|
Множества (unique) и операции над нимиНа этом занятии познакомимся с еще одним типом математических операций пакета NumPy – работы со множествами. И ответим на первый вопрос: что такое множество с позиции NumPy? Смотрите, предположим имеется одномерный массив: a = np.array([1, 2, 3, 4, 4, 3, 2, 1]) В нем есть неуникальные (повторяющиеся) значения. Так вот, в множествах все значения должны быть уникальными и представленными в единственном варианте. Чтобы преобразовать массив a в множество используется функция unique: setA = np.unique(a) # array([1, 2, 3, 4]) В действительности, это такой же массив, только с уникальными значениями. У функции unique есть несколько полезных параметров. Первый из них return_counts: np.unique(a, return_counts=True) # (array([1, 2, 3, 4]), array([2, 2, 2, 2])) который позволяет возвращать не только уникальные значения, но и число их вхождений в исходном массиве a. Следующий параметр return_index позволяет определять индексы первого вхождения уникальных элементов в исходном массиве: np.unique(a, return_index=True) # (array([1, 2, 3, 4]), array([0, 1, 2, 3])) Наконец, третий параметр return_inverse возвращает индексы, по которым можно точно восстановить исходный массив. Понять этот параметр проще всего на примере: np.unique(a, return_inverse=True) на выходе получим: (array([1, 2, 3, 4]), array([0, 1, 2, 3, 3, 2, 1, 0], dtype=int32)) Видите, здесь 1 у множества имеет индекс 0 и во втором массиве стоят нули там, где должна быть 1. И так для всех значений. Далее, по этой информации можно выполнить восстановление исходного массива a. Делается это так: setA, indx = np.unique(a, return_inverse=True) aa = setA[indx] # array([1, 2, 3, 4, 4, 3, 2, 1]) Подробнее о таком списочном индексировании мы поговорим на следующем занятии. Функция unique также может работать и с многомерными массивами. Например: x = np.array([[0, 1, 1, 2],[0, 1, 1, 2],[9, 1, 1, 2]]) np.unique(x) # array([0, 1, 2, 9]) То есть, она просматривает весь массив x и оставляет только уникальные значения. На выходе формируется обычный одномерный массив. Однако, здесь мы можем дополнительно указывать оси, по которым будет происходить отбор уникальных значений, например, так: np.unique(x, axis=0) получим результат: array([[0,
1, 1, 2],
Здесь использовалась первая ось, то есть, определялись уникальные строки. Если указать вторую ось: np.unique(x, axis=1) то получим уникальные столбцы: array([[0,
1, 2],
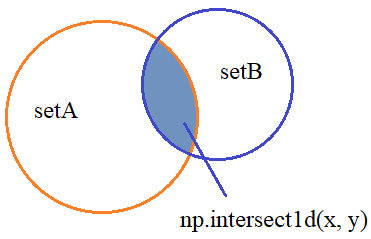
Операции над множествамиВ NumPy есть несколько функций для выполнения базовых операций с множествами. Первая – это проверка вхождений элементов одного множества в другое. Например, заданы два массива с уникальными значениями (множества): x = np.array([0, 1, 2, 3]) y = np.array([1, 2, 3, 4, 5, 6, 7, 8]) И выполним функцию in1d: np.in1d(x, y) # array([False, True, True, True]) На выходе получим массив булевых значений и там где стоит False означает отсутствие элемента, а там где стоит True – наличие совпадения. Причем, порядок следования элементов не имеет никакого значения. Если перемешать массив y: np.random.shuffle(y) # array([5, 8, 4, 6, 2, 7, 3, 1]) np.in1d(x, y) # array([False, True, True, True]) то видим тот же результат. Пересечение множествСледующая базовая операция – это пересечение двух множеств, то есть, определение значений, которые входят в оба множества одновременно. Она выполняется с помощью функции: np.intersect1d(x, y) # array([1, 2, 3])
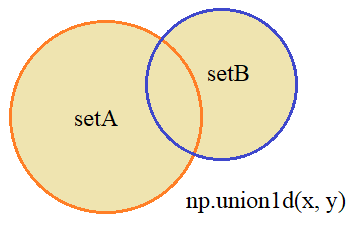
Объединение множествПротивоположная ей операция – объединение множеств, реализуется с помощью функции: np.union1d(x, y) # array([0, 1, 2, 3, 4, 5, 6, 7, 8]) Соответственно, получим уникальные числа, которые входят в оба множества:
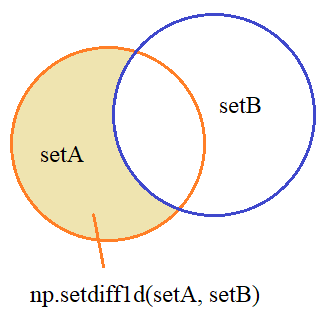
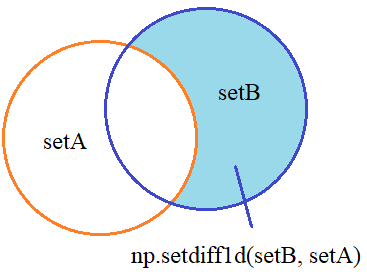
Вычитание множествДалее, множества можно вычитать друг из друга, причем результат будет зависеть от того, какое множество из какого вычитается:
Реализуются эти операции с помощью функции setdiff1d: np.setdiff1d(x, y) # array([0]) np.setdiff1d(y, x) # array([4, 5, 6, 7, 8]) Симметричная разность (XOR)Последняя базовая операция – это вычисление симметричной разности, то есть, остаются не совпадающие значения из двух множеств:
Реализуется это с помощью функции setxor1d: np.setxor1d(x, y) # array([0, 4, 5, 6, 7, 8]) Вот так, с помощью пакета NumPy, можно работать с одномерными массивами, состоящих из уникальных значений и выполнять над ними операции как с множествами. Видео по теме |