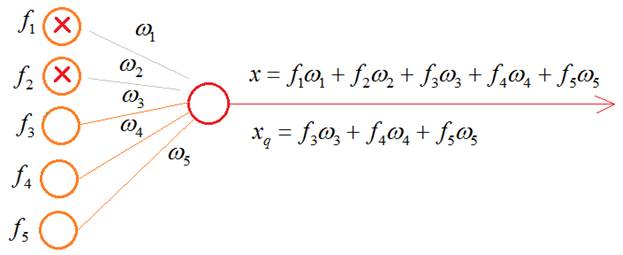|
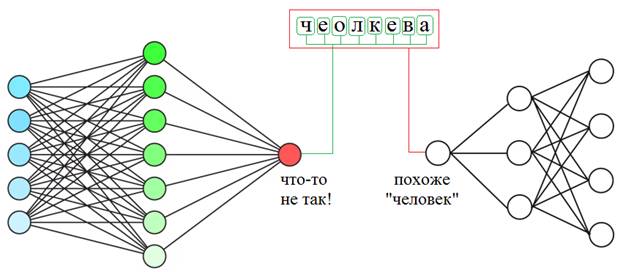
Dropout - метод борьбы с переобучением нейронной сетиКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Мы подошли к моменту, когда нужно поподробнее познакомиться со способами борьбы с переобучением НС. Это довольно частый эффект, который возникает из-за слишком точной подгонки разделительной гиперплоскости под обучающие данные. Ранее я уже приводил иллюстрацию такой подстройки, когда вместо прямой разделяющей линии формируется кривая. И это приводит к дополнительным ошибкам на тестовых обучающих множествах, т.е. на примерах, которые не участвовали при обучении. Упрощенно, эффект переобучения можно представить следующим образом. Предположим, что мы читаем текст. Мозг среднестатистического человека устроен так, что мы хорошо воспринимаем слова, даже если буквы в них написаны не по порядку (кроме первой и последней):
Так вот, если НС из-за большого числа нейронов подстроится под каждую букву слова, то этот текст для нее будет совершенно нечитаемым. Но сеть с небольшим числом нейронов, которая воспринимает слово в целом, сохранит способность к обобщению и правильному распознаванию.
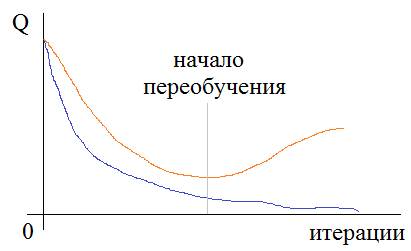
Но как в процессе обучения мы можем понять: происходит переобучение или нет? Мы об этом уже говорили на одном из предыдущих занятий и отмечали, что один из критериев – это увеличение расхождения в точности выходных значений между данными обучающей выборки и проверочной:
Отсюда получаем первую рекомендацию по борьбе с переобучением: Рекомендация №1: если наблюдается расхождение в точности выходных значений между обучающей и проверочной выборками, то процесс обучения следует остановить и уменьшить число нейронов. Но это не всегда дает желаемые результаты. Не редко с уменьшением числа нейронов уменьшается и точность выходных значений, то есть, показатель качества работы нейросети ухудшается. Очевидно, в таких случаях с переобучением нужно бороться с сохранением числа нейронов. Но как это сделать? Здесь нам на помощь приходит алгоритм под названием Dropout На русский язык его переводят как «метод прореживания» или «метод исключения» или же просто, говорят «дропаут». Цель этого метода – снизить специализацию каждого отдельного нейрона и сделать из них «специалистов более широкого профиля». Именно в этом корень проблемы переобучения. Но как уменьшить специализацию, сохраняя прежнее число нейронов? Очень просто. Давайте снова представим, что в некоторой школе работают учителя по различным предметам: химия, биология, история, математика, физика, география и информатика. Это их специализация. Затем, в какой-то момент времени директор школы озаботился их приверженностью только одной дисциплине и решил расширить горизонты их деятельности. Что он сделал? Он заставил учителя по химии время от времени вести занятия по физике, учителя по физике – химию, математика менялась с информатикой, а биология, история и география – между собой. В итоге, учителям волей-неволей пришлось изучить смежные дисциплины и расширить свою специализацию. Теперь, директор школы был доволен и знал, если какой-то отдельный учитель заболеет или уволится, у него будет кем его заменить.
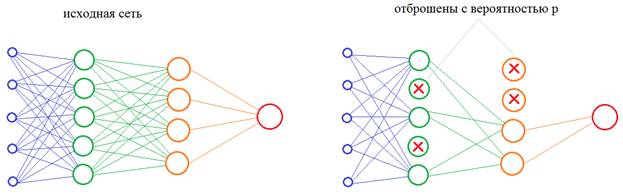
Теперь, осталось понять, как проделать тот же фокус с нейронами нейронной сети? Как в процессе обучения им «сказать», чтобы они брали на себя функции других нейронов? Решение просто до гениальности: на каждой итерации изменения весовых коэффициентов часть нейронов нужно исключать с заданной вероятностью p:
Это эквивалентно ситуации, когда часть учителей заболела и остальные вынуждены их заменять. Причем, в следующий момент, уже другие учителя уходят на больничный, а оставшиеся их заменяют. В результате, расширяется специализация всех учителей школы. Именно это происходит с нейронами в алгоритме dropout, которые то выключаются, то включаются. В какой же момент происходит их переключение? Как я выше отмечал – на каждой итерации изменения весов. Например, если веса меняются после каждого mini-batch, значит, переключение происходит после него. Если же веса меняются при каждом новом наблюдении, значит и переключение происходит с той же частотой. И так далее, то есть, мы переключаемся после каждой корректировки весовых коэффициентов. После того, как сеть обучена, включаются все нейроны и эффект переобучения (излишней специализации) должен заметно снизиться. Некоторые из вас здесь могут заметить одно важное несоответствие. Когда в процессе обучения с частью выключенных нейронов, мы пропускаем входной сигнал, то число входных связей на каждом нейроне уменьшается пропорционально вероятности p:
В режиме эксплуатации значение на входе нейрона будет x, а в момент обучения значение:
Как вы понимаете, это приводит к искаженным входным значениям, а значит, и к неверным результатам на выходе всей НС. Как поправить ситуацию, чтобы, в среднем, эти суммы были равными? Для этого нужно вычислить среднее число выключенных нейронов в текущем слое. Пусть их будет n штук. А понятие среднего в теории вероятностей – это математическое ожидание, которое в дискретном случае определяется выражением:
У нас роль СВ X играет число
исключенных нейронов в текущем слое;
А среднее число оставшихся нейронов, будет равно:
где q – вероятность того, что нейрон останется (не будет исключен). Отсюда получаем, что средний суммарный сигнал на входах нейронов следующего слоя, в среднем, будет меньше на величину:
И из этого выражения хорошо видно, что для сохранения масштаба суммы, ее нужно разделить на величину q:
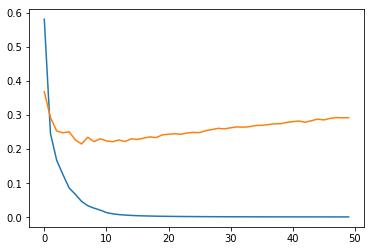
Во многих фреймворках алгоритм Dropout реализован именно так: суммарный сигнал на входах нейронов масштабируется, эмулируя поведение полной сети со всеми нейронами. Благодаря этому, в среднем, выходной сигнал сети соответствует истинным значениям и при ее эксплуатации (со всеми включенными нейронами) не будет возникать «сюрпризов». Итак, мы приходим ко второй рекомендации в борьбе с переобучением: Рекомендация №2: если наблюдается переобучение и сокращение числа нейронов недопустимо (по тем или иным причинам), то следует попробовать метод Dropout. Здесь остается один открытый вопрос: как выбирать значение вероятности p? Авторы этого подхода рекомендуют для нейронов скрытого слоя начинать со значения p=0,5. От себя добавлю, что, затем, при необходимости можно пробовать значения 0,4 и 0,3. Также следует иметь в виду, что это не абсолютное средство: оно может как помочь, так и не помочь. Если эффекта нет, то от него лучше отказаться и искать другие пути выхода из сложившейся ситуации. И добавлять его в НС только в случае возникновения проблем с переобучением. Моя рекомендация: просто так сразу, изначально его применять не нужно, только при описанных проблемах. Реализация Dropout в KerasИспользуемый нами пакет Keras, для построения и обучения НС позволяет применять алгоритм Dropout к любому отдельному слою. Для демонстрации его работы я смоделировал искусственный пример переобучения распознавания цифр. Взял маленькую обучающую выборку в 5000 изображений. Столько же отвел для проверочной. Число нейронов скрытого слоя установил в 300 – это явно много для таких выборок и такой задачи. Неизбежно должны возникнуть проблемы при обучении. Так и происходит. После 50 эпох мы видим расходящиеся графики:
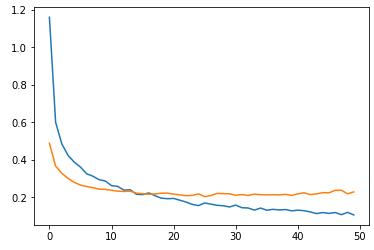
Теперь, применим к скрытому слою из 300 нейронов алгоритм Dropout с параметром p=0,8 (я специально взял его таким большим, чтобы был виден эффект): model = keras.Sequential([ Flatten(input_shape=(28, 28, 1)), Dense(300, activation='relu'), Dropout(0.8), Dense(10, activation='softmax') ]) То есть, мы записываем Dropout после слоя, к которому он применяется. Теперь после обучения у нас возникает следующая картина:
Смотрите, здесь качество обучения на проверочной выборке уже не ухудшается и составляет величину, примерно, 0,22. Тогда как в предыдущем случае она почти достигала значения 0,3. Dropout здесь явно сыграл свою положительную роль. Конечно, это довольно искусственный, гипертрофированный пример, но он наглядно демонстрирует эффект уменьшения степени специализации отдельных нейронов и повышения качества обучения при сохранении общего числа нейронов сети. Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |