|
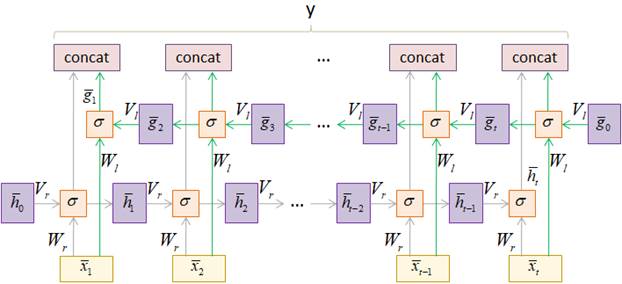
Двунаправленные RNN в PyTorch. Сентимент-анализ фразКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущем занятии мы с вами в целом разобрали принцип работы двунаправленных (bidirectional) рекуррентных слоев. Их достаточно легко можно создать во фреймворке PyTorch с помощью известного нам класса nn.RNN, прописав дополнительный параметр bidirectional=True: torch.nn.RNN(input_size, hidden_size, batch_first=True, bidirectional=True, …) Работу полученного слоя можно показать в виде следующей его развертки во времени:
Как видим, на
его выходе формируется набор объединенных векторов
Применение класса nn.RNN с параметром bidirectional=TrueНа программном
уровне двунаправленный рекуррентный слой, созданный с помощью класса nn.RNN, используется
аналогично однонаправленному. Тензор входной последовательности (batch_size, sq_length, d_size) В соответствии с ним двунаправленный RNN можно сформировать с помощью команды: rnn = nn.RNN(d_size, hidden_size, batch_first=True, bidirectional=True) После создания объекта класса nn.RNN мы можем воспользоваться этим rnn-слоем, например, следующим образом: import torch import torch.nn as nn rnn = nn.RNN(300, 16, batch_first=True, bidirectional=True) x = torch.randn(8, 3, 300) y, h = rnn(x) print('y:', y.size()) print('h:', h.size()) В консоли увидим строчки: y: torch.Size([8, 3, 32])
Здесь тензор y содержит все объединенные векторы скрытых состояний в соответствии с приведенным рисунком, а тензор h – векторы скрытых состояний на последних шагах рекурсии (при прямом и обратном проходах по последовательности). Как видите, все достаточно просто. Модель двунаправленной RNN-сети для сентимент-анализа фразДавайте воспользуемся этим классом для создания модели двунаправленной (bidirectional) рекуррентной сети, которая будет решать задачу сентимент-анализа коротких фраз. По сути, это задача бинарной классификации входных последовательностей на классы «позитив» и «негатив». Модель будет состоять из рекуррентного слоя, затем, слоя конкатенации (объединения) двух векторов скрытого состояния, взятых с последних шагов рекурсии, и полносвязного линейного слоя с одним выходом, который будет определять принадлежность фразы к первому или второму классу. Получаем следующий класс модели: class WordsRNN(nn.Module): def __init__(self, in_features, out_features): super().__init__() self.hidden_size = 16 self.in_features = in_features self.out_features = out_features self.rnn = nn.RNN(in_features, self.hidden_size, batch_first=True, bidirectional=True) self.out = nn.Linear(self.hidden_size * 2, out_features) def forward(self, x): x, h = self.rnn(x) hh = torch.cat((h[-2, :, :], h[-1, :, :]), dim=1) y = self.out(hh) return y Формирование обучающей выборкиСледующим шагом нам нужно определиться со структурой обучающей выборки. Я подготовил два текстовых файла train_data_true и train_data_false с короткими позитивными и негативными высказываниями. Эти файлы доступны по ссылке: train_data_true, train_data_false: https://github.com/selfedu-rus/neuro-pytorch Вот несколько примеров таких фраз:
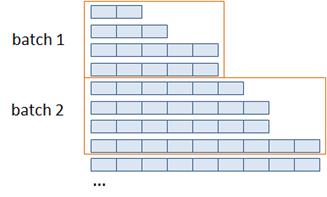
Видим, что они имеют разную длину. Конечно, на вход рекуррентного слоя можно подавать последовательности разной длины. Но в тензоре в пределах одного mini-batch все векторы должны быть равны по длине. Что же делать с недостающими элементами более коротких фраз? Один из наиболее частых вариантов – заполнение их нулями. Мы именно так и поступим. Вторая особенность, которая вытекает из неравномерности слов в предложениях, связана с наличием очень коротких и очень длинных фраз, которые могут встречаться в заготовленных текстовых файлах. Если в одном батче встретятся такие разные по длине высказывания, то самое короткое придется дополнять большим числом нулей. А этого, как вы понимаете, хотелось бы избежать. Поэтому мы вначале прочитаем все фразы из обоих файлов, а затем отсортируем их по длине (убыванию или возрастанию – не важно). После этого по порядку разобьем по мини-батчам:
Благодаря этому у нас будет минимизировано число нулевых элементов. Давайте реализуем описанную логику формирования батчей обучающей выборки коротких высказываний. Сами слова будем кодировать в виде embedding-векторов так, как это мы делали в модели прогнозирования слов. Получаем следующий класс датасета: class PhraseDataset(data.Dataset): def __init__(self, path_true, path_false, navec_emb, batch_size=8): self.navec_emb = navec_emb self.batch_size = batch_size with open(path_true, 'r', encoding='utf-8') as f: phrase_true = f.readlines() self._clear_phrase(phrase_true) with open(path_false, 'r', encoding='utf-8') as f: phrase_false = f.readlines() self._clear_phrase(phrase_false) self.phrase_lst = [(_x, 0) for _x in phrase_true] + [(_x, 1) for _x in phrase_false] self.phrase_lst.sort(key=lambda _x: len(_x[0])) self.dataset_len = len(self.phrase_lst) def _clear_phrase(self, p_lst): for _i, _p in enumerate(p_lst): _p = _p.lower().replace('\ufeff', '').strip() _p = re.sub(r'[^А-яA-z- ]', '', _p) _words = _p.split() _words = [w for w in _words if w in self.navec_emb] p_lst[_i] = _words def __getitem__(self, item): item *= self.batch_size item_last = item + self.batch_size if item_last > self.dataset_len: item_last = self.dataset_len _data = [] _target = [] max_length = len(self.phrase_lst[item_last-1][0]) for i in range(item, item_last): words_emb = [] phrase = self.phrase_lst[i] length = len(phrase[0]) for k in range(max_length): t = torch.tensor(self.navec_emb[phrase[0][k]], dtype=torch.float32) if k < length else torch.zeros(300) words_emb.append(t) _data.append(torch.vstack(words_emb)) _target.append(torch.tensor(phrase[1], dtype=torch.float32)) _data_batch = torch.stack(_data) _target = torch.vstack(_target) return _data_batch, _target def __len__(self): last = 0 if self.dataset_len % self.batch_size == 0 else 1 return self.dataset_len // self.batch_size + last В инициализатор передаем пути к текстовым файлам с позитивными и негативными высказываниями, объект обученного embedding-слоя и размер формируемого батча. Этот последний параметр будет необходим, т.к. мы батчи будем создавать непосредственно в этом классе. Это связано с тем, что стандартный класс DataLoader, который отвечает за формирование батчей, поэлементно выбирает данные из класса Dataset и в этом случае неясно сколько нулевых элементов следует добавлять к коротким высказываниям. Поэтому мы сделаем небольшую хитрость. Мини-батч будет создаваться в текущем классе, а в объекте DataLoader укажем размер батча равный одному. В итоге сохраним общую логику выбора обучающих данных и будем иметь возможность корректно формировать каждый батч с последовательностями разной длины. Далее, в инициализаторе класса PhraseDataset выполняется построчная загрузка текстовых файлов, т.к. каждое высказывание записано с новой строки. Загруженные строки обрабатываются с переводом слов в их embedding-векторы. Затем, все фразы объединяются в единый список в виде кортежа формата: (последовательность, номер класса) С последующей сортировкой по длине. Ключевой метод __getitem__ этого класса должен выдавать по индексу item не отдельную фразу, а сразу mini-batch – пакет фраз. В итоге item определяет индекс батча, а не отдельного образа. Для определения диапазона индексов образов обучающей выборки значение item умножается на размер батча, а последний граничный индекс определяется прибавлением к item размера батча. Получаем диапазон индексов [item; item_last) для образов текущего батча. Далее по программе в коллекцию _data_batch заносятся тензоры embedding-векторов фраз, а в коллекцию _targets – номера классов соответствующих высказываний. Последний магический метод __len__ возвращает число батчей обучающей выборки. Обучение модели сентимент-анализу коротких высказыванийПосле определения класса модели и датасета можно переходить непосредственно к обучению нейронной сети. Вначале загрузим обученные embedding-векторы для слов русского языка: path = 'navec_hudlit_v1_12B_500K_300d_100q.tar' navec = Navec.load(path) Затем, сформируем модель и обучающую выборку: d_train = PhraseDataset("train_data_true", "train_data_false", navec) train_data = data.DataLoader(d_train, batch_size=1, shuffle=True) model = WordsRNN(300, 1) Обратите внимание, что размер batch_size в классе DataLoader устанавливается в единицу с перемешиванием батчей (shuffle=True). А в модели мы указываем входной размер 300 embedding-векторов слов и одно выходное значение – номер класса (вероятность принадлежности классу). Далее зададим оптимизатор, функцию потерь (бинарную кросс-энтропию), число эпох обучения 20 и переводим модель в режим обучения: optimizer = optim.Adam(params=model.parameters(), lr=0.001, weight_decay=0.001) loss_func = nn.BCEWithLogitsLoss() epochs = 20 model.train() Сам цикл обучения будет практически таким же, как и в предыдущих наших программах: for _e in range(epochs): loss_mean = 0 lm_count = 0 train_tqdm = tqdm(train_data, leave=True) for x_train, y_train in train_tqdm: predict = model(x_train.squeeze(0)).squeeze(0) loss = loss_func(predict, y_train.squeeze(0)) optimizer.zero_grad() loss.backward() optimizer.step() lm_count += 1 loss_mean = 1/lm_count * loss.item() + (1 - 1/lm_count) * loss_mean train_tqdm.set_description(f"Epoch [{_e+1}/{epochs}], loss_mean={loss_mean:.3f}") После обучения сохраним модель: st = model.state_dict() torch.save(st, 'model_rnn_bidir.tar') И выполним сентимент-анализ какого-нибудь высказывания: model.eval() phrase = "Сегодня пасмурная погода" phrase_lst = phrase.lower().split() phrase_lst = [torch.tensor(navec[w]) for w in phrase_lst if w in navec] _data_batch = torch.stack(phrase_lst) predict = model(_data_batch.unsqueeze(0)).squeeze(0) p = torch.nn.functional.sigmoid(predict).item() print(p) print(phrase, ":", "положительное" if p < 0.5 else "отрицательное") После запуска программы увидим результат: 0.8657259345054626
Конечно, это всего лишь учебный пример, который показывает, как можно использовать двунаправленный RNN-слой и формировать обучающую выборку из последовательностей разной длины. Для получения хорошего результата здесь следует, как минимум, значительно увеличить объем обучающих данных и посмотреть, как при этом будет себя вести обученная модель. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |