|
Как рекуррентная нейронная сеть прогнозирует символыКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущем занятии мы в целом познакомились с рекуррентными НС. Давайте теперь сделаем следующий шажок и построим с помощью пакета Keras простую рекуррентную НС, на вход которой будем подавать отдельные символы, а на выходе она будет строить прогноз следующего символа. В качестве обучающей выборки возьмем вот такой заготовленный файл с короткими высказываниями (train_data_true). Затем, нужно определиться: как представлять входные данные при работе с текстовой информацией? Предположим, что изначально у нас есть набор неких высказываний:
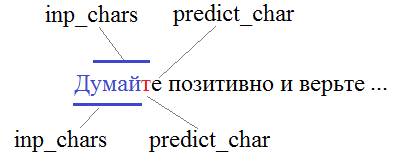
И так далее. Мы можем просматривать этот текст (последовательно брать из него inp_chars символов) и прогнозировать следующий:
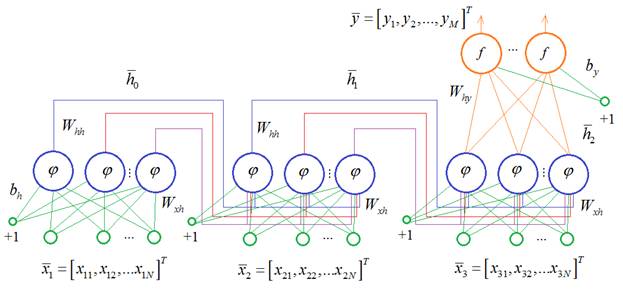
И, чтобы было проще решать эту задачу, оставим в тексте только символы русских букв и символы пробела: with open('train_data_true', 'r', encoding='utf-8') as f: text = f.read() text = text.replace('\ufeff', '') # убираем первый невидимый символ text = re.sub(r'[^А-я ]', '', text) # убираем все недопустимые символы То есть, всего у нас будет 34 разных символа: num_characters = 34 #33 буквы + пробел Отлично, это сделали. Далее, нам нужно решить: в каком формате подавать эти символы на вход рекуррентной НС? Общий вид нашей сети (развернутой во времени) будет следующий:
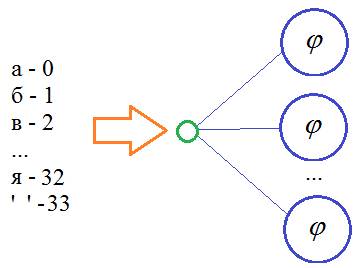
Здесь как пример показано, что последовательно подаются три символа (inp_chars = 3), а затем, на выходе формируется прогноз следующего (четвертого) символа. Имеем рекуррентную сеть вида: Many to One И здесь вопрос: что из себя представляют входные векторы и выходной вектор? Первое, что приходит в голову – это каждому символу поставить в соответствие некое число и эти числа подавать на вход сети:
Это значило бы, что у нас есть один вход, который весовыми коэффициентами связан с нейронами скрытого слоя. Такая модель будет плохо различать символы, так как НС сложно интерпретировать числа как отдельные буквы. Гораздо лучшим решением будет связать строго определенный вход со строго определенным символом:
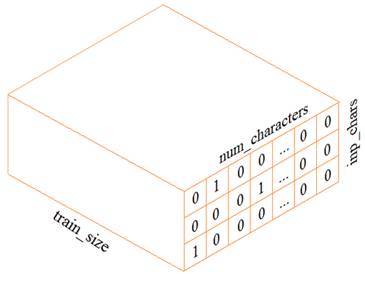
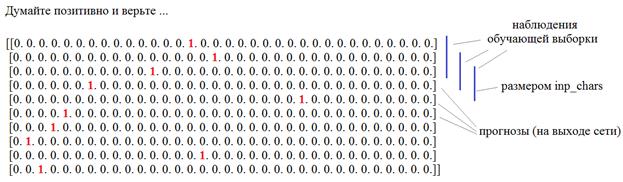
Здесь мы на вход подаем вектор длиной 34 элемента с единицей на месте нужного символа. В этом случае, НС сможет сформировать весовые коэффициенты независимо для каждой буквы, что гораздо лучше для их различения. Такое кодирование данных получило название: One-hot encoding (OHE) Именно его мы и будем использовать для представления входных символов. Выходной вектор также будет иметь этот формат, то есть, 34 выходных нейрона с функцией активации softmax. В результате, набор данных обучающей выборки будет иметь вид трехмерного тензора:
Из этого
представления хорошо видно, что для формирования одного выходного вектора Настало время создать такую обучающую выборку. Мы ее будем формировать с помощью инструмента: tf.keras.preprocessing.text.Tokenizer который делает «умный» парсинг (разложение на составляющие элементы) указанного текста. Официальную документацию по нему можно посмотреть на странице: https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer Чтобы им воспользоваться, сначала нужно создать экземпляр класса Tokenizer, который имеет следующие важные параметры:
В нашем случае мы его определим так: num_characters = 34 #33 буквы + пробел tokenizer = Tokenizer(num_words=num_characters, char_level=True) И пропустим через него загруженный текст: tokenizer.fit_on_texts(text) В итоге, формируется словарь: print(tokenizer.word_index) где каждому символу поставлен в соответствие свой уникальный индекс: {' ': 1, 'о': 2, 'е': 3, 'т': 4, 'и': 5, 'а': 6, 'н': 7, …} В дальнейшем нам это пригодится, когда мы прогнозируемое значение будем переводить в символ. Конечно, мы легко могли бы этот словарь создать и самостоятельно, но здесь я хочу продемонстрировать универсальный инструмент, который также будем использовать и при парсинге слов, а там уже вручную это делать проблематично. Далее, преобразуем текст в набор OHE-векторов: inp_chars = 3 data = tokenizer.texts_to_matrix(text) На выходе получим следующую матрицу размерностью 6307 х 34:
Обратите внимание, здесь символы упорядочены не по алфавиту, а в соответствии со словарем tokenizer.word_index. Затем, из этой матрицы мы сформируем тензор обучающей выборки и соответствующий набор выходных значений. Для начала вычислим размер обучающего множества: n = data.shape[0]-inp_chars И, далее, сформируем входной тензор и прогнозные значения: X = np.array([data[i:i+inp_chars, :] for i in range(n)]) Y = data[inp_chars:] #предсказание следующего символа Отлично, данные для обучения готовы. Теперь создадим рекуррентную НС с помощью Keras в соответствии с архитектурой рисунка выше: model = Sequential() model.add(Input((inp_chars, num_characters))) model.add(SimpleRNN(500, activation='tanh')) model.add(Dense(num_characters, activation='softmax')) model.summary() Вначале мы должны отдельно создать входной слой Input, который для рекуррентных сетей имеет формат: (batch_size, inp_chars, num_characters) У нас тензор X как раз имеет такую размерность. Далее создаем рекуррентный слой с помощью класса SimpleRNN пакета Keras: keras.layers.SimpleRNN Документацию по нему можно посмотреть по ссылке: https://ru-keras.com/recurrent-layers/ Основные параметры, следующие (в порядке следования):
Остальные более специфичные и отдельно по ним смотрите документацию по ссылке. Итак, мы создаем рекуррентный слой с 500 нейронами и функцией активации гиперболический тангенс. Далее идет полносвязный выходной слой с 34 нейронами и функцией активации softmax. Все, вот так, довольно просто, мы описали модель нашей простой рекуррентной НС. Осталось скомпилировать ее и обучить по нашей выборке: model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam') history = model.fit(X, Y, batch_size=32, epochs=100) Здесь вам все
должно быть уже знакомо. С одним нюансом: внутреннее состояние рекуррентного
слоя Далее, объявим вспомогательную функцию, в которой будет выполняться прогноз очередного символа и добавления его в конец начальной строки: def buildPhrase(inp_str, str_len = 50): for i in range(str_len): x = [] for j in range(i, i+inp_chars): x.append(tokenizer.texts_to_matrix(inp_str[j])) # преобразуем символы в One-Hot-encoding x = np.array(x) inp = x.reshape(1, inp_chars, num_characters) pred = model.predict( inp ) # предсказываем OHE четвертого символа d = tokenizer.index_word[pred.argmax(axis=1)[0]] # получаем ответ в символьном представлении inp_str += d # дописываем строку return inp_str Ей на вход подается начальная строка длиной inp_chars символов и, затем, она подается на НС и прогнозируется следующий символ. Далее, мы используем это прогнозное значение и получаем следующее и так далее делаем str_len раз. Давайте посмотрим, что в итоге у нас получится: res = buildPhrase("утренн") print(res) Как видите, имеем некоторую попытку осмысленного формирования текста по символам: утрене позитивное вы собности вы собности вы собности В принципе, что то такое понятное вышло, причем этот текст сгенерирован посимвольно. Сеть даже пробелы расставила, а потом вышла в установившийся режим с повторяемыми фразами. Я привел этот пример больше для ознакомления, чтобы показать, как кодируется текстовая информация, как формируется обучающая выборка и как строится рекуррентная сеть в Keras. Если все эти моменты вам понятны, то цель этого занятия достигнута. На следующем мы сделаем еще один шаг и будем работать уже не с отдельными символами, а с целыми словами. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |