|
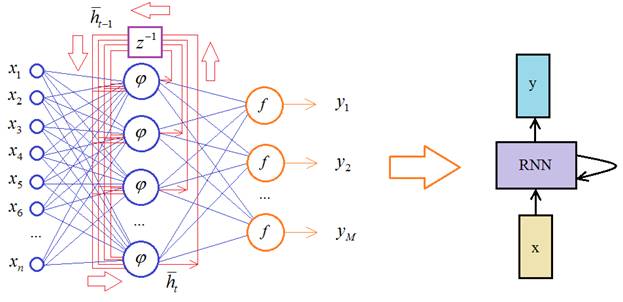
Введение в рекуррентные нейронные сетиКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs До сих пор мы с вами рассматривали сети прямого распространения, когда входной сигнал последовательно, слой за слоем проходил по всей сети и на выходе формировались определенные числовые значения. Недостатком таких сетей является сложность анализа временных последовательностей, например, звукового сигнала, изменение положения объекта во время движения, текстовая информация и многое другое. Во всех этих примерах важно «знание» предыдущих элементов последовательности. Предположим, мы хотим создать нейросеть для перевода текста с русского на английский. В этом случае важен не только набор слов в тексте, но и их порядок следования. В частности, известная фраза: «казнить нельзя, помиловать» может принимать совершенно иной смысл, при изменении порядка слов: «помиловать нельзя, казнить» Для анализа таких данных был разработан другой класс НС – рекуррентные нейронные сети: Recurrent Neural Network (RNN) Исторически первой сетью такого типа была сеть Хопфилда, окончательно оформленная в 1982 г. Она используется в свое, узком классе задач. А первой современной рекуррентной сетью стала сеть Джеффа Элмана, представленная в 1990 г. На ее основе создаются простейшие рекуррентные сети со следующей структурой:
Здесь Математическая модель простейшей рекуррентной сети выглядит так. Вектор выходных значений нейронов скрытого слоя в момент времени t определяется на основе входных данных и предыдущих выходных с этого же слоя (предыдущего состояния сети):
Здесь вы можете
спросить: а откуда брать значение
Это общепринятые
начальные условия работы рекуррентных сетей. Далее, зная выходные значения
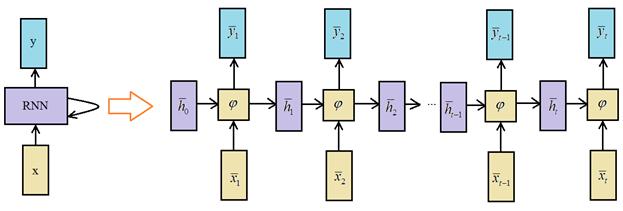
Здесь Следующий шажок к обобщению простейшей рекуррентной НС заключается в использовании произвольных функций активации выходных нейронов. Часто – это гиперболический тангенс, сигмоида или softmax. Довольно популярной практикой является представление рекуррентных сетей с помощью вычислительного графа:
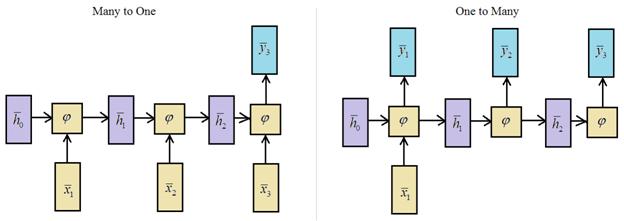
Здесь сеть как бы развернута во времени и мы наглядно видим каждый шаг ее работы. Такая архитектура, когда множеству входных векторов соответствует множество выходных, называется Many to Many По аналогии, можно строить архитектуры:
Какую архитектуру, когда выбирать? Это подсказывает сама прикладная задача. Например, при переводе с одного языка на другой имеем произвольную последовательность слов и на выходе также получаем последовательности произвольной длины, значит, здесь следует использовать архитектуру Many to Many:
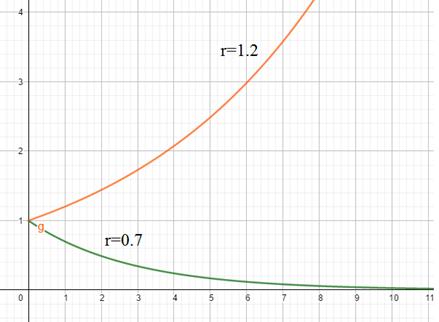
Также из вычислительного графа видно, что рекуррентные сети можно обучать известным нам алгоритмом Back Propagation, так как здесь имеем аналог многослойной сети при развертывании процесса обработки во времени. Но есть и несколько нюансов. Во-первых, на вход каждого нейрона поступает не только входной сигнал, но и предыдущее состояние сети. Во-вторых, весовые коэффициенты едины для всех слоев развернутой сети, так как это, фактически, один и тот же слой, только на разных итерациях вычисления. Но все это незначительно меняет исходную идею градиентного спуска для корректировки весовых коэффициентов и такой модифицированный алгоритм применительно к рекуррентным нейронным сетям стали называть: Backpropagation Through Time (BPTT) Здесь понятие Through Time (сквозь время) как раз относится к учету предыдущих вычислительных шагов, развернутых во времени, при вычислении локальных градиентов. Так как все предыдущие состояния влияют на выходные значения сети, а значит, и на критерий качества. Я решил в видео не приводить пример работы алгоритма BPTT. Думаю, такие нюансы интересны далеко не всем, поэтому просто дам ссылку на pdf-файл с подробным описанием его работы для одного конкретного примера: Вообще, задача обучения рекуррентных сетей более трудоемкая (в вычислительном плане) и требует больше памяти, чем для сетей прямого распространения. Но главная проблема здесь – это обеспечение устойчивости и при обучении и при работе сети. О чем здесь речь? Смотрите, как только в какой-либо системе появляется обратная связь, то вычисления формируются по общему правилу:
В самом простом варианте, эту функцию можно расписать так:
Я здесь все
Применительно к НС – это означает уход в область насыщения функции активации при увеличении числа итераций. А сама сеть превращается в динамическую систему со всеми вытекающими проблемами. И самая главная задача здесь – это обеспечение ее стабильности, устойчивости в процессе работы. Научная область, которая занимается этими вопросами, получила название нейродинамика. Вообще, устойчивость нелинейных динамических систем – это довольно сложная задача. А само понятие их устойчивости часто рассматривается как устойчивость по Ляпунову. Свою работу, посвященной анализу стабильности динамических систем, наш русский математик Ляпунов опубликовал в далеком 1892 году. В частности, там рассматривается прямой метод Ляпунова (сейчас его так называют), который является «рабочей лошадкой» для анализа устойчивости линейных и нелинейных систем. Конечно, я сейчас не буду пускаться во все тяжкие и погружаться в область нейродинамики. Это довольно специфический, математический материал, опять же интересный узкому кругу исследователей, но, вместе с тем, весьма важный для практического использования рекуррентных НС. Для бесстрашных слушателей с хорошей математической подготовкой, могу порекомендовать русский перевод 2-го издания книги: Саймон Хайкин «Нейронные сети (полный курс)» В заключении этого обзорного занятия по рекуррентным НС отмечу некоторые важные особенности в их обучении. В целом, обучение выполняется подобно сетям прямого распространения. Здесь также должна быть сформирована обучающая выборка, элементом этой выборки является полная последовательность данных. Например, мы делаем сентимент анализ коротких высказываний (положительные они, или отрицательные). Так вот, каждое высказывание (последовательность слов) можно принять за одно отдельное наблюдение. Далее, веса сети корректируются после каждого пакета (батча) или после каждого наблюдения. В этом случае, подавая на вход сети отдельные высказывания, веса корректируются после каждого из них, минимизируя заданный критерий качества. Но что делать, если на вход сети подается непрерывный поток данных? Например, в задачах управления беспилотными автомобилями. Здесь сеть должна обучаться также в непрерывном режиме. Для этого был разработан специальный алгоритм: Real-time recurrent learning – RTRL(h) основанный на вычислениях мгновенных градиентов. В некотором смысле это похоже на аналог обучения обычного персептрона в режиме одиночных наблюдений, когда веса связей корректируются после каждого предъявляемого входного вектора. Для тех, кто хочет углубиться в теорию алгоритма RTRL, могу опять же посоветовать книгу: Саймон Хайкин «Нейронные сети (полный курс)» На этом мы завершим начальный обзор рекуррентных НС. Конечно, мы здесь сделали только первый шаг в понимании работы таких сетей и не затронули некоторые другие важные архитектуры, например, LSTM и GRU Но, обо всем по порядку. Для начала разберемся с работой обычных RNN-сетей, а затем, перейдем к более сложным рекуррентным архитектурам. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |