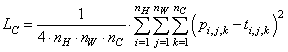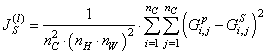|
Делаем перенос стилей изображений с помощью Keras и TensorflowКурс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Пришло время реализовать алгоритм стилизации изображений, который мы рассмотрели на прошлом занятии, с использованием пакетов Keras и Tensorflow Сразу скажу, что за основу я взял программу, представленную в этом документе: Сделал некоторые упрощения этой программы и запустил ее под Tensorflow 2.x. Давайте подробно разберем, как здесь все работает. Вначале импортируем необходимые модули: import numpy as np import matplotlib.pyplot as plt from google.colab import files from io import BytesIO from PIL import Image import tensorflow as tf from tensorflow import keras И, далее, нам нужно загрузить два изображения: контентное и стилевое. Я их подготовил заранее, каждое размером 224х224 пикселей в формате RGB:
Первое хранится в файле img.jpg, а второй – в файле img_style.jpg. Мы воспользуемся этими именами для их различения в процессе загрузки: upl = files.upload() img = Image.open(BytesIO(upl['img.jpg'])) img_style = Image.open(BytesIO(upl['img_style.jpg'])) В результате переменная img будет ссылаться на контентное изображение, а img_style – на стилизованное. Отобразим их, чтобы убедиться, что все было загружено верно: plt.subplot(1, 2, 1) plt.imshow( img ) plt.subplot(1, 2, 2) plt.imshow( img_style ) plt.show() Отлично, это мы сделали. Далее, планируется использовать сеть VGG19, поэтому наши изображения нужно преобразовать во входной формат этой сети. Мы это уже делали, когда рассматривали архитектуру VGG и, в частности, использовали вот такую операцию пакета Keras: x_img = keras.applications.vgg19.preprocess_input( np.expand_dims(img, axis=0) ) x_style = keras.applications.vgg19.preprocess_input(np.expand_dims(img_style, axis=0)) Здесь метод preprocess_input преобразовывает изображение из формата RGB в формат BGR и, кроме того, уменьшает средние значения каждого цветового канала на величины: (B) 103.939, (G) 116.779 и (R) 123.68 Поэтому, чтобы вернуть изображение в исходный формат RGB, сразу определим такую функцию: def deprocess_img(processed_img): x = processed_img.copy() if len(x.shape) == 4: x = np.squeeze(x, 0) assert len(x.shape) == 3, ("Input to deprocess image must be an image of" "dimension [1, height, width, channel] or [height, width, channel]") if len(x.shape) != 3: raise ValueError("Invalid input to deprocessing image") # perform the inverse of the preprocessing step x[:, :, 0] += 103.939 x[:, :, 1] += 116.779 x[:, :, 2] += 123.68 x = x[:, :, ::-1] x = np.clip(x, 0, 255).astype('uint8') return x Далее, мы загрузим обученную сеть VGG19, но без полносвязной НС на ее конце (она нам не нужна): vgg = keras.applications.vgg19.VGG19(include_top=False, weights='imagenet') vgg.trainable = False Здесь параметр include_top=False как раз отбрасывает полносвязную сеть, а параметр weights='imagenet' указывает загрузить веса, обученные на базе 10 миллиона изображений базы ImageNet. Следующая строчка запрещает изменять веса, то есть, проводить обучение этой сети. В дальнейшем нам нужно будет работать с этой сетью, подавать на ее вход изображения и брать на выходах определенных слоев вычисленные карты признаков:
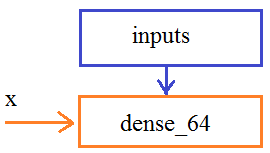
Как это лучше сделать? Для этого мы создадим новую сеть на базе VGG19, используя класс: keras.models.Model(inputs = None, outputs = None, name) Этот класс позволяет относительно легко строить произвольные архитектуры сетей. Как он это делает? Я здесь сделаю небольшое отступление, чтобы пояснить этот важный момент. Сморите, в Tensorflow слои можно создавать связанные друг с другом. Например, мы сначала создаем первый входной слой: inputs = keras.Input(shape=(784,), name='img') и хотим его связать со следующим полносвязным слоем. Для этого мы его создаем: dense_64 = layers.Dense(64, activation='relu') а, затем, связываем с входным: x = dense_64(inputs) Вот такая запись, фактически, определяет направленный граф от вершин inputs к полносвязному слою dense из 64 нейронов и на последний ссылается переменная x:
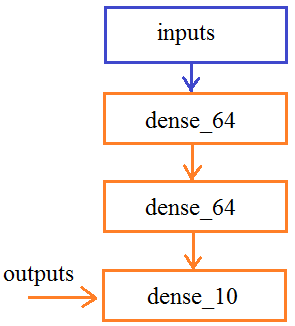
Все это можно записать и короче: x = layers.Dense(64, activation='relu')(inputs) По аналогии, добавим еще два слоя: x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x) В результате, у нас получится вот такой граф слоев:
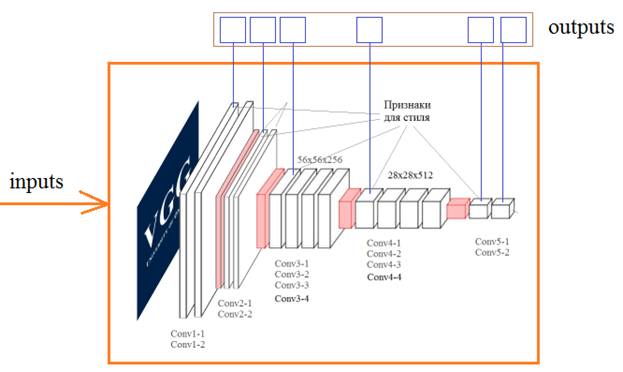
Теперь, смотрите, имея ссылку outputs на последний слой и ссылку inputs на первый входной слой, можно построить модель этой сети с помощью класса Model: model = keras.models.Model(inputs, outputs) Вот именно так мы и создадим копию сети VGG19. Сначала выделим из нее выходы слоев с именами: # Content layer where will pull our feature maps content_layers = ['block5_conv2'] # Style layer we are interested in style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1' ] Почему именно такие имена? Их можно узнать, выполнив команду: print(vgg.summary()) # вывод структуры НС в консоль Затем, сразу вычислим их количество: num_content_layers = len(content_layers) num_style_layers = len(style_layers) А само выделение выглядит так: style_outputs = [vgg.get_layer(name).output for name in style_layers] content_outputs = [vgg.get_layer(name).output for name in content_layers] Мы здесь обращаемся к слоям по именам и помещаем в список объект выхода каждого из них. Далее, сформируем общий список выходных слоев и отобразим их в консоли: model_outputs = style_outputs + content_outputs print(vgg.input) for m in model_outputs: print(m) Теперь, можно сформировать копию сети VGG19 с требуемыми выходами: model = keras.models.Model(vgg.input, model_outputs) for layer in model.layers: layer.trainable = False print(model.summary()) # вывод структуры НС в консоль Кроме того, мы здесь указываем, что весовые коэффициенты изменять нельзя, т.к. сеть уже обучена и менять ее не нужно. Особенность этой модели еще и в том, что пропуская через нее какое-либо изображение, будем получать тензор выходных значений в соответствии со списком model_outputs. Например: outs = model(x_img) даст значения выходных карт признаков со всех шести слоев: block1_conv1, block2_conv1, block3_conv1, block4_conv1, block5_conv1, block5_conv2 Это, как раз то, что нам нужно. Причем, сеть будет состоять из обученных весов, так как они тоже копируются при ее создании. Поэтому, мы можем теперь относительно просто реализовать функцию для выделения необходимых признаков для контентного и стилевого изображений: def get_feature_representations(model): # batch compute content and style features style_outputs = model(x_style) content_outputs = model(x_img) # Get the style and content feature representations from our model style_features = [style_layer[0] for style_layer in style_outputs[:num_style_layers]] content_features = [content_layer[0] for content_layer in content_outputs[num_style_layers:]] return style_features, content_features Вначале пропускаем через модель оба изображения и на выходе получаем их признаки на соответствующих слоях. Затем, формируем список из карт стилевого изображения (это первые пять слоев) (здесь style_layer[0] записан, чтобы взять только трехмерный тензор самих карт и отбросить ненужную первую размерность). Аналогично для карт контента (это последний 6-й выходной слой). Все, теперь мы можем получать начальные стили для наших исходных изображений. Пришло время определить функции для вычисления потерь формируемого изображения. Как мы говорили на предыдущем занятии, эта функция состоит из суммы двух критериев: рассогласование по контенту и стилю. Начнем с первого. Средний квадрат разницы по контенту можно вычислить с использованием встроенных методов пакета Tensorflow: def get_content_loss(base_content, target): return tf.reduce_mean(tf.square(base_content - target)) Здесь первый метод square() возвращает тензор квадратов разностей между признаками контентного изображения и формируемого (target). А второй метод reduce_mean() вычисляет среднее арифметическое от полученного тензора квадратов. В результате, имеем вычисления по формуле:
Для вычисления потерь по стилю, вначале определим функцию вычисления матрицы Грама для переданного ей тензора: def gram_matrix(input_tensor): # We make the image channels first channels = int(input_tensor.shape[-1]) a = tf.reshape(input_tensor, [-1, channels]) n = tf.shape(a)[0] gram = tf.matmul(a, a, transpose_a=True) return gram / tf.cast(n, tf.float32) Тензор представлен в формате:
Поэтому, первая строка возвращает число каналов слоя. Затем, мы вытягиваем этот тензор в матрицу:
Запоминаем размерность
И делаем матричное вычисление с последующим делением на n (усредняем величины):
Теперь, мы можем реализовать функцию, которая будет вычислять сумму квадратов рассогласований между картами стилей формируемого изображения и стилевого: def get_style_loss(base_style, gram_target): gram_style = gram_matrix(base_style) return tf.reduce_mean(tf.square(gram_style - gram_target)) Здесь base_style – карта стилей
формируемого изображения; gram_target – матрица Грама
соответствующего слоя l стилевого
изображения. Затем, вычисляется матрица Грама формируемого изображения и их
квадрат рассогласования (эту функцию мы будем вызывать для каждого слоя
Наконец, общая функция для вычисления всех потерь, будет выглядеть так: def compute_loss(model, loss_weights, init_image, gram_style_features, content_features): style_weight, content_weight = loss_weights model_outputs = model(init_image) style_output_features = model_outputs[:num_style_layers] content_output_features = model_outputs[num_style_layers:] style_score = 0 content_score = 0 weight_per_style_layer = 1.0 / float(num_style_layers) for target_style, comb_style in zip(gram_style_features, style_output_features): style_score += weight_per_style_layer * get_style_loss(comb_style[0], target_style) weight_per_content_layer = 1.0 / float(num_content_layers) for target_content, comb_content in zip(content_features, content_output_features): content_score += weight_per_content_layer* get_content_loss(comb_content[0], target_content) style_score *= style_weight content_score *= content_weight # Get total loss loss = style_score + content_score return loss, style_score, content_score Здесь content_weight и style_weight – это параметры
Далее, мы пропускаем через модель формируемое изображение и на выходе получаем тензоры карт признаков на каждом заданном выходном слое. Разделяем эти карты на карты стилей и контента. И определяем вспомогательные переменные, где будем хранить величины потерь для стиля и контента. Затем, определяем веса weight_per_style_layer для суммирования потерь стилей каждого слоя. И делаем цикл, перебирая ранее вычисленные матрицы Грама стилевого изображения и карты признаков для каждого выхода сети формируемого изображения. В цикле суммируем квадраты рассогласований для каждого слоя, получаем вычисления по формуле:
И то же самое выполняем для контентного слоя. Только он один, поэтому цикл сработает только один раз и, фактически, мы здесь просто вычисляем средний квадрат рассогласования по картам признаков последнего выходного слоя. После вычисления
показателей качества, мы их умножаем на величины Далее, мы
определяем число итераций работы алгоритма и параметры num_iterations=100 content_weight=1e3 style_weight=1e-2 Затем, вычисляем карты стилей и контента для начальных изображений: style_features, content_features = get_feature_representations(model) gram_style_features = [gram_matrix(style_feature) for style_feature in style_features] И, кроме того, сразу определяем матрицы Грама для начального стилевого изображения. После этого формируем начальное изображение, как копию контентного: init_image = np.copy(x_img) init_image = tf.Variable(init_image, dtype=tf.float32) Указываем оптимизатор Adam для алгоритма градиентного спуска, номер текущей итерации, переменные для хранения минимальных потерь и лучшего стилизованного изображения и кортеж параметров альфа и бета: opt = tf.compat.v1.train.AdamOptimizer(learning_rate=2, beta1=0.99, epsilon=1e-1) iter_count = 1 best_loss, best_img = float('inf'), None loss_weights = (style_weight, content_weight) Сформируем словарь конфигурации: cfg = { 'model': model, 'loss_weights': loss_weights, 'init_image': init_image, 'gram_style_features': gram_style_features, 'content_features': content_features } Вспомогательные переменные для преобразования формируемых изображений в формат RGB, а также коллекцию для хранения изображений на каждой итерации: norm_means = np.array([103.939, 116.779, 123.68]) min_vals = -norm_means max_vals = 255 - norm_means imgs = [] Наконец, идет запуск самого алгоритма градиентного спуска, то есть, формирования стилизованного изображения: for i in range(num_iterations): with tf.GradientTape() as tape: all_loss = compute_loss(**cfg) loss, style_score, content_score = all_loss grads = tape.gradient(loss, init_image) opt.apply_gradients([(grads, init_image)]) clipped = tf.clip_by_value(init_image, min_vals, max_vals) init_image.assign(clipped) if loss < best_loss: best_loss = loss best_img = deprocess_img(init_image.numpy()) plot_img = deprocess_img(init_image.numpy()) imgs.append(plot_img) print('Iteration: {}'.format(i)) Смотрите, как здесь все работает. Функция compute_loss пропускает формируемое изображение через НС и возвращает значения потерь. Но мы вызываем модель в области видимости объекта GradientTape, который записывает все величины на каждом нейроне сети в момент прогонки изображения. Затем, мы используем записанные значения, чтобы вычислить градиент для изменяемых параметров, минимизируя общие потери. Так как изменяемые параметры – это пиксели изображения, то именно их мы и указываем в методе gradient. Затем, применяем вычисленный градиент для изменения пикселей. Так с помощью Tensorflow можно делать градиентный спуск для выбранных изменяемых параметров, минимизируя отклик сети в соответствии с заданным критерием качества. Более подробно о GradientTape можно почитать на странице официальной документации: https://www.tensorflow.org/api_docs/python/tf/GradientTape Далее, мы ограничиваем значения пикселей изображения минимальными и максимальными границами и запоминаем лучшее. В конце выводим то, что получилось в лучшем варианте. Давайте запустим этот алгоритм и посмотрим что получится. Это самое краткое изложение техники стилизации, которое у меня получилось сделать. Если вам показалось, что это несколько затянуто и нудно, сорри, по другому никак. На этом я завершу занятие, а дома попробуйте повторить программу стилизации для своих выбранных изображений (и не забывайте, что они должны иметь одинаковые размеры и быть в формате RGB). Курс по нейронным сетям: https://stepik.org/a/227582?utm_source=proproprogs Видео по теме |