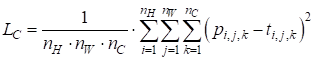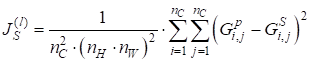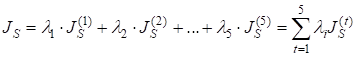|
Делаем стилизацию изображений на PyTorchКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На прошлом занятии мы с вами подробно разобрали идею стилизации изображений, предложенную Леоном Гатисом в 2015-м году. Здесь же мы посмотрим на пример ее реализации с помощью фреймворка PyTorch. Вначале, как всегда, импортируем необходимые модули. Они будут следующими: from PIL import Image import numpy as np import matplotlib.pyplot as plt import torch from torchvision import models import torchvision.transforms.v2 as tfs_v2 import torch.nn as nn import torch.optim as optim Для чего нужен каждый из них станет понятно по ходу изложения материала. Далее нам понадобятся два изображения:
Я их подготовил заранее под именами img.jpg и img_style.jpg соответственно. Каждое представлено в формате RGB и выглядят следующим образом:
Выполним их загрузку с помощью модуля Image: img = Image.open('img.jpg').convert('RGB') img_style = Image.open('img_style.jpg').convert('RGB') Здесь конвертация в формат RGB выполняется для случаев, когда исходные изображения имеют другое представление. В результате переменная img будет ссылаться на контентное изображение, а img_style – на стилизованное. Далее, планируется использовать сеть VGG19, поэтому наши изображения нужно преобразовать в тензор фреймворка PyTorch. Для этого определим следующее преобразование: transforms = tfs_v2.Compose([tfs_v2.ToImage(), tfs_v2.ToDtype(torch.float32, scale=True), ]) И применим его к загруженным изображениям: img = transforms(img).unsqueeze(0) img_style = transforms(img_style).unsqueeze(0) Напомню, что метод unsqueeze(0) необходим для добавления первой оси – размер батча входного тензора. После этого создадим тензор для формируемого изображения (то, которое будет непосредственно подвергаться стилизации): img_create = img.clone() img_create.requires_grad_(True) Обратите внимание, что у тензора img_create необходимо включить градиенты, для изменения пикселей градиентным алгоритмом. Далее нам потребуется обученная модель сети VGG19, но без полносвязной НС. В данной задаче она нам не нужна. Мы уже знаем, что формально такую модель можно определить командами: model = models.vgg19(weights=models.VGG19_Weights.DEFAULT) mf = model.features Однако она будет выдавать только один тензор с последнего слоя, а нам необходимы выходные данные сразу с нескольких сверточных слоев сети:
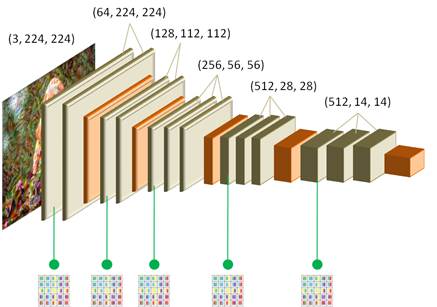
Чтобы модель возвращала все необходимые данные, создадим свой собственный класс, унаследованный от класса Module: class ModelStyle(nn.Module): def __init__(self): super().__init__() _model = models.vgg19(weights=models.VGG19_Weights.DEFAULT) self.mf = _model.features self.mf.requires_grad_(False) self.requires_grad_(False) self.mf.eval() self.idx_out = (0, 5, 10, 19, 28, 34) self.num_style_layers = len(self.idx_out) - 1 # последний слой для контента def forward(self, x): outputs = [] for indx, layer in enumerate(self.mf): x = layer(x) if indx in self.idx_out: outputs.append(x.squeeze(0)) return outputs Здесь все уже вам должно быть понятно. В инициализаторе создается внутренняя модель VGG19 с набором обученных весов, и оставляются только сверточные слои. При этом модель self.mf впоследствии не должна обучаться и градиенты для ее весовых коэффициентов вычислять не нужно. Поэтому они отключаются командой self.mf.requires_grad_(False). То же самое делается и для всей текущей модели. Далее, модель переводится в режим эксплуатации и формируется набор индексов слоев, с которых будут сниматься данные. Почему именно такие индексы? Если распечатать модель self.mf, то мы увидим следующую информацию: Sequential(
(br): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
На ее основе и были сформирован список из индексов нужных нам слоев. Причем, последний индекс 34 относится к последнему сверточному слою, по которому будут определяться потери по контенту, а все остальные индексы – к слоям для вычисления потерь по стилизации. Локальная переменная self.num_style_layers – это вспомогательная переменная, хранящая число сверточных слоев используемых для оценки степени соответствия стилизации. В методе forward входной тензор x прогоняется по всем слоям модели self.mf и если индекс текущего слоя содержится в списке self.idx_out, то его данные сохраняются в списке outputs. В конце этот список возвращается. Все, теперь у нас есть нужная нам модель, дающая всю необходимую информацию. Создадим ее командой: model = ModelStyle() и пропустим через нее оба загруженных изображения: outputs_img = model(img) outputs_img_style = model(img_style) На выходе будут списки с указанных сверточных слоев. Как видите, все достаточно просто и удобно. Вычисление потерьДалее нам нужно вычислить потери по контенту и стилю. Начнем с контента. Из списка outputs_img нам понадобится последний элемент – тензор со значениями последнего сверточного слоя сети VGG19. И аналогичные значения при проходе формируемого изображения: outputs_img_create = model(img_create) А затем, вычислить потери по формуле:
Для этого объявим функцию с именем get_content_loss следующим образом: def get_content_loss(base_content, target): return torch.mean( torch.square(base_content - target) ) Как видите, фреймворк PyTorch предоставляет богатый математический функционал при работе с тензорами. В результате всю формулу можно записать буквально в одну строчку. Итак, потери по контенту у нас есть. Далее нужно вычислить потери по стилю. Для этого необходимо уметь вычислять матрицы Грама для тензоров пяти выбранных сверточных слоев. Так как эти матрицы придется определять постоянно, то объявим отдельную функцию, которую так и назовем gram_matrix: def gram_matrix(x): channels = x.size(dim=0) g = x.view(channels, -1) gram = torch.mm(g, g.mT) / g.size(dim=1) return gram На ее вход поступает тензор x в формате: (channels, height, width) Затем, этот тензор вытягивается по каналам в матрицу g размером: (channels, height * width) И делается матричное умножение
Следом объявим функцию, которая будет вычислять общие потери по стилю: def get_style_loss(base_style, gram_target): style_weights = [1.0, 0.8, 0.5, 0.3, 0.1] _loss = 0 i = 0 for base, target in zip(base_style, gram_target): gram_style = gram_matrix(base) _loss += style_weights[i] * torch.mean(torch.square(gram_style - target)) i += 1 return _loss Первый параметр base_style – набор тензоров со всех слоев формируемого изображения. Второй параметр gram_target – набор матриц Грама для стилевого изображения. Список style_weights содержит весовые коэффициенты при суммировании потерь на различных слоях. А затем, в цикле попарно перебираются все тензоры и вычисляется рассогласование соответствующих матриц Грама по формуле:
с последующим суммированием:
Стилизация изображенияВсе необходимые функции мы с вами объявили, и можно вернуться непосредственно к реализации алгоритма стилизации изображения. После того, как были вычислены выходные карты признаков для загруженных изображений: outputs_img = model(img) outputs_img_style = model(img_style) мы сразу сформируем список из матриц Грама для стилевого изображения: gram_matrix_style = [gram_matrix(x) for x in outputs_img_style[:model.num_style_layers]] так как эти матрицы впоследствии меняться не будут. После этого определим веса для коэффициентов альфа и бета, используемых в формуле:
Будем сохранять лучшие результаты стилизации с помощью переменных best_loss и best_img, установим 100 эпох для обучения и воспользуемся оптимизатором Adam: content_weight = 1 style_weight = 1000 best_loss = -1 epochs = 100 best_img = img_create.clone() optimizer = optim.Adam(params=[img_create], lr=0.01) Обратите внимание, что оптимизируемые параметры – это пиксели формируемого изображения. Осталось описать главный цикл обучения. Реализуем его следующим образом: for _e in range(epochs): outputs_img_create = model(img_create) loss_content = get_content_loss(outputs_img_create[-1], outputs_img[-1]) loss_style = get_style_loss(outputs_img_create, gram_matrix_style) loss = content_weight * loss_content + style_weight * loss_style optimizer.zero_grad() loss.backward() optimizer.step() img_create.data.clamp_(0, 1) if loss < best_loss or best_loss < 0: best_loss = loss best_img = img_create.clone() print(f'Iteration: {_e}, loss: {loss.item(): .4f}') Формируемое изображение пропускается через модель. Затем, вычисляются потери по контенту и стилю. Формируется общее значение потерь. И для их минимизации делается один шаг градиентного спуска, меняя пиксели изображения img_create. После этого значения тензора img_create ограничиваются исходным диапазоном [0; 1]. Далее идет проверка на определение лучшего варианта стилизации с точки зрения функции потерь. Лучшее изображение сохраняется в переменной best_img и в конце выводится информация о текущей эпохе и значение функции потерь. Вывод и сохранение результатовЧтобы визуально оценить полученный результат, выведем лучшее полученное изображение на экран. Для этого подготовим изображение best_img к отображению: x = best_img.detach().squeeze() low, hi = torch.amin(x), torch.amax(x) x = (x - low) / (hi - low) * 255.0 x = x.permute(1, 2, 0) x = x.numpy() x = np.clip(x, 0, 255).astype('uint8') Сохраним его в выходной файл: image = Image.fromarray(x, 'RGB') image.save("result.jpg") И выведем на экран plt.imshow(x) plt.show()
На этом мы завершим данное занятие. Попробуйте в качестве небольшой практики самостоятельно повторить программу стилизации для своих выбранных изображений. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |