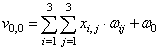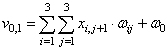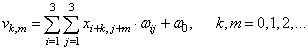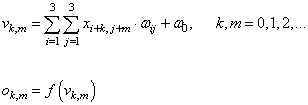|
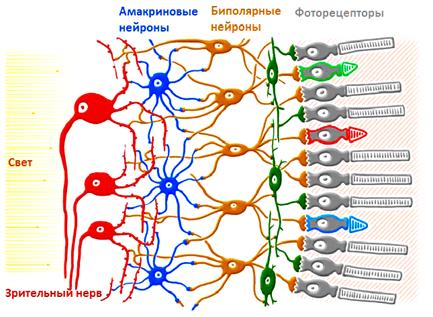
Как работают сверточные нейронные сетиКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Вы наверняка слышали, что НС способны решать задачи классификации графических образов (отличать кошку от собаки, самолет от автомобиля, мужчин от женщин и т.д.), делать стилизацию изображений, выполнять их раскраску, генерировать новые графические образы и делать много других интересных вещей с изображениями. И мы с вами научимся делать некоторые из этих эффектов. Так вот, когда речь заходит об обработке изображений, то используется особая архитектура НС – сверточные НС. По-английски звучит как: Convolutional Neural Networks (CNN) Изначально они были предложены Яном Лекуном и спроектированы для задач классификации графических образов. А началось все с того, что в 2012-м году команда Алекса Крижевски выиграла в ежегодном соревновании ImageNet по распознаванию графических образов. Их алгоритм показал точность в 83,6% правильной классификации – рекорд того времени. И этот рекорд был достигнут сверточной НС – AlexNet. Общая идея архитектуры таких сетей была подсмотрена у биологической зрительной системы. Ученые выяснили, что дендриды каждого нейрона соединяются не со всеми рецепторами сетчатки глаза, а лишь с некоторой локальной областью. И уже дендриды всей группы зрительных нейронов покрывают сетчатку глаза целиком:
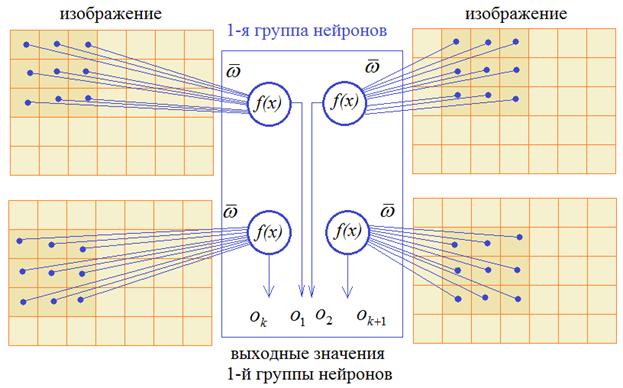
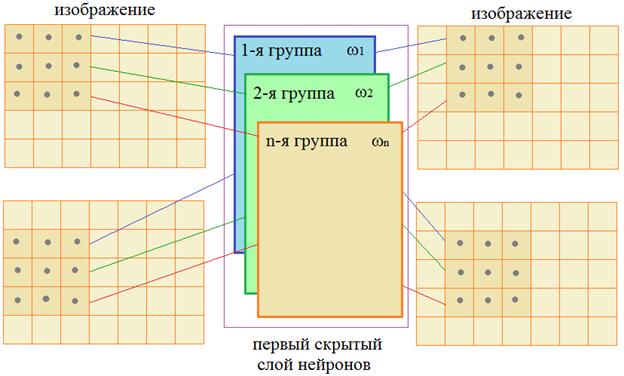
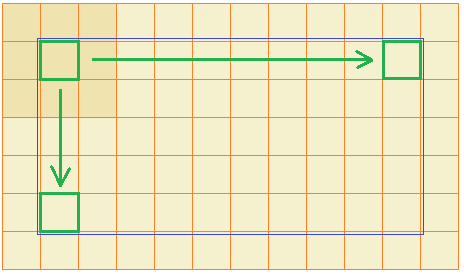
Математики обобщили эту структуру и предложили следующее решение. Входной сигнал изображения подается на вход нейрона только в пределах ограниченной области, как правило, квадратной, например, 3х3 пикселей. Затем, эта область смещается вправо на заданный шаг, допустим, 1 пиксель и входы подаются уже на второй нейрон. Так происходит сканирование всего изображения. Причем, весовые коэффициенты для всех нейронов этой группы – одинаковые. После этого сканирование изображения повторяется, но с другим набором весовых коэффициентов. Получаем вторую группу нейронов. Затем, третью, четвертую и в общем случае имеем n различных групп. Так формируется первый скрытый слой нейронов сверточной НС.
Давайте теперь подробнее посмотрим, что получается на входах нейронов каждой отдельной группы. Так как весовые коэффициенты в пределах группы не меняются, то фактически, мы имеем окно (в нашем примере его размер 3х3 пиксела) с набором определенных чисел:
Эти числа умножаются на значения соответствующих пикселей изображения и суммируются:
И, кроме того, у
каждой такой макси может быть еще один дополнительный параметр – bias (смещение),
обозначим его через
В общем виде для всего изображения сумму можно определить так:
То есть, перемещая это окно, весовые коэффициенты остаются неизменными и мы получаем общее число настраиваемых параметров для одной группы нейронов:
Соответственно, для n групп, получим:
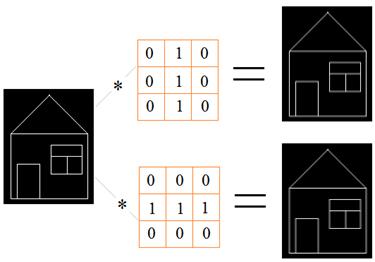
Так вот, в цифоровой обработке сигналов эта сумма называется сверткой, а окно с весовыми коэффициентами – импульсным откликом фильтра (или, ядром фильтра). В чем смысл такого фильтра? Давайте представим, что у нас имеется схематичное изображение дома и мы пропустим его через вот такие ядра:
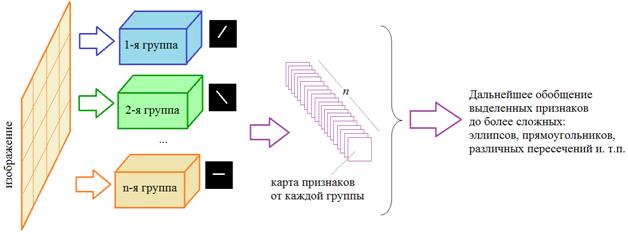
На выходе получаем отчетливые вертикальные линии в первом случае и горизонтальные – во втором случае. Все остальные линии стали более бледными. То есть, фильтр позволяет выделять характерные участки на изображении в соответствии с конфигурацией весовых коэффициентов. Благодаря такому подходу, нейроны каждой группы активизируются, когда на участке изображения появляется фрагмент, подходящий под их ядра:
И на выходе формируется набор карт признаков, которые называются каналами. Значимые величины в каждой карте показывают наличие признака в строго определенном месте изображения. Если таких признаков будет несколько (на разных участках изображения), то на выходе будут активироваться несколько нейронов, связанных с этими областями. Благодаря этому, следующие слои сверток могут обобщать найденные особенности до более сложных, например, эллипсов, прямоугольников, различных пересечений линий и т.п. Разумеется, значения карт признаков – это выходы функций активации нейронов, то есть, здесь, все как обычно: сумма (свертка) проходит через функцию активации и формируются выходные значения:
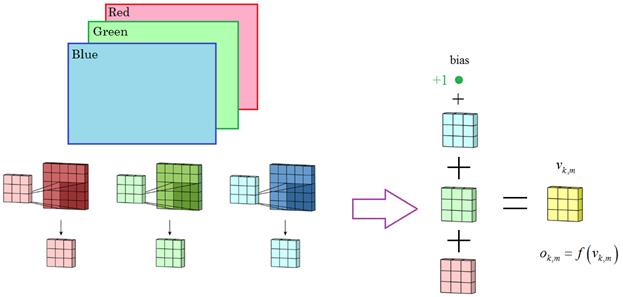
Надеюсь, что концепция каналов СНС в целом понятна. Но мы рассмотрели простейший вариант, когда на вход подавалось одноканальное изображение, например, в градациях серого. Если обрабатывается полноцветное изображение, представленное, например, тремя цветовыми компонентами RGB, то каждая цветовая компонента сначала преобразовывается своим отдельным, независимым ядром, затем, вычисленные карты признаков, складываются, к ним добавляется смещение и формируется единая итоговая матрица признаков, которая проходит через функцию активации нейронов и получаются выходные значения на соответствующем канале.
Вот так выглядит обработка полноцветных изображений на первом скрытом слое СНС. Последующие слои работают по такому же принципу, только вместо цветовых каналов RGB, выполняется уже обработка каналов из карт признаков, сформированных на предыдущем слое. И последний важный момент. Смотрите, после обработки исходного изображения каждый канал, фактически, формирует новое изображение немного меньшего размера:
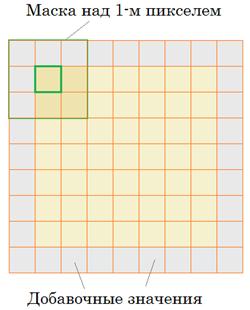
Если изначально было изображение, например, 128x128 пикселей, то на каждом канале будет формироваться карта признаков, размером: 128-2 х 128-2 = 126х126 Это не самый лучший вариант. Нам бы хотелось иметь выходной размер, равный входному. Для этого, центр маски преобразования следует поместить над самым первым пикселом изображения, а ячейки ядра, выходящие за границы, заполнять некоторыми значениями, часто нулевыми:
Тогда выходные размеры карты признаков будут в точности равны исходным размерам изображения (конечно, если шаг смещения маски равен один пиксел). Если шаг смещения (stride) увеличить и сделать равный 2, то выходные размеры карты признаков на каждом канале будут в 2 раза меньше размеров исходного изображения: 128:2 х 128:2 = 64 х 64 Какой именно шаг выбирать – зависит от конкретной решаемой задачи и желаний разработчика архитектуры СНС. Четких рекомендаций здесь нет. Pooling (изменение масштаба)Хорошо, как работают сверточные слои мы разобрали. И знаем, что на выходе первого слоя формируется набор карт признаков. Что дальше? А дальше мы предполагаем анализировать вычисленные признаки на более крупном масштабе. Для этого размерность карт признаков сокращают с помощью одной из операций:
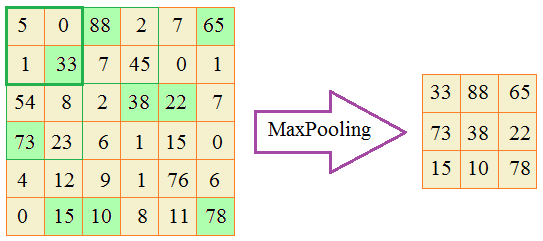
О чем здесь речь? Давайте представим, что мы хотим вдвое уменьшить линейные размеры карты признаков. В этом случае ее можно покрыть непересекающимися блоками 2х2 пиксела и в каждом блоке оставить только максимальные значения:
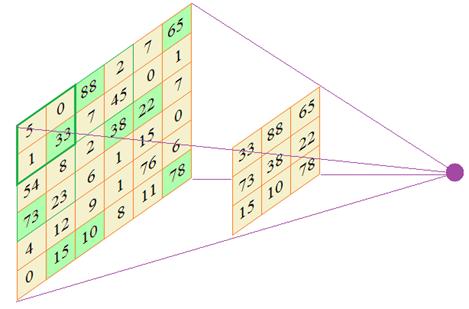
Эта операция и называется MaxPooling. Для ее реализации необходимо задать два параметра: размер окна и шаг сканирования. В нашем случае окно имело размер 2х2 и шаг 2 пиксела. Вот пример применения операции MaxPooling на реальном изображении:
По аналогии работают MinPooling и AveragePooling. И, все же, какую роль играет эта операция в СНС? Как мы говорили, наша цель выполнять анализ вычисленных признаков на более крупном масштабе. Именно это дает нам операция Pooling. Смотрите, если на следующем сверточном слое анализировать выделенные максимальные значения ядрами 3х3, то это эквивалентно обработке максимальных значений карты признаков, но уже в области размером 6х6:
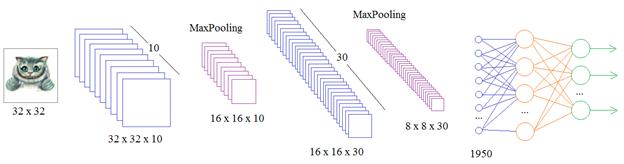
В результате получаем анализ данных на более крупном масштабе и благодаря этому, нейроны следующего слоя способны выделять более общие признаки на изображении. Я здесь в качестве примера привел операцию MaxPooling и это неслучайно. Дело в том, что, как правило, большие значения соответствуют наличию определенного признака, а малые – его отсутствию. Поэтому, отбирая максимальные числа, мы, тем самым, отбираем найденные признаки и сохраняем их для дальнейшего анализа на более крупном масштабе. Именно операция MaxPooling, в основном, используется в СНС при анализе изображений. Итоговая архитекрутраДавайте теперь подытожим изложенный материал и посмотрим на общую архитектуру СНС. Для простоты положим, что на вход подается изображение размером 32 x 32 пиксела и оно проходит через 10 каналов первого скрытого слоя:
На выходе получаем набор значений в виде тензора размерностью 32х32х10 элементов. Далее, применяется операция MaxPooling для перехода на более крупный масштаб. Следующий слой имеет уже 30 различных фильтров, каждый, состоящий из 10 ядер, для обработки 10 каналов предыдущего слоя. На выходе получаем тензор размерностью 16х16х30. Снова выполняем операцию MaxPooling и сокращаем размерность до 8х8х30. Такие преобразования можно продолжать и далее, пока каждый выходной сегмент не станет размером в 1 пиксел. Или же можно остановиться на любом этапе преобразования и подать вычисленные карты признаков на вход обычной полносвязной сети. Конечный этап СНС в задачах классификации, обычно, завершается полносвязной сетью, на выходе которой получаем вероятности принадлежности к тому или иному классу. Вот так, в целом, строятся СНС. На этом мы завершим это занятие, а на следующем посмотрим как реализуются СНС в пакете Keras и к каким результатам распознавания рукописных цифр они приводят. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |