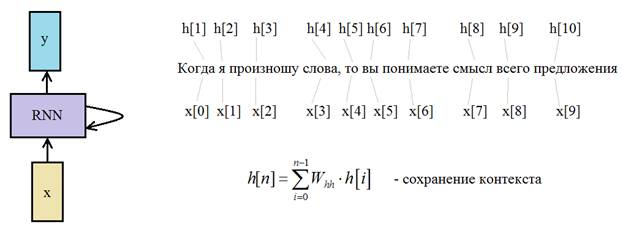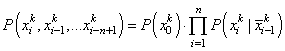|
Как работают RNN. Глубокие рекуррентные нейросетиКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs На предыдущих занятиях мы с вами рассмотрели простейшие реализации рекуррентных НС. Но остается вопрос: как и почему эти сети работают? Что дают их обратные связи, другими словами, что дает рекуррентность?
Смотрите,
простой пример. Когда я произношу слова, то вы понимаете смысл всего
предложения, потому что запоминаете, что было сказано вначале и, что в конце.
Весь этот поток, проходя через нашу биологическую НС, осмысливается благодаря
схватыванию всего этого контекста целиком. Именно за счет рекурсии текущее
состояние сети электрический ток, пушистый кот, круглый стол и т.п. то сеть способна
на основе текущего контекста
Здесь коэффициент k – это, по сути, число выходных нейронов, то есть, сеть может сделать прогноз для различных k элементов (например, символов или слов). Затем, мы выбираем наиболее вероятное значение:
которое и является прогнозом сети. Так как число итераций в рекуррентных слоях конечно, то прогноз строится по конечному числу входных данных. Обозначим их через вектор длиной M, например, так:
Тогда для каждого вектора состояний на выходе сети будем получать условные вероятности:
Это есть не что иное, как вероятности переходов цепи Маркова. А вероятность для всей последовательности можно записать в виде:
То есть, НС на основе обучающей выборки формирует статистику зависимостей следующего элемента от вектора текущего состояния. Причем, делает это для всех своих M выходов. Ну хорошо, но что нам это дает? Если кто из вас смотрел занятие по марковским процессам (ссылка на него будет под этим видео: https://youtu.be/t8JQywTdW7o) уже знает, что движение любого объекта в пространстве описывается этой моделью. Значит, рекуррентные НС можно применять для прогнозирования положения объекта в следующий момент времени, а это важный элемент в системе автоматического управления. Вы, наверное, слышали о беспилотных автомобилях. Так вот, там как раз применяются рекуррентные сети (в числе прочих). Но раз рекуррентность можно представить цепями Маркова, то почему бы непосредственно их не использовать на практике? Зачем городить огород, строить и обучать НС? Давайте представим себе, что мы делаем «умную клавиатуру», которая бы прогнозировала следующее слово на основе ранее введенных.
Если строить прогноз самого вероятного следующего слова на основе одного введенного, то потребуется число записей, равное размеру словаря. Для простоты положим, что словарь состоит из 100 слов. Значит, записей в БД будет ровно 100:
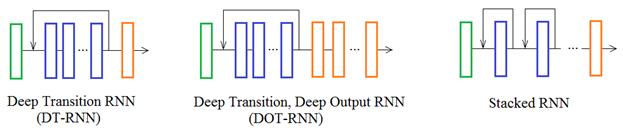
Если прогноз делать по двум предыдущим словам, то число вариантов возрастает до 100 х 100 = 10 000 Три предыдущих слова – еще больше: 100 х 100 х 100 = 1 000 000 И это всего для словаря из 100 слов! То есть, на практике такие модели могут учитывать совсем небольшой прошлый контекст 1-2 слова. В отличие от рекуррентных НС. Для больших объемов данных они позволяют сохранять эти статистики в гораздо более компактной форме через свои весовые коэффициенты. И работать с более длинным контекстом без чрезмерных затрат по памяти и времени обработки входных данных. В этом одно из ключевых преимуществ рекуррентных сетей перед классическими алгоритмами. Число архитектур рекуррентных НС огромное множество, самых разных конфигураций. Наиболее известные (из однонаправленных), построенных на основе простейшей рекуррентной сети, следующие:
Такие архитектуры можно отнести к глубоким рекуррентным сетям, так как они содержат более одного рекуррентного слоя, обычно 3-4, максимум 7-8, так как сильно возрастает их время обучения. В принципе, все эти архитектуры (и даже их комбинации) можно реализовать в Keras. Для примера рассмотрим последнюю – Stacked RNN, так как она часто используется и с другими типами рекуррентных слоев, например: LSTM и GRU о которых мы еще будем говорить. Для простоты архитектура нашей сети будет иметь два подряд идущих RNN слоя:
В пакете Keras на вход каждого рекуррентного слоя должен подаваться тензор, размерами: (batch_size, timesteps, units)
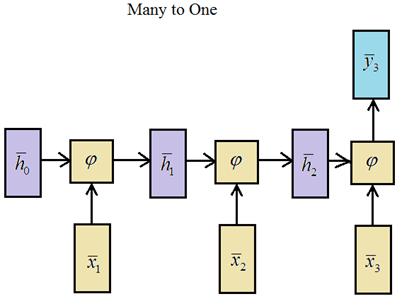
Возьмем программу из последнего занятия по прогнозированию слов и здесь на выходе Embedding слоя, как раз формировался такой тензор: model = Sequential() model.add(Embedding(maxWordsCount, 128, input_length = inp_words)) model.add(SimpleRNN(128)) model.add(Dense(maxWordsCount, activation='softmax')) model.summary() Но на выходе слоя SimpleRNN формируется тензор размерностью: (batch_size, units) так как мы здесь имеем дело со слоем типа:
А для построения стека слоев, нужен тип: Many to Many То есть нужно сохранять выходные значения на каждой итерации работы слоя. Для этого в Keras при определении слоя нужно указать именованный параметр: return_sequences=True который и преобразует слой в тип Many to Many. Итак, наша сеть, состоящая из стека двух рекуррентных слоев, будет выглядеть так: model = Sequential() model.add(Embedding(maxWordsCount, 128, input_length = inp_words)) model.add(SimpleRNN(128, return_sequences=True)) model.add(SimpleRNN(64)) model.add(Dense(maxWordsCount, activation='softmax')) model.summary() Все, теперь мы можем ее обучить и посмотреть на результат. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |