|
Свойства и представления массивов, создание их копийЭто занятие начнем с изучения основных свойств массивов NumPy. С некоторыми из них мы уже знакомы. Например, если создать вот такой одномерный массив: a = np.array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) то через точку нам будут доступны методы и свойства класса array. В частности, следующая строчка: a.dtypeвозвратит текущий тип данных элементов массива: dtype('float64') Но через него мы также можем поменять тип данных, если присвоить ему другое определение: a.dtype = np.int8() Мы здесь используем класс int8 для описания целочисленного типа в 8 бит (1 байт). Все данные будут преобразованы и при выводе массива увидим значения: array([-102,
-103, -103, -103, -103, -103, -71, 63, -102, -103, -103,
Их стало больше. Изначально имели длину массива в 9 элементов, теперь стало: a.size # 72 элемента Свойство size возвращает число элементов массива вне зависимости от его размерности. Почему массив стал иметь 72 элемента вместо 9? Ну, во-первых, можно заметить, что на каждый исходный элемента приходится 72:9 = 8 чисел типа int8 (1 байт). То есть, изначальный тип float64 был разложен на 8 байт. Что вполне логично, так как 64 бит = 8 байт. И, фактически, все исходные вещественные данные были просто представлены набором байт. Отсюда такое превращение одного массива в другой. При этом потерь данных не произошло и, если мы снова вернем тип float64: a.dtype = np.float64() то увидим исходный массив: array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) По этой же причине, если менять тип в уже существующем массиве, скажем, на float32: a.dtype = 'float32' то число его элементов увеличится вдвое: a.size # 18 элементов а содержимое станет следующим: array([-1.58818684e-23, 1.44999993e+00,
-1.58818684e-23, 1.57499993e+00,
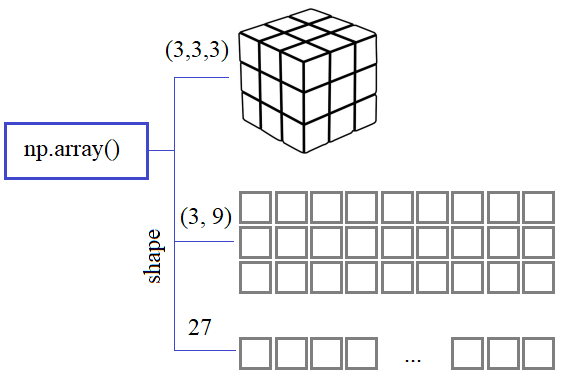
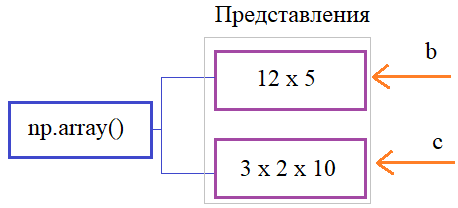
Вот так ведут себя массивы NumPy при изменении их типов данных. Далее, если требуется узнать сколько байт занимает один элемент, то можно воспользоваться свойством: a.itemsize # вернет 4 (байта) Соответственно, размер памяти для всего массива можно вычислить так: a.size*a.itemsize # вернет 72 (байта) Представления массивовДавайте теперь создадим массив размерностью 3x4x5: b = np.ones( (3, 4, 5) ) Узнать количество его осей, можно через свойство ndim (доступно только для чтения): b.ndim # вернет значение 3 Чтобы определить размеры каждой из осей, используется свойство shape: b.shape # вернет кортеж (3, 4, 5) С его помощью мы можем менять размерность массива, главное, чтобы общее число элементов оставалось прежним. Например, сделать так: b.shape = 60 # все 60 элементов вытянутся в строку b.shape = (12, 5) # массив размерностью 12x5 И так далее. Используя свойство shape мы можем менять представление одних и тех же данных текущего массива. Обратите внимание, здесь не создаются новые массивы, а лишь меняется представление текущего. Это очень важный момент при работе с NumPy: Один и тот же массив в NumPy может иметь разное представление и математически и программно обрабатываться по разному.
Такое весьма полезное и гибкое поведение влечет некоторые следствия. Например, мы хотим сформировать новый массив на основе массива b, просто изменив его форму (представление): c = b.reshape(3, 2, 10) Мы здесь воспользовались методом reshape, который возвращает массив с новой указанной размерностью (прежний массив остается без изменений). В результате, переменная c будет ссылаться на массив размерами 3x2x10, а переменная b – на массив 12x5. Но данные при этом, будут использоваться одни и те же:
Мы легко можем в этом убедиться. Изменим элемент в массиве b: b[0, 0] = 10 и это скажется на первом значении массива c. Хотя id этих ссылок будут разными: print( id(b), id(c) ) # разные значения Это связано с тем, что они ссылаются на разные представления одного и того же массива, а не на его данные. То есть, пример функции reshape() показывает, что в пакете NumPy разделяются понятия данные и представление этих данных. В результате, одни и те же данные могут иметь множество разных представлений. Это очень удобно с точки зрения экономии памяти, когда один и тот же массив можно использовать и как одномерный вектор и как матрицу. Также при работе с NumPy следует помнить, что представления могут формироваться разными способами. Метод reshape() – это лишь один частный пример. Если выполнить транспонирование матрицы b и использовать для этого свойство T: d = b.T # T – транспонирование матрицы (12, 5) то получим еще одно представление, на которое будет ссылаться переменная d, размерностью: d.shape # возвратит кортеж (5, 12) При этом, сама матрица b останется неизменной. Как же узнать, когда создается новый, независимый массив, а когда его представление? В идеале, нужно просто знать, какие функции, методы и свойства возвращают новое представление, а какие создают новый массив. Но на начальном этапе об этом легко догадаться из логики работы самой программы: любое изменение формы, как правило, связано с созданием нового представления или изменением текущего. Поэтому, здесь больших проблем, обычно, не возникает. Главное понимать, что в NumPy массивы и их представления – это разные понятия. Метод view() для создания представленияУ каждого массива array существует метод view(), который возвращает копию его представления. О чем здесь речь? Смотрите. Предположим, мы присваиваем один массив другому: a = np.array([1,2,3,4,5,6,7,8,9]) b = a Зная, что в языке Python переменные – это ссылки на объекты, то a и b будут просто ссылаться на один и тот же массив, копирования здесь никакого происходить не будет. Следовательно, если дальше по программе изменить форму массива через одну из этих ссылок, например, так: a.shape = 3,3 то вторая ссылка b также будет ссылаться на это измененное представление. В больших и сложных проектах такое поведение может приводить к неожиданным ошибкам, когда программист ожидает вектор, а получает матрицу. Чтобы разрешить эту проблему достаточно создать новое представление начального массива a с помощью метода view(): a = np.array([1,2,3,4,5,6,7,8,9]) b = a.view() # создание нового представления Тогда, меняя форму через ссылку a: a.shape = 3,3 это уже никак не скажется на форме того же самого массива, доступного через ссылку b: array([1, 2, 3, 4, 5, 6, 7, 8, 9]) Создание копий массивовИногда в программе все же нужно создавать копии массивов. Это можно сделать несколькими способами. В последних версиях NumPy функция array() возвращает копию переданного ей массива, например: a = np.array([1,2,3,4,5,6,7,8,9]) b = np.array( a ) # создается копия массива Или же, копию можно получить с помощью метода copy объекта array: c = a.copy() # создание копии массива При этом происходит копирование всех свойств объекта array. Последний вариант предпочтителен, когда нам нужно получить полную копию массива, а не просто новый объект array. Видео по теме |