|
Классы Dataset и DataloaderКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущем занятии мы с вами разобрали несколько способов хранения выборок на внешнем носителе. Теперь возникает вопрос, как считывать эти данные и подавать на вход нейронной сети для ее обучения и последующего тестирования? Конечно, для этого можно было бы написать свою функцию или даже класс, который бы брал на себя этот функционал. Но, так как это типовая задача, то в PyTorch такие классы уже существуют и, как вы уже догадались, они называются:
Все эти классы расположены в ветке: torch.utils.data и работают в паре друг с другом. Начнем с класса Dataset. Класс DatasetКак мы уже знаем, структура выборок и способы их представления могут быть самыми разными. Поэтому чтобы работать с конкретной выборкой необходимо прописать свой собственный класс, унаследованный от класса Dataset. При этом сам класс должен иметь следующий минимальный функционал: import torch.utils.data as data class MyDataset(data.Dataset): # имя класса MyDataset может быть любым def __init__(self): # инициализация переменных объекта класса pass def __getitem__(self, item): # возвращение образа выборки по индексу item pass def __len__(self): # возвращение размера выборки pass То есть, назначение класса MyDataset возвращать образы выборки по указанному индексу item, и общий размер выборки. Для этого создается объект класса: d_train = MyDataset([набор аргументов]) с которым возможны следующие команды: x_j, y_j = d_train[j] # входной вектор x_j и целевое значение y_j data_sz = len(d_train) # размер выборки Все эти команды отрабатывают благодаря переопределению магических методов __getitem__ и __len__ в классе MyDataset. Для больших выборок метод __getitem__ загружает в память нужный образ по его индексу и возвращает в виде пары: входной вектор, целевое значение. В результате происходит экономия памяти устройства, в котором хранятся только нужные на данный момент образы выборки, а не вся выборка сразу. Позже мы с вами реализуем такой класс для считывания изображений цифр и обучим НС их классифицировать. Вы увидите во всех деталях, как это может быть сделано. Класс DataloaderИтак, класс Dataset позволяет создавать унифицированный (стандартизированный) интерфейс извлечения образов из выборки. Но этого недостаточно. При обучении нейронных сетей (и не только) часто требуется вначале перемешать всю выборку, а затем, извлекать из нее группы наблюдений, которые называются батчами (batch) или мини-батчами (mini-batch). Затем, вся эта группа в виде тензора размером: (batch_size, x_size) подается на вход модели (нейронной сети), которая на выходе формирует набор данных (прогнозов) в виде тензора размерностью: (batch_size, y_size) После этого корректируются веса нейронной сети, берется следующий mini-batch и процедура обучения повторяется для нового пакета данных. Так вот, класс Dataloader как раз автоматизирует процесс перемешивания и формирования пакетов образов. Для этого достаточно создать объект этого класса следующей командой: train_data = data.DataLoader(d_train, batch_size, shuffle=True, drop_last=False) Здесь d_train – объект класса MyDataset; batch_size – размер батча; shuffle=True – выполнить перемешивание образов выборки; drop_last – отбрасывать или нет последний batch. Аргумент drop_last иногда бывает полезен для отбрасывания последнего батча, так как он может содержать меньшее число образов, указанное в batch_size. Например, если у нас выборка в 100 элементов и batch_size=32, то размер последнего пакета составит: 100 % 32 = 4 образа По умолчанию последний пакет не отбрасывается. Значение параметра batch_size мы выбираем самостоятельно. Часто он принимает одно из значений: 16, 32, 64, 128 Хотя, мы можем указать и любое другое разумное значение. Строгого правила здесь нет. Извлечение пакетов (batch) из выборкиИтак, у нас имеется объект train_data класса Dataloader. И этот объект связан с набором данных, описываемых классом MyDataset. Как теперь, используя объект train_data выбирать последовательно пакеты образов из обучающей выборки? Делается все очень просто. Сам по себе объект train_data можно воспринимать как генератор и перебирать его элементы с помощью стандартного цикла for языка Python: for x_train, y_train in train_data: … На каждой итерации будем получать входной тензор x_train размерностью: (batch_size, x_size) и выходной тензор y_train размерностью: (batch_size, y_size) Далее эти тензоры могут быть использованы для одного шага обучения НС по алгоритму back propagation. Как видите, все достаточно просто.
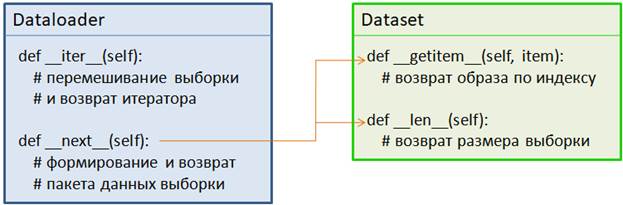
В действительности классы Dataset и Dataloader образуют связку, показанную на рисунке выше. При формировании итератора происходит перемешивание образов выборки (на самом деле перемешиваются лишь индексы, а не сами образы, т.к. они все сразу недоступны в классе Dataloader). А магический метод __next__ вызывается при извлечении текущего пакета (batch). Этот метод обращается к объекту класса Dataset и по индексам формирует текущий mini-batch. Сохраняет его в тензорах и возвращает результат, который мы получаем в цикле for в виде переменных x_train, y_train. На следующем занятии мы с вами сформируем класс Dataset для работы с выборкой изображений цифр с последующей их классификацией с помощью нейронной сети. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |