|
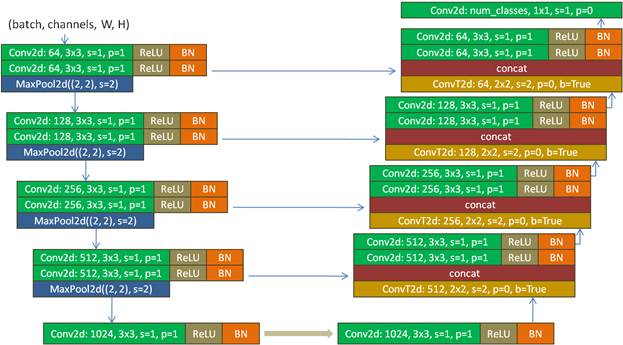
Архитектура сети U-Net. Семантическая сегментация изображенийКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии мы с вами познакомимся с еще одной известной архитектурой сверточной сети под названием U-Net. Ее базовую структуру можно изобразить следующим образом:
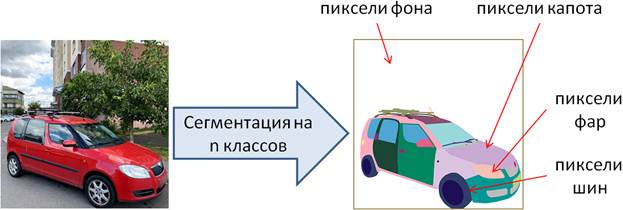
Можно догадаться, что буква U в ее названии пошло от внешнего сходства с видом этой сети. Сама же сеть была предложена в 2015 году командой Олафа Роннебергера для сегментации особых областей на биомедицинских снимках. И показала в этом направлении очень хорошие результаты, заметно обогнав ближайших конкурентов. Часто сеть U-Net используют для задач семантической сегментации, когда классифицируются пиксели входного изображения, относя их к тому или иному классу. Например, для выделения объектов на изображениях можно выделить два класса: фон и объект. В этом случае выходной тензор сети U-Net можно сформировать с теми же размерами, что и входное изображение, но с одним каналом, в котором будут вероятности отнесения каждого пиксела либо к фону, либо к объекту. Получаем своеобразную задачу бинарной классификации. Или же пиксели входного изображения можно ассоциировать с несколькими разными классами. Например, при сегментации автомобилей выделять отдельно капот, фары, шины и т.п. Тогда на выходе будет формироваться тензор с n-каналами, по одному на каждый класс сегментации. Получаем задачу многоклассовой классификации. Таким образом, сеть U-Net можно рассматривать, как универсальный инструмент для семантической сегментации изображений.
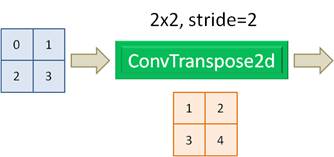
Принцип работы этой сети достаточно прост, несмотря на ее разветвленную архитектуру. Предположим, на ее вход подается изображение с тремя цветовыми каналами и размером 512x512 пикселей. Оно пропускается сначала через первый сверточный слой с 64 каналами и ядром 3x3. К полученным картам признаков применяется функция активации ReLU и результат нормализуется по батчам. Следом идет точно такой же сверточный слой с ReLU и Batch Normalization. На выходе этого слоя получается тензор размерностью (64, 512, 512), то есть, линейные размеры карт признаков совпадают с размерами входного изображения. Далее сигнал разветвляется. Один по skip connection (прямой связи) идет на слой конкатенации (объединения тензоров). С чем он там будет объединяться, мы чуть позже увидим. А другое ответвление поступает на слой Max Pooling, который вдвое уменьшает линейные размеры карт признаков. Полученный тензор размерностью (64, 256, 256) поступает на следующий такой же блок из двух сверточных слоев. На его выходе сигнал также разветвляется на два направления с тензорами размерами (128, 256, 256) и (128, 128, 128) – после MaxPooling. И так делается четыре раза. На выходе слоя Max Pooling четвертого блока тензор имеет размеры (512, 32, 32), который подается на два сверточных слоя с 1024 каналами и ядром 3x3. После каждого слоя также идет функция активации ReLU и Batch Normalization. На выходе получаем тензор размером (1024, 32, 32). Можно условно считать, что с этого момента начинается формирование сегментов входного изображения. Тензор (1024, 32, 32) поступает на сверточный слой ConvTranspose2d, с которым мы еще не сталкивались. Как он в деталях работает, мы увидим чуть позже, а пока достаточно знать, что он с ядром 2x2 и смещением 2 увеличивает линейные размеры карт признаков вдвое. Поэтому на выходе этого слоя получаем тензор размерностью (512, 64, 64). Этот тензор объединяется с другим тензором такого же размера, переданного по skip connection (обходному пути), и в слое конкатенации (concat) формируется тензор размером (1024, 64, 64), то есть, объединение происходит по каналам: сначала первый тензор, потом – второй. Причем, какой именно будет первый, а какой второй, не имеет особого значения, т.к. сеть все равно будет обучаться по той структуре, которую мы определим. Далее идут уже знакомые нам два сверточных слоя с ReLU и Batch Normalization. Затем полученный тензор (512, 64, 64) подается на следующий слой ConvTranspose2d с увеличением линейных размеров карт признаков вдвое. На выходе сформируется тензор размерностью (256, 128, 128). Этот тензор объединяется с соответствующим тензором по skip connection и в слое concat получим тензор (512, 128, 128). И так проходим еще два аналогичных блока. На выходе последнего блока после слоя Batch Normalization получим тензор размерами (64, 512, 512), из которого в последнем сверточном слое с ядром 1x1 формируется результат сегментации на заданное число классов. Объяснение принципа работы сети U-NetЯ думаю, что формально порядок работы сети U-Net, в целом, понятен. Возможно, у вас только остается вопрос, почему общая структура сети именно такая, а не другая? Например, зачем понадобились прямые связи (skip connection) между слоями? Из каких соображений они были введены в эту сеть? Почему бы не сделать что-нибудь попроще для сегментации изображений? На самом деле, еще до сети U-Net было немало попыток решить задачу семантической сегментации самыми разными способами и не только нейронными сетями. Все они с разным успехом работают в своих областях, либо уходят в прошлое, не выдержав конкуренции с новыми подходами. Как раз U-Net один из таких новых алгоритмов, который заменил собой некоторые прежние способы сегментации изображений. В чем же секрет ее успеха? Ранее предпринималось немало попыток сформировать итоговый результат с помощью НС без прямых соединений между слоями (без skip connections). В итоге сжатое представление входного изображения (у нас это тензор (1024, 32, 32)) должно было содержать всю детальную информацию о границах выделяемых областей. А этой информации, как раз было недостаточно, т.к. в глубоких сверточных слоях, как правило, формируется общая информация об объектах и детали контуров здесь пропадали. В результате восстановленная информация давала смазанные, расплывчатые образы. Но благодаря добавлению прямых связей от сверточных слоев разного уровня глубины к последним (выходным) сверточным слоям, появляется гораздо больше деталей, которые учитываются сетью в процессе обучения и используются, затем, для формирования более корректных и четких контуров. Конечно, можно придумать множество сетей аналогичной архитектуры. И они есть. Например, сети U-Net не редко строят на базе предобученных сетей VGG-16, 19, ResNet и некоторых других, которые можно встроить в эту архитектуру. При этом принцип работы алгоритма сегментации сохраняется. Так же вначале выполняется кодирование (сжатие) входного изображения, а затем, восстановление для получения итогового результата. Причем добавление известных предобученных сетей в архитектуру U-Net часто дает хорошие результаты, превосходящие базовую архитектуру этой сети. Принцип работы слоя ConvTranspose2dТеперь, когда мы в целом познакомились с принципом семантической сегментации изображений с помощью сети U-Net, рассмотрим порядок работы нового для нас сверточного слоя ConvTranspose2d. Давайте предположим, что на вход этого слоя поступает тензор с картой признаков 2x2. Сам слой также состоит из ядра 2x2, который сдвигается с шагом 2.
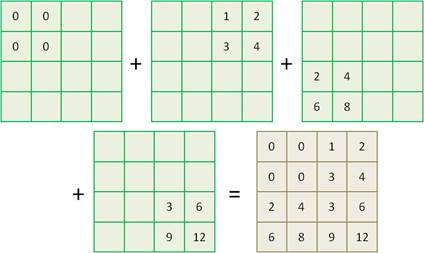
Тогда выходной результат будет формироваться следующим образом. Значение первого элемента карты признаков равно 0. Оно умножается на коэффициенты ядра. Получаем матрицу из четырех нулей, которую условно расположим в левом верхнем углу. Берется следующее значение 1 из карты признаков. Оно также умножается на коэффициенты ядра и матрицу полученных значений записываем в правом верхнем углу. Причем, вторую матрицу сдвигаем на два элемента согласно stride=2. То же самое выполняем с двумя оставшимися значениями 2 и 3 карты признаков. Получаем следующее распределение матриц:
Суммируем все матрицы размером 4x4, получаем итоговый выходной результат. Все это очень легко проверить на PyTorch с помощью следующей короткой программы: import torch import torch.nn as nn x = torch.tensor([[[0, 1], [2, 3]]], dtype=torch.float32) w = torch.tensor([[[[1, 2], [3, 4]]]], dtype=torch.float32) alg = nn.ConvTranspose2d(1, 1, 2, 2, bias=False) st = alg.state_dict() st['weight'] = w alg.load_state_dict(st) y = alg(x) print(y) После выполнения увидим вполне ожидаемый результат: tensor([[[ 0., 0., 1., 2.],
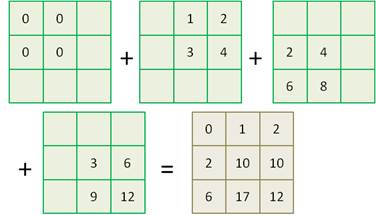
Если же изменить шаг смещения ядра фильтра на stride=1, то получим результат:
И, действительно, если в программе изменить команду: alg = nn.ConvTranspose2d(1, 1, 2, 2, bias=False) то получим именно такой выходной тензор: tensor([[[ 0., 1., 2.],
Вот принцип работы транспонированной свертки, которая способна увеличивать размеры карт признаков. На этом мы завершим первое знакомство с архитектурой сети U-Net. На следующем занятии реализуем ее и обучим для сегментации (выделения) автомобилей на изображениях. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |