|
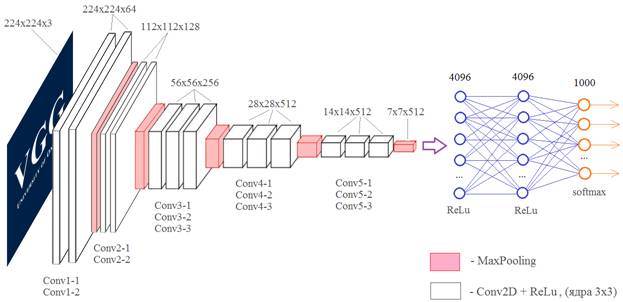
Примеры архитектур сверточных сетей VGG-16 и VGG-19Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии рассмотрим две довольно популярные архитектуры СНС от компании Visual Geometry Group: VGG-16 и VGG-19 разработанные для распознавания объектов на изображениях. В 2014-м году сеть VGG-16 на соревнованиях по распознаванию изображений базы ImageNet достигла небывалой на тот момент точности в 92,7%. И по этому показателю почти сравнялась с человеком. Теперь она выложена в открытом доступе (причем, с обученными весовыми коэффициентами), чтобы каждый желающий мог проводить с ней любые эксперименты. Итак, общая структура сети VGG-16, следующая:
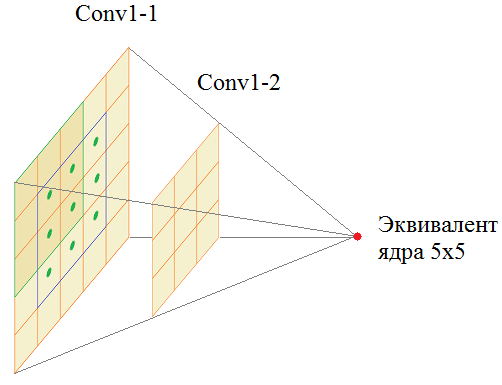
На вход подает полноцветное изображение с тремя каналами: RGB. Затем, оно последовательно проходит через сверточные слои Conv1-1 и Conv1-2, каждый имеет по 64 фильтра с размером ядер 3х3. Далее, операция MaxPooling уменьшает вдвое линейные размеры карт признаков и результат обрабатывается двумя последовательными слоями Conv2-1 и Conv2-2 со 128 фильтрами с тем же размером ядер 3х3. И так далее. Потом через три сверточных слоя все проходит, потом еще через три. Результирующий тензор размером 7х7х512 подается на полносвязную НС с 4096 нейронами двух скрытых слоев и 1000 нейронами выходного слоя. Число 1000 соответствует количеству классов, на которые эта сеть была обучена. У вас может возникнуть вопрос: а зачем здесь ставится подряд два, а то и три сверточных слоя? Почему нельзя обойтись одним? На самом деле можно. Вместо первых двух слоев Conv1-1 и Conv1-2 с ядрами 3х3 пикселя можно использовать один эквивалентный слой с ядрами 5х5 пикселей:
Хорошо, но тогда почему бы один такой слой и не использовать вместо двух? Дело в том, что число параметров у ядра 5х5 равно:
(здесь +1 – это биас). А у двух ядер 3х3:
То есть, два подряд идущих сверточных слоя имеют меньше настраиваемых параметров, чем один с ядром 5х5. Это основанная причина их использования в архитектуре сети VGG-16. Я думаю, вам теперь понятна вся структура этой сети. В краткой записи она выглядит так:
Во втором столбце представлена аналогичная архитектура сети VGG-19. Как вы уже догадались, здесь числа 16 и 19 означают общее количество слоев в нейронной сети. Преимуществом этих сетей является их относительная простота. А недостатком – медленная скорость обучения и большое количество весовых коэффициентов. Если их все сохранить на диск, то получится объем примерно 533 МБ. Реализация VGG-сетей в KerasПакет Keras содержит в своем составе обе сверточные сети: VGG16 и VGG19. Для их подключения в своем проекте нужно обратиться к соответствующим классам по ветке:
Их синтаксис схож и содержит следующие параметры: tf.keras.applications.VGG16( include_top=True, weights="imagenet", input_tensor=None, input_shape=None, pooling=None, classes=1000, classifier_activation="softmax", )
Остальные параметры используются редко и оставляются по умолчанию. При создании экземпляра класса создается заданная модель СНС с VGG структурой. Давайте для примера воспользуемся этой сетью и выполним распознавание случайно выбранного изображения размером 224x224 пикселей:
import numpy as np import matplotlib.pyplot as plt from tensorflow import keras from google.colab import files from io import BytesIO from PIL import Image model = keras.applications.VGG16() uploaded = files.upload() img = Image.open(BytesIO(uploaded['ex224.jpg'])) plt.imshow( img ) # приводим к входному формату VGG-сети img = np.array(img) x = keras.applications.vgg16.preprocess_input(img) print(x.shape) x = np.expand_dims(x, axis=0) # прогоняем через сеть res = model.predict( x ) print(np.argmax(res)) Вначале подключаем необходимые пакеты, затем, создаем модели сети VGG16 с параметрами по умолчанию. Загружаем файл изображения. Здесь метод preprocess_input преобразовывает изображение из формата RGB в формат BGR (на котором обучалась сеть VGG-16) и, кроме того, уменьшает средние значения каждого цветового канала на величины: (B) 103.939, (G) 116.779 и (R) 123.68 Затем, добавляем нулевую ось, чтобы получить формат входных данных: (batch_size, height, width, channels) И пропускаем через НС. Максимальное значение соответствует 817 нейрону, что в соответствии с базой изображений ImageNet, означает 817: 'sports car, sport car' Полную классификацию можно посмотреть здесь: https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a Получилось неплохо, учитывая, что это совершенно случайное изображение и на нем много других элементов помимо самой машины. В целом, она себя показала хорошо. Аналогично можно попробовать сеть VGG19, но это будет уже домашним заданием, для тех, кому интересно провести свои небольшие исследования. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме | ||||||||||||||||||||||||||||||||