|
Оптимизаторы в Keras, формирование выборки валидацииКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На этом занятии вы узнаете какие оптимизаторы алгоритма градиентного спуска имеются в пакете Keras и как разбивать обучающее множество на собственно обучающее и выборку валидации. Вообще, когда мы собираемся решать задачу с помощью НС, то каждый раз, приходится определяться:
И некоторыми другими, более простыми и очевидными параметрами. Про структуру мы с вами уже говорили – это интуитивный выбор разработчика нейросети. Критериям качества также было посвящено одно из прошлых занятий курса и общие ориентиры у вас должны сложиться. А вот про доступные методы оптимизации и способах формирования выборки валидации следует рассказать поподробнее. До сих пор мы с вами использовали оптимизацию алгоритма градиентного спуска по Adam (это наиболее частый выбор) и указывали его в параметрах компиляции НС: model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) В этом случае все остальные параметры, например, шаг сходимости (лямбда) и другие, устанавливаются по умолчанию. Если же мы хотим дополнительно переопределять их, то следует сначала создать нужный оптимизатор, с помощью класса, расположенного в ветке: keras.optimizers Например, для Adam это будет выглядеть так: myAdam = keras.optimizers.Adam(learning_rate=0.1) А, затем, передать ссылку на него параметру optimizer: model.compile(optimizer=myAdam, loss='categorical_crossentropy', metrics=['accuracy']) Чтобы узнать обо всех возможных параметрах оптимизатора Adam, можно обратиться, либо к официальной документации: https://keras.io/api/optimizers/adam/ либо к хорошему переводу на русский язык: https://ru-keras.com/optimizer/ В частности здесь отмечены все возможные способы оптимизации в Keras:
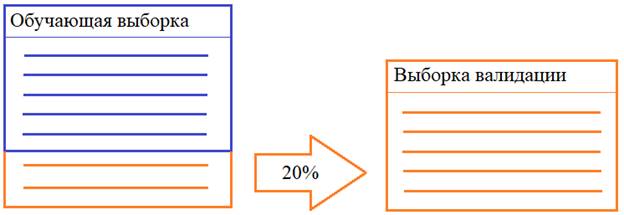
Как не потеряться во всем этом многообразии? На практике чаще всего начинают с оптимизации по Adam (для большинства задач он приводит к хорошим решениям). Но если нужное качество не достигается, то пробуют другие. Обычно, следующим выбирают алгоритм SDG с нестеровским моментом. Для его активации, нам нужно в программе создать экземпляр класса: myOpt = keras.optimizers.SGD(learning_rate=0.1, momentum=0.0, nesterov=True) Здесь мы указываем шаг сходимости, момент для ускорения перемещения градиента (в данном случае 0 – без ускорения) и определяем использование нестеровского момента. Далее, при компиляции мы должны передать ссылку на этот экземпляр: model.compile(optimizer=myOpt, loss='categorical_crossentropy', metrics=['accuracy']) Так можно выбрать любой из доступных оптимизаторов и оценить их вклад в процесс обучения. Если вы хотите подробнее познакомиться с оптимизацией на основе моментов, то смотрите занятие по градиентному спуску: Способы формирования выборки валидацииСледующий важный момент – это способ формирования выборки валидации. С одним из них мы с вами уже познакомились на занятии по распознаванию цифр, когда запускали процесс обучения с параметром validation_split: model.fit(x_train, y_train_cat, batch_size=32, epochs=5, validation_split=0.2) В этом случае вначале обучения из обучающего множества случайным образом выбирается 20% наблюдений для выборки валидации, оставшиеся образуют, собственно, обучающую выборку:
Плюсы этого подхода: автоматическое и случайное разбиение выборки на обучающую и проверочную и нам не нужно сильно «заморачиваться» для их формирования. Недостаток: отсутствие доступа к конкретным наблюдениям этих выборок, т.к. мы не знаем какие из них были отобраны для валидации, а иногда, это важно. Другой способ – это вручную создать выборку валидации. Например, из 60 000 изображений обучающего множества – 10 000 отберем для проверки качества обучения сети. Это можно реализовать так: size_val = 10000 # размер выборки валидации x_val_split = x_train[:size_val] # выделяем первые наблюдения из обучающей выборки y_val_split = y_train_cat[:size_val] # в выборку валидации x_train_split = x_train[size_val:] # выделяем последующие наблюдения для обучающей выборки y_train_split = y_train_cat[size_val:] И, затем, запустить процесс обучения с этими множествами: model.fit(x_train_split, y_train_split, batch_size=32, epochs=5, validation_data=(x_val_split, y_val_split)) Здесь мы уже четко знаем, что именно попадает в выборку валидации, но каждую эпоху будем использовать одни и те же наблюдения в этих выборках – они не будут перемешиваться между собой, как в предыдущем случае. И получаем больше шансов адаптации весовых коэффициентов сети именно под эти данные. Что не есть хорошо. Наконец, третий вариант – это воспользоваться довольно удобной функцией: sklearn.model_selection.train_test_split пакета sklearn. В нем множество полезных реализаций алгоритмов для машинного обучения и в частности имеется вот такая функция для формирования обучающей и проверочной выборок. Разумеется, чтобы воспользоваться этим пакетом его нужно установить: pip install sklearn И, затем, импортировать в нашу программу: from sklearn.model_selection import train_test_split После этого, можно вызвать функцию для разделения исходного обучающего множества на два: x_train_split, x_val_split, y_train_split, y_val_split = train_test_split(x_train, y_train_cat, test_size=0.2) Плюс этой функции в том, что она автоматически случайным образом выделит 20% наблюдений и поместит их в выборку валидации, а остальные – в обучающую. И, далее, можно вызвать процесс обучения, указав эти множества: model.fit(x_train_split, y_train_split, batch_size=32, epochs=5, validation_data=(x_val_split, y_val_split)) В результате, мы получаем плюсы обоих подходов: знаем, что попало в выборки и они сформированы случайным образом. Часто, на практике используют именно такой подход. Вот так в Keras выполняется формирование выборок и оптимизация алгоритма градиентного спуска. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |