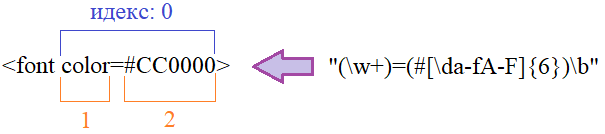|
Объект re.Match, методы re.search, re.finditer, re.findallНа предыдущих занятиях мы с вами рассмотрели основы построения регулярных выражений. Теперь пришло время научиться применять их, используя различные методы модуля re. Существует два различных подхода применения регулярных выражений:
Ранее, во всех наших примерах мы использовали режим «здесь и сейчас». Например, для выделения из строки шаблона цвета в формате: #xxxxxx где x – шестнадцатиричное число, можно записать такую программу: import re text = "<font color=#CC0000>" match = re.search(r"#[\da-fA-F]{6}\b", text) print(match) Мы здесь определяем шаблон в виде: "#[\da-fA-F]{6}\b" который передаем в виде строки первым параметром метода search, и на выходе получаем объект re.Match со следующими свойствами: <re.Match object; span=(12, 19), match='#CC0000'> Если же вхождение не будет найдено, то метод search возвращает значение None: match = re.search(r"#[\da-fA-F]{7}\b", text) получаем None. Более детально это работает так. Метод search сначала компилирует регулярное выражение в свой внутренний формат, а затем, запускается программный модуль (написанный на языке Си), который ищет первый подходящий фрагмент в тексте под этот шаблон. Благодаря тому, что реализации методов модуля re написаны на языке Си, они довольно быстро выполняют обработку строк. Свойства и методы объекта re.MatchДавайте теперь посмотрим на методы объекта re.Match. И, для его исследования возьмем вот такое регулярное выражение: match = re.search(r"(\w+)=(#[\da-fA-F]{6})\b", text) Перейдем в консольный режим для удобства работы. Смотрите, у нас здесь две сохраняющие скобки: для атрибута и для значения. В действительности, метод search и другие ему подобные создают следующую иерархию вхождений:
И мы в этом можем легко убедиться, вызвав метод group объекта re.Match: match.group(0) match.group(1) match.group(2) Или же, указать все эти индексы через запятую: match.group(0,1,2) На выходе получим кортеж из соответствующих вхождений: ('color=#CC0000', 'color', '#CC0000') Также можно вызвать метод match.groups() который возвращает кортеж из всех групп, начиная с индекса 1. У этого метода есть необязательный параметр default, который определяет возвращаемое значение для групп, не участвующих в совпадении. Свойство lastindex содержит индекс последней группы: match.lastindexЕсли нам нужно узнать позиции в тексте начала и конца группы, то для этого служат методы start и end: match.start(1) match.end(1) Если по каким-то причинам группа не участвовала в совпадении (например, ее вхождение было от 0), то данные методы возвращают -1. Также мы можем получить сразу кортеж с начальной и конечной позициями для каждой группы: match.span(0) match.span(1) Для определения первого и последнего индексов, в пределах которых осуществлялась проверка в тексте, служат свойства: match.endpos match.pos Следующее свойство re: pattern = match.re возвращает скомпилированное регулярное выражение. А свойство string: match.stringсодержит анализируемую строку. Давайте теперь реализуем такой шаблон: match = re.search(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text) мы здесь определили две именованных группы: key и value. В результате, с помощью метода: match.groupdict() можно получить словарь: {'key': 'color', 'value': '#CC0000'} Свойство match.lastgroupвозвращает имя последней группы (или значение None, если именованных групп нет). Наконец, с помощью метода match.expand(r"\g<key>:\g<value>") можно формировать строку с использованием сохраненных групп: 'color:#CC0000' Здесь синтаксис:
Вот такие возможности извлечения результатов обработки строк дает объект re.Match. Методы re.search, re.finditer и re.findallВ заключение этого занятия снова обратимся к методу re.search для поиска первого вхождения в тексте, удовлетворяющего регулярному выражению. Полный синтаксис этого метода следующий: re.search(pattern, string, flags)
Ключевой особенностью метода является поиск именно первого вхождения. Например, если взять вот такой текст: text = "<font color=#CC0000 bg=#ffffff>" и выполнить его анализ: match = re.search(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text) то второй атрибут никак не будет фигурировать в результатах объекта match: match.groups() выведет всего две группы для первого атрибута: ('color', '#CC0000') Если нужно найти все совпадения, то можно воспользоваться методом re.finditer(pattern, string, flags) который возвращает итерируемый объект для перебора всех вхождений: for m in re.finditer(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text): print(m.groups()) На выходе получим две коллекции для первого и второго атрибутов: ('color',
'#CC0000')
Однако, часто на практике нам нужно получить лишь список найденных вхождений, групп и это проще реализовать с помощью метода re.findall(pattern, string, flags) следующим образом: match = re.findall(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text) print(match) На выходе будет список кортежей: [('color', '#CC0000'), ('bg', '#ffffff')] Недостатком последнего метода является ограниченность полученных данных: здесь лишь список, тогда как два предыдущих метода возвращали объект re.Match, обладающий, как мы только что видели, богатым функционалом. Но, если списка достаточно, то метод findall может быть вполне удобным и подходящим. На следующем занятии мы продолжим рассматривать методы модуля re для обработки строк посредством регулярных выражений. Видео по теме |