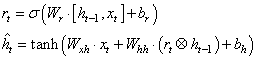|
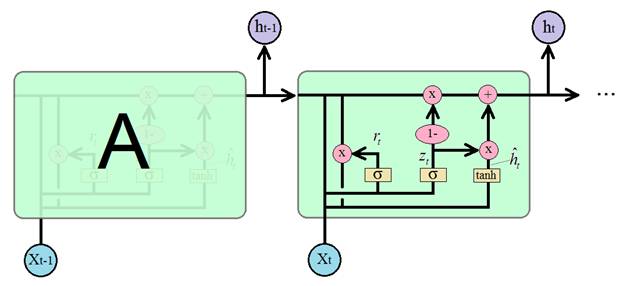
Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализаКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущих занятиях мы с вами познакомились с популярной рекуррентной архитектурой LSTM. Она эффективна при анализе долгосрочного контента, но имеет один существенный недостаток – большое число настраиваемых параметров (весовых коэффициентов). Это приводит к большим затратам памяти и длительному процессу обучения таких сетей. Поэтому в 2014 году было предложено упрощение LSTM, которое стало известно под названием управляемые рекуррентные блоки: Gated Recurrent Units (GRU) По эффективности блоки GRU сравнимы с LSTM во многих практических задачах: моделирования музыкальных и речевых сигналов, обработка текста и так далее. Существует несколько вариантов этого блока и, как всегда, мы рассмотрим их классическую архитектуру:
Работа этого
блока (ячейки) похожа на блок LSTM только здесь долгосрочный элемент
памяти реализован не отдельным каналом, а в самом векторе скрытого состояния
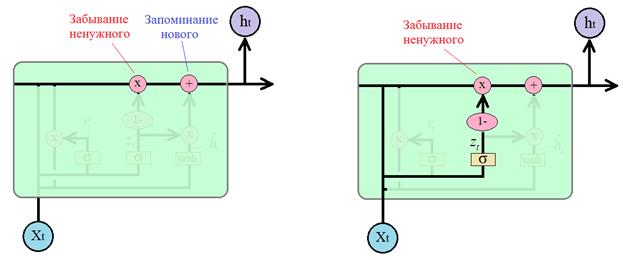
Для определения что забыть, а что оставить, используется вектор
который, затем,
поэлементно вычитается из 1 и умножается на вектор предыдущего состояния
Почему мы здесь делаем это вычитание? Чтобы противоположную информацию использовать как маркер для добавления нового в соседней ветке. Если ее полностью расписать, то получится следующая операция:
И вычисленная
величина добавляется как то, что нужно «запомнить» в векторе скрытого состояния
для следующей итерации. В итоге, вычисление
Эта формула и определяет принцип работы ячейки GRU. Если кто из вас знаком с калмановской фильтрацией случайных сигналов: Формула очень похожа на реализацию фильтра Калмана в дискретном времени. В некотором смысле она работает по этому же принципу: отбрасывает случайные (незначительные) детали и сохраняет главное (важное). Какую же сеть LSTM или GRU выбирать для практического применения? Все зависит от поставленной задачи, но общая рекомендация такая: сначала лучше воспользоваться сетью GRU, так как она быстрее обучается и если точность решения задачи оказывается недостаточной, то есть смысл попробовать сеть LSTM. Общим преимуществом сетей LSTM и GRU является решение проблемы исчезающего градиента, характерная для простейшей рекуррентной НС, когда при увеличении числа итераций величина градиента стремится к нулю. В LSTM и GRU благодаря наличию ячейки памяти (возможности хранения долгосрочного контента) градиент не уходит ниже определенного уровня, так как он поддерживается значением сигнала сохраняемого контента. В Keras рекуррентный слой из ячеек GRU формируется подобно ранее рассмотренному LSTM слою. Для этого используется класс: keras.layers.GRU(units, …) в котором первый обязательный параметр units определяет число нейронов внутри GRU ячейки:
Подробное описание параметров GRU слоя в Keras смотрите на странице русскоязычной документации: https://ru-keras.com/recurrent-layers/ Модель сети из предыдущего занятия для сентимент-анализа коротких текстов, можно записать в следующем виде: model = Sequential() model.add(Embedding(maxWordsCount, 128, input_length = max_text_len)) model.add(GRU(128, return_sequences=True)) model.add(GRU(64)) model.add(Dense(2, activation='softmax')) model.summary() Как видите, на уровне Keras это делается элементарно: вместо класса LSTM пишется класс GRU и все. Одним из общих недостатков блоков LSTM и GRU является их переобучение. Так как каждая ячейка содержит большое число нейронов, то сеть, на их основе также получается большой. А это, как мы знаем, прямой путь к переобучению. Чтобы этого избежать, во-первых, нужно контролировать этот эффект по выборке валидации. И, во-вторых, применять инструменты: Dropout и Batch Normalization для его предотвращения. Причем, в Keras Dropout можно использовать и для внутренних слоев ячеек, определяя следующие параметры классов LSTM и GRU:
По умолчанию оба параметра равны нулю (Dropout отключен). Также можно использовать Dropout между рекуррентными слоями. Инструмент Batch Normalization используется только между слоями (внутри ячеек он не применяется). Я, надеюсь, теперь у вас сложилось представление как работают блоки LSTM и GRU и как их применять на практике. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |