|
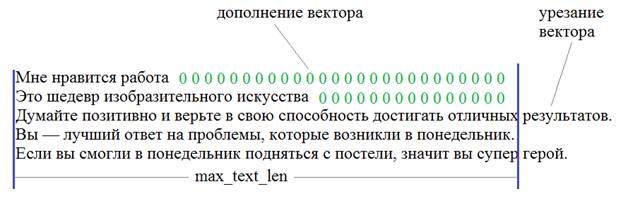
Как делать сентимент-анализ рекуррентной LSTM сетьюКурс по нейронным сетям: https://stepik.org/a/227582 На этом занятии продолжаем тему обработки текстовой информации и построим сеть для оценки эмоциональной окраски текста: положительный или отрицательный. Для начала нам нужно подготовить обучающую выборку. Что она из себя будет представлять? Смотрите, у нас есть два файла: с положительными и отрицательными короткими высказываниями. Длины фраз различны. Но на вход сети нужно подавать тензор со строго определенными размерами. Поэтому, короткие фразы дополняются нулями, а длинные – обрезаются:
Переменная max_text_len как раз и определяет размер каждой фразы (по числу слов). В итоге, у нас будет входной двумерный тензор, размерностью (batch_size, max_text_len) содержащий индексы слов фразы из сформированного словаря:
Давайте теперь посмотрим, как можно сформировать такой тензор. Вначале загрузим тексты с положительными и отрицательными высказываниями (они будут находиться в отдельных файлах: train_data_true и train_data_false): with open('train_data_true', 'r', encoding='utf-8') as f: texts_true = f.readlines() texts_true[0] = texts_true[0].replace('\ufeff', '') #убираем первый невидимый символ with open('train_data_false', 'r', encoding='utf-8') as f: texts_false = f.readlines() texts_false[0] = texts_false[0].replace('\ufeff', '') Далее, сразу объединим списки высказываний в единый список и вычислим длину каждого из них: texts = texts_true + texts_false count_true = len(texts_true) count_false = len(texts_false) print(count_true, count_false) Теперь нам нужно разбить эти высказывания на слова. Для этого воспользуемся уже знакомым инструментом Tokenizer и положим, что максимальное число слов будет равно 1000: maxWordsCount = 1000 tokenizer = Tokenizer(num_words=maxWordsCount, filters='!–"—#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n\r«»', lower=True, split=' ', char_level=False) tokenizer. fit_on_texts (texts) По идее, мы здесь могли бы и не задавать максимальное число слов, тогда эта величина была бы определена автоматически при парсинге текста. Но данный параметр имеет один существенный плюс: из всех найденных слов мы оставляем 999 наиболее часто встречаемых (maxWordsCount-1), то есть, отбрасываем редкие слова, которые особо не нужны при обучении НС. Конечно, в данном случае, останутся все найденные слова, т.к. их общее число меньше 1000. Вообще, этот параметр устанавливается с позиции «здравого смысла». Например, при большой обучающей выборке хорошим выбором будет значение в пределах: maxWordsCount = 20000 Итак, мы разбили текст на слова и для примера выведем их начальный список с частотами появления: dist = list(tokenizer.word_counts.items()) print(dist[:10]) print(texts[0][:100]) Далее, преобразуем текст в последовательность чисел в соответствии с полученным словарем. Для этого используется специальный метод класса Tokenizer: data = tokenizer.texts_to_sequences(texts) На выходе получим двумерный массив чисел объекта numpy:
Теперь, нам нужно выровнять все эти векторы до длины max_text_len. Для этого используется еще один встроенный метод pad_sequences, который обрезает массив data до длины max_text_len и добавляет нули для коротких векторов: max_text_len = 10 data_pad = pad_sequences(data, maxlen=max_text_len) print(data_pad) print(data_pad.shape) Все, получили двухмерный тензор обучающей выборки. Сформируем еще один тензор для требуемых выходных значений сети. Кодировать ответы будем по правилу:
Сформировать набор таких выходных данных можно следующим образом: X = data_pad Y = np.array([[1, 0]]*count_true + [[0, 1]]*count_false) print(X.shape, Y.shape) Все, у нас есть обучающая выборка и требуемые выходные значения. Для лучшего обучения перемешаем все эти высказывания, чтобы на вход подавались вперемешку и положительные и отрицательные. Так сеть будет лучше обучаться: indeces = np.random.choice(X.shape[0], size=X.shape[0], replace=False) X = X[indeces] Y = Y[indeces] Осталось создать модель рекуррентной сети. Мы воспользуемся рекуррентным слоем LSTM, о котором говорили на предыдущем занятии. Для его создания в Keras используется класс: keras.layers.LSTM(units, …) В качестве первого параметра (units) указывается число нейронов в каждом полносвязном слое внутри LSTM-ячейки:
Они же будут
формировать размерность выходного вектора Подробное описание параметров LSTM слоя в Keras смотрите на странице русскоязычной документации: https://ru-keras.com/recurrent-layers/ На выходе поставим полносвязный слой с двумя нейронами и функцией активации softmax. Определим оптимизацию по Adam с шагом сходимости 0,0001 (одна десятитысячная): model = Sequential() model.add(Embedding(maxWordsCount, 128, input_length = max_text_len)) model.add(LSTM(64, activation='tanh', return_sequences=True)) model.add(LSTM(32, activation='tanh')) model.add(Dense(2, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=Adam(0.0001)) Готово. Запускаем процесс обучения: history = model.fit(X, Y, batch_size=32, epochs=50) И давайте теперь посмотрим, что у нас получилось. Сформируем какой-нибудь текст и преобразуем его во входной формат нашей сети: t = "я люблю позитивное настроение".lower() data = tokenizer.texts_to_sequences([t]) data_pad = pad_sequences(data, maxlen=max_text_len) Посмотрим, что осталось из этого предложения (здесь могут использоваться слова, которых нет в нашем словаре – словарь формируется при парсинге текстов): print( sequence_to_text(data[0]) ) А функция sequence_to_text будет следующая: reverse_word_map = dict(map(reversed, tokenizer.word_index.items())) def sequence_to_text(list_of_indices): words = [reverse_word_map.get(letter) for letter in list_of_indices] Мы здесь сначала сформировали словарь, в котором сначала идут индексы, а затем, слова. С его помощью функция sequence_to_text преобразует последовательность индексов в слова. Ну и, наконец, пропускаем входной вектор через сеть и на выходе получаем результат: res = model.predict(inp) print(res, np.argmax(res), sep='\n') Конечно, сейчас будут получаться не очень хорошие результаты классификации текстов на положительные и отрицательные. Это связано, прежде всего, с малым объемом выборки. Я не нашел в интернете открытую базу русских текстов с их классификацией, поэтому пришлось создавать самому. Терпения у меня хватило только на 80 высказываний одного и другого типа. Это очень мало. Нужно несколько десятков тысяч. Но для этого мне потребовались бы месяцы упорной работы. Поэтому то, что здесь есть – это лишь демонстрация, пример решения задачи сентимент анализа текстов, показан общий подход начальной обработки текста и формирования обучающего множества. Курс по нейронным сетям: https://stepik.org/a/227582 Видео по теме |