестве рабочего примера давайте в программе предыдущего занятия заменим RNN-слой на LSTM и посмотрим, что получится. Класс модели в этом случае будет иметь вид: class WordsRNN(nn.Module): def __init__(self, in_features, out_features): super().__init__() self.hidden_size = 16 self.in_features = in_features self.out_features = out_features self.rnn = nn.LSTM(in_features, self.hidden_size, batch_first=True, bidirectional=True) self.out = nn.Linear(self.hidden_size * 2, out_features) def forward(self, x): x, h = self.rnn(x) hh = torch.cat((h[0][-2, :, :], h[0][-1, :, :]), dim=1) y = self.out(hh) return y После 20 эпох обучения, получим: 0.8459920883178711
Вот принцип работы LSTM-блока и пример его использования во фреймворке PyTorch. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |