|
методы fetchall, fetchmany, fetchone, iterdumpПродолжим изучение API для работы с SQLite на языке Python и пару слов о способе извлечения данных из запросов. Об этом мы уже говорили на одном из предыдущих занятий, когда рассматривали методы:
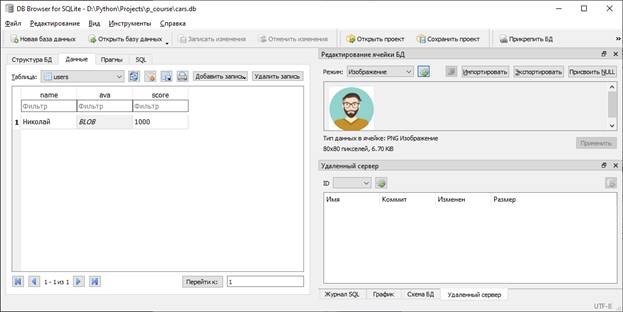
Ссылку на это занятие вы найдете в описании под этим видео (https://youtu.be/fYGfBpuFu0A). Я здесь лишь напомню порядок применения этим функций. Для начала наполним БД cars записями: import sqlite3 as sq cars = [ ('Audi', 52642), ('Mercedes', 57127), ('Skoda', 9000), ('Volvo', 29000), ('Bentley', 350000) ] with sq.connect("cars.db") as con: cur = con.cursor() cur.executescript("""CREATE TABLE IF NOT EXISTS cars ( car_id INTEGER PRIMARY KEY AUTOINCREMENT, model TEXT, price INTEGER) """) cur.executemany("INSERT INTO cars VALUES(NULL,?, ?)", cars) И, затем, выполним запрос на выборку записей: cur.execute("SELECT model, price FROM cars") Чтобы в программе на Python получить доступ к сформированной выборке, как раз и нужно воспользоваться функциями: fetchall, fetchmany или fetchone следующим образом: rows = cur.fetchall() print(rows) В консоли увидим список из кортежей с данными записей в соответствии с указанными полями model и price: [('Audi', 52642), ('Mercedes', 57127), ('Skoda', 9000), ('Volvo', 29000), ('Bentley', 350000)] По аналогии для fetchone: rows = cur.fetchone() будет взята только первая запись. И для fetchmany: rows = cur.fetchmany(4) берем не более четырех первых записей: [('Audi', 52642), ('Mercedes', 57127), ('Skoda', 9000), ('Volvo', 29000)] Наконец, мы говорили, что после формирования выборки сам экземпляр класса Cursor можно использовать как итерируемый объект и выбирать записи в цикле: for result in cur: print(result) Преимущество такого подхода в экономии памяти при большом числе записей в выборке. Здесь на каждой итерации цикла мы выбираем только одну следующую запись, а не храним их сразу целиком в памяти в виде списка. Это часто бывает эффективно и очень удобно. Далее, иногда более предпочтительным вариантом выходных данных является не кортеж с данными, а словарь, позволяющий обращаться к элементам по именам полей. Для этого после установления соединения с БД следует прописать вот такую строчку: con.row_factory = sq.Row Теперь, при выполнении программы увидим, что переменная result в цикле ссылается на объект Row, а не кортеж: <sqlite3.Row object at 0x00000185B226B8B0> И через этот объект доступ к данным осуществляется с помощью имен полей таблицы cars: print(result['model'], result['price']) Хранение изображений в БДЧасто в БД требуется хранить небольшие изображения, например, аватары пользователей. Для этого имеется специальный тип данных BLOB. Давайте создадим таблицу users с полем ava: cur.executescript("""CREATE TABLE IF NOT EXISTS users ( name TEXT, ava BLOB, score INTEGER) """) Далее напишем вспомогательную функцию считывания изображения из файла: def readAva(n): try: with open(f"avas/{n}.png", "rb") as f: return f.read() except IOError as e: print(e) return False Если изображение было успешно прочитано, то функция возвратит набор двоичных данных, иначе значение False. Затем, в менеджере контекста БД вызовем ее и при успешном чтении данных записываем в таблицу users: img = readAva(1) if img: binary = sq.Binary(img) cur.execute("INSERT INTO users VALUES ('Николай', ?, 1000)", (binary,)) Обратите внимание, прежде чем бинарные данные передавать в поле BLOB их нужно закодировать в бинарный объект модуля SQLite. Для этого и вызывается метод Binary, которому передается последовательность прочитанных байт изображения. Запустим программу и перейдем в приложение DB Browser. Откроем там таблицу users. И при выборе поля BLOB справа увидим изображение, которое там хранится:
Давайте теперь прочитаем изображение из этого поля. Выполним следующий запрос: cur.execute("SELECT ava FROM users LIMIT 1") и с помощью метода fetchone обратимся к первой (и единственной) записи и возьмем данные из поля ava: img = cur.fetchone()['ava'] Чтобы нам знать, что изображение было успешно прочитано, сохраним его в файл. Для этого запишем вот такую функцию: def writeAva(name, data): try: with open(name, "wb") as f: f.write(data) except IOError as e: print(e) return False return True И вызовем ее: writeAva("out.png", img) У нас в рабочем каталоге программы появился файл out.png и при его просмотре видим, что это то самое изображение. Вот так производится запись и чтение бинарных данных в SQLite. Создание бэкапа БДКласс Cursor содержит один весьма полезный метод iterdump() возвращающий итератор для SQL-запросов, на основе которых можно воссоздать текущую БД. Если просто вывести в консоль возвращаемых строк: with sq.connect("cars.db") as con: cur = con.cursor() for sql in con.iterdump(): print(sql) То получим список следующих SQL-команд: BEGIN TRANSACTION; CREATE TABLE cars ( car_id INTEGER PRIMARY KEY AUTOINCREMENT, model TEXT, price INTEGER); INSERT INTO "cars" VALUES(1,'Audi',0); INSERT INTO "cars" VALUES(2,'Mercedes',57127); INSERT INTO "cars" VALUES(3,'Skoda',9000); INSERT INTO "cars" VALUES(4,'Volvo',29000); INSERT INTO "cars" VALUES(5,'Bentley',350000); DELETE FROM "sqlite_sequence"; INSERT INTO "sqlite_sequence" VALUES('cars',5); CREATE TABLE users ( name TEXT, ava BLOB, score INTEGER); INSERT INTO "users" VALUES('Николай', …,1000); COMMIT; С помощью этих запросов можно точно воссоздать таблицы БД, то есть, их можно рассматривать как некий дамп БД. Чтобы наша программа выглядела более функциональной, сохраним все эти строчки в отдельном файле: with open("sql_damp.sql", "w") as f: for sql in con.iterdump(): f.write(sql) После запуска в рабочем каталоге программы появится файл sql_damp.sql с набором соответствующих команд. Теперь, чтобы восстановить БД с помощью этого файла можно воспользоваться методом executescript, о котором мы уже говорили: with open("sql_damp.sql", "r") as f: sql = f.read() cur.executescript(sql) Перед выполнением этой программы удалим файл cars.db и после запуска снова увидим этот файл с прежним содержимым. Создание БД в памятиИнтересной особенностью модуля SQLite является возможность создания БД непосредственно в памяти. Такая организация позволяет хранить временные данные программы в формате таблиц и работать с ними через SQL-запросы. В ряде случаев это бывает весьма удобно. Для создания БД в памяти устройства подключение записывается в виде: data = [("car", "машина"), ("house", "дом"), ("tree", "дерево"), ("color", "цвет")] con = sq.connect(':memory:') with con: cur = con.cursor() cur.execute("""CREATE TABLE IF NOT EXISTS dict( eng TEXT, rus TEXT )""") cur.executemany("INSERT INTO dict VALUES(?,?)", data) cur.execute("SELECT rus FROM dict WHERE eng LIKE 'c%'") print(cur.fetchall()) Мы здесь создали подключение, указав специальный параметр «:memory:», что означает «память» и, затем, в менеджере контекста создали таблицу dict с двумя полями, заполнили ее значениями и сделали выборку всех английских слов, начинающихся с первой буквы ‘c’. Этот пример показывает как можно использовать богатые возможности СУБД для хранения и выборки данных в процессе работы приложения, не создавая на диске БД. На этом мы завершим цикл занятий по SQLite. Данного материала вам вполне хватит для большинства приложений. Ну а по мере его использования неминуемо узнаете многие другие нюансы работы данного модуля. Видео по теме |