|
Ускорение обучения, начальные веса, стандартизация, подготовка выборкиКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущем занятии мы познакомились с алгоритмом обучения back propagation, но рассмотрели его лишь в целом, чтобы мы с вами понимали принцип его работы. Теперь, пришло время немного погрузиться в детали этого процесса и узнать:
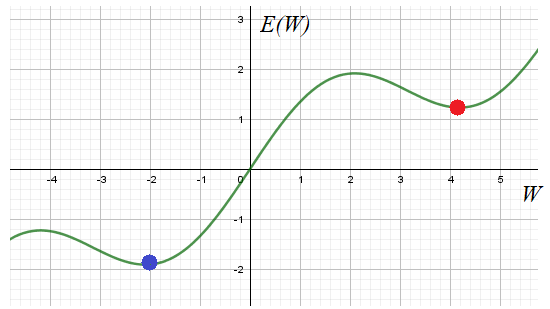
Без знания этих моментов, провести качественное обучение НС практически невозможно. Поэтому, для полноты картины, мне придется дать некоторый теоретический материал, чтобы вы могли ориентироваться в этих вопросах. Возможно, вам это покажется несколько скучным, но, знаете, яркие эффекты – это лишь вершина айсберга, в основании очень много подготовительного материала и кропотливой работы по проектированию и обучению сетей. Так что, если вы решили пойти по этому пути и начать работать в данной области, то без базовой математической подготовки, знания основных моментов и наработки опыта, тут никуда. Итак, начнем с основной «рабочей лошадки» - алгоритма обратного распространения, который базируется на алгоритме градиентного спуска. Но раз используется градиентный спуск, то мы сразу получаем все его проблемы реализации. Главная – это попадание в локальный минимум выбранного критерия качества E.
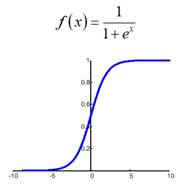
Общего решения этой проблемы нет. Поэтому на практике запускают алгоритм обучения с разными начальными значениями весовых коэффициентов. Тем самым мы, как бы выбираем разные отправные точки на функции E в надежде, что одно из решений достигнет глобального минимума. Хотя, точно узнать: достигли мы дна или нет не представляется возможным. Поэтому процесс обучения останавливают, если достигается требуемое качество работы НС. Отсюда получаем рекомендацию обучения №1: Запускать алгоритм для разных начальных значений весовых коэффициентов. И, затем, отобрать лучший вариант. Начальные значения генерируем случайным образом в окрестности нуля, кроме тех, что относятся к bias’ам. У вас может возникнуть вопрос: почему начальные значения весов нужно брать малыми? Смотрите, допустим, используется логистическая функция активации:
Если веса изначально буду значимыми, то часто суммарный сигнал на входе нейронов будет оказываться большим по модулю:
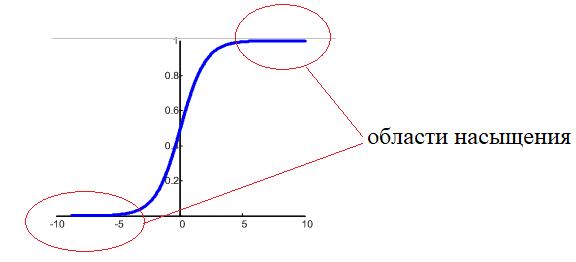
И мы попадаем на пологий участок функции активации. К чему это потом приводит? В процессе обучения градиент этого участка будет мал, а значит, веса будут медленно изменяться, что приведет к торможению обучения НС в целом. Чтобы этого избежать, мы, как раз и выбираем веса с малыми случайными значениями, и оказываемся на более выгодном крутом участке кривой. Bias же (смещения разделяющих гиперплоскостей) могут быть и с большими значениями, т.к. они отвечают именно за смещение разделяющей гиперплоскости и оно может быть значительным. Другая проблема градиентных алгоритмов – медленная сходимость на пологих участках функции:
Для ее решения было предложено множество подходов. Среди них наиболее известные, следующие:
О первых двух я рассказывал на занятии по градиентному спуску: Почему так важно знать об этих методах оптимизации? Дело в том, что многие пакеты реализации и обучения НС, например, Keras или TFLearn позволяют использовать их для ускорения и улучшения обучения. Чаще всего применяется оптимизация по Нестерову и Adam’у. Позже, когда мы будем рассматривать один из этих пакетов, я покажу где и как настраиваются эти параметры. Итак, рекомендация обучения №2: Запускаем алгоритм обучения с оптимизацией по Adam или Нестерову для ускорения обучения НС. Входные значенияПредположим, что у нас имеется обучающая выборка с N наблюдениями:
Стоит ли нам
подавать значения
Поэтому на практике выполняют предварительную стандартизацию входных значений, например, по формуле:
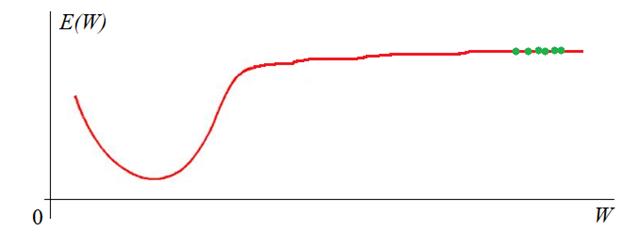
Здесь max, min – максимальное и минимальное значения входных данных по всему обучающему множеству. В результате, входные данные при обучении будут находиться в диапазоне от 0 до 1. И здесь начинающие нейронщики часто делают одну важную ошибку. После обучения НС в режиме ее эксплуатации забывают о нормализации данных на ее входах. Раз уж сеть обучена на нормированных значениях, то и потом, при ее непосредственной работе, данные также нужно нормировать. Об этом забывать не стоит. И, кроме того, нормировку следует делать через те же самые параметры min и max, которые были использованы в обучающей выборке! А не пересчитывать их заново! Рекомендация обучения №3: Выполнять нормировку входных значений и запоминать нормировочные параметры min, max из обучающей выборки. Как создавать и подавать обучающую выборкуСледующий важный вопрос: что из себя должна представлять обучающая выборка? Какие данные в нее следует поместить? Ответить можно так: чем больше разных наблюдений будет при обучении, тем выше качество работы сети. Здесь ключевое слово – разных, то есть, выборка должна охватывать самые разные «ситуации» в процессе обучения и эти «ситуации» должны появляться с равной частотой. Например, представьте, что вы учитесь водить машину, но ваш инструктор выбирает перекрестки только со светофором. Как думаете, сможете вы себя потом уверенно чувствовать на нерегулируемых перекрестках? Вряд ли. Я бы не смог. С нейросетью также: если в процессе эксплуатации будут попадаться входные данные, сильно отличающиеся от обучающей выборки, то высока вероятность возникновения ошибки. Или, другой пример. Ваш инструктор для «галочки» лишь показал как проезжать нерегулируемые перекрестки, но вы все равно, в основном проезжали по регулируемым со светофором. Здесь качество обучения также будет невысоким, т.к. навыка проезда обычных перекрестков будет недостаточно. Поэтому желательно, чтобы в обучающей выборке с равной частотой встречались самые разные данные, описывающие какие-то характерные, особенные, частные ситуации. Рекомендация обучения №4: Помещать в обучающую выборку самые разнообразные данные примерно равного количества. Хорошо, с этим разобрались, но какой объем обучающей выборки N следует брать? По идее, чем больше, тем лучше. Например, в литературе отмечают, что при классификации картинок (например, на мужчин и женщин, или кошек и собак и т.п.) необходимо по 5 000 000 наблюдений для каждого класса, тогда можно достичь хороших результатов различения. Если увеличить этот объем до 10 000 000, то есть шанс обучить нейросеть распознавать образы лучше человека. Вас, возможно, удивят такие большие цифры? Да, это так, данные для обучения – это как нефть «черное золото» для нашей экономики, они ценятся очень высоко, а их подготовка может потребовать немалых ресурсов и времени. Это еще одна причина, по которой нейронные сети лишь недавно завоевали свое место под солнцем: раньше практически невозможно было получить столько реальных данных. Теперь же, сеть Интернет, в частности, социальные сети, предоставляют весьма богатый материал. Итак, предположим, что мы создали обучающую выборку и собираемся приступить к обучению. Здесь возникает новый вопрос: как ее подавать на вход сети? В самом простом варианте, мы сначала перемешиваем наблюдения в выборке (чтобы они шли в случайном порядке), а затем поочередно подаем на вход. При этом для каждого наблюдения выполняем корректировку весовых коэффициентов. Именно так мы делали на предыдущем занятии. Но это не самый лучший вариант. Было замечено, что в процессе обучения часть наблюдений дают небольшой положительный прирост весовых коэффициентов, часть – небольшой отрицательный. В сумме они практически компенсируют друг друга и изменение весов практически не происходит. И лишь некоторая часть наблюдений из выборки приводит к их заметному изменению. Чтобы не «крутить» вхолостую весовые коэффициенты, коррекцию выполняют не сразу для каждого наблюдения, а после прогонки через сеть некоторого их количества. Такое множество получило название batch или, в последнее время чаще стали говорить mini-batch. А вся выборка получила название эпоха. Так вот, прогоняя mini-batch через сеть, суммируют локальные градиенты на каждом нейроне (я думаю вы помните, что это такое из предыдущего занятия), а затем, корректируют веса по результирующей их сумме. В процессе такого суммирования небольшие положительные и отрицательные значения будут скомпенсированы и останется полезное смещение, которое и приведет к изменению весов в пределах mini-batch. Такая идея позволила сократить время обучения в разы, что очень важно, так как для больших НС общее время обучения составляет иногда дни, недели и даже месяцы. Поэтому сокращение этого времени в несколько раз открывает новые горизонты применения НС. Когда целесообразно разбивать выборку на серию mini-batch? Считается, что для этого общее число выборки должно составлять от нескольких тысяч и более. Если наблюдений меньше, порядка тысячи, то ее можно воспринимать как один единственный mini-batch. Итак, мы получаем рекомендацию обучения №5: Наблюдения на вход сети подавать случайным образом, корректировать веса после серии наблюдений, разбитых на mini-batch. Значение критерия качества вычисляется только после прогонки всей эпохи. Если оно нас не устраивает (как правило, так и есть), то наблюдения снова тасуются случайным образом и обучение продолжается. В конце каждой эпохи снова и снова пересчитывается критерий качества. Получается такой график:
Конечно, это идеализированный график. В реальности он, конечно, не такой гладкий и монотонный. Нередки случаи когда он может внезапно возрастать. Но об этом мы поговорим в другой раз. На следующем продолжим рассматривать эти, достаточно важные вопросы, без знания которых начинать работать с нейросетями не имеет особого смысла. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |