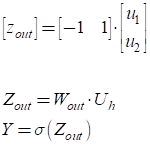|
Использование CPU и GPU на примере простой НСКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs После установки фреймворка PyTorch и знакомства с операциями над тензорами, пришло время использовать эти знания для реализации нейронной сети, рассмотренной на одном из первых занятий.
Я напомню, что с ее помощью мы определяли, нравится парень девушке или нет. На вход подавали:
Если выходной сигнал
Соответственно,
выходные значения
А итоговое выходное значение сети по формулам:
Программу, реализующую эту логику, на PyTorch можно записать следующим образом: neuro_net_9.py: https://github.com/selfedu-rus/neuro-pytorch/ Перенос вычислений на GPUКонечно, это очень простая нейронная сеть, которая с легкостью может быть посчитана центральным процессором компьютера. Однако на практике сети бывают гораздо, гораздо сложнее с десятками и сотнями миллионов нейронов и еще большим числом связей. Вычисления таких сетей лучше оптимизировать. Для этого очень хорошо подходят графические процессоры (GPU – Graphics Processing Unit). Они оптимизированы для стандартных матричных операций. И, как вы уже догадались, фреймворк PyTorch позволяет переносить вычисления на такие графические процессоры. Правда, поддержка реализована только для относительно новых видеокарт фирмы Nvidia. Если вы счастливый обладатель одной из них, то следующий программный код у вас заработает. Итак, первым делом необходимо убедиться, что PyTorch имеет возможность взаимодействовать с GPU текущего устройства. В PyTorch имеется ветка torch.cuda, содержащая наборы функций для взаимодействия с GPU. В частности команда: res = torch.cuda.is_available() возвращает False, если поддержка GPU не настроена, и True – если GPU может быть использован пакетом PyTorch. Если на компьютере с графической картой Nvidia функция вернула False, то возможно не установлена или установлена не та версия библиотеки CUDA. Но вне зависимости от возможности использования GPU программу следует писать так, чтобы она корректно работала и с поддержкой GPU и без него. Для этого часто в программе определяют переменную вида: device = torch.device("cuda" if torch.cuda.is_available() else "cpu") Это устройство будет использоваться, при необходимости переноса вычислений на GPU, если он доступен, а иначе, все будет вычисляться центральным процессором. Я думаю, вы догадываетесь, что когда мы ранее в программе создавали тензор, например, командой: w_out = torch.FloatTensor([-1, 1, -0.5]) или командой: w_out = torch.tensor([-1, 1, -0.5]) то он по умолчанию размещается на CPU. Если же его нужно переместить (скопировать) на GPU, то можно воспользоваться методом to: w_out = w_out.to(device) либо сразу создать на GPU: w_out = torch.tensor([-1, 1, -0.5], device= device) Конечно, в нашем примере копирование тензора w_out на GPU произойдет только при поддержке графического процессора. Иначе, он так и останется на CPU. Также можно воспользоваться методом cuda: w_out = w_out.cuda() # перенос тензора на GPU но без поддержки GPU он приведет к ошибке. Поэтому прежде чем его вызывать, необходимо убедиться, что PyTorch может использовать графический процессор. Обратное копирование тензора с GPU на CPU выполняется либо методом cpu: w_out = w_out.cpu() либо с помощью метода to: w_out = w_out.to("cpu") На мой взгляд, первый вариант удобнее, т.к. центральный процессор всегда присутствует и метод cpu не приводит к каким-либо ошибкам из-за недоступности устройства. Чтобы определить, где именно находится тензор, используется метод get_device: d = w_out.get_device() # -1 – CPU; 0, 1, 2, … - GPU (с номером одного из них) Это особенно важно, т.к. взаимные операции между тензорами можно выполнять, только если они располагаются на одном процессоре. Например, следующая программа завершится с ошибкой (даже при поддержке GPU): x = torch.tensor([1, 2, 3], device="cuda:0") y = torch.FloatTensor([1, 2, 3]) r = x + y # ошибка: тензоры на разных процессорах Далее, так как GPU и CPU – это разные процессоры, то и генераторы псевдослучайных чисел у них работают независимо друг от друга. Чтобы задавать «зерно» генератора для GPU следует вызвать следующие функции: torch.cuda.manual_seed(123) # установка «зерна» для текущего GPU torch.cuda.manual_seed_all(123) # «зерно» для всех поддерживаемых GPU Причем, эти функции «безопасны» и не приводят к ошибкам, если нет поддержки GPU. К тому же, для получения предсказуемых случайных последовательностей, дополнительно следует отключить стохастический режим работы GPU, который используется для ускорения вычислений: torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False Обычно установка «зерна» и отключение стохастического режима GPU делается с целью отладки программного кода. В противном случае все стоит оставить как есть. Реализация НС с вычислениями на GPUДавайте для примера реализуем предыдущую НС с вычислениями на GPU. Программу, реализующую эту логику, можно записать следующим образом: neuro_net_9gpu.py: https://github.com/selfedu-rus/neuro-pytorch/ Конечно, для такой маленькой НС никакого выигрыша от использования GPU не будет. Возможно, даже программа будет работать дольше из-за дополнительного копирования тензоров на GPU. Но для крупных НС выигрыш тем больше, чем больше размер используемых в вычислениях тензоров. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |