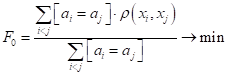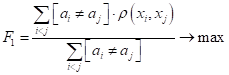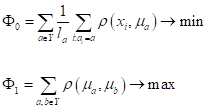|
Задачи кластеризации. Постановка задачиПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущих занятиях
мы познакомились с несколькими распространенными метрическими подходами к
задачам классификации и регрессии. В них нам была дана обучающая выборка
(размеченные данные), по которым строилась модель. Но на практике встречаются
задачи, когда исходный набор объектов
Это постановка задачи кластеризации. Здесь на выходе, в общем случае, нужно найти:
И, так как алгоритм должен сам разнести образы по классам, то задачу кластеризации относят к задачам обучения без учителя (unsupervised learning). То есть, это частная задача обучения без учителя. Помимо кластеризации существуют и совершенно другие методы, которые также относятся к обучению без учителя. Поэтому не нужно полагать, что кластеризация охватывает весь класс таких задач. Цели кластеризацииДля чего вообще может понадобиться делать кластеризацию данных? Здесь можно выделить несколько направлений:
Типы кластерных структурКакие на этом пути возникают проблемы? Первое. Часто задачи кластеризации не имеют четко выраженного единственного решения (даже с позиции человеческого восприятия). Следующий пример показывает, как по разному можно разделить множество точек по группам:
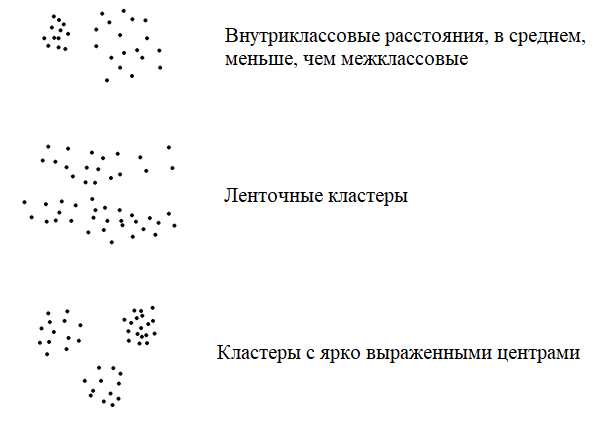
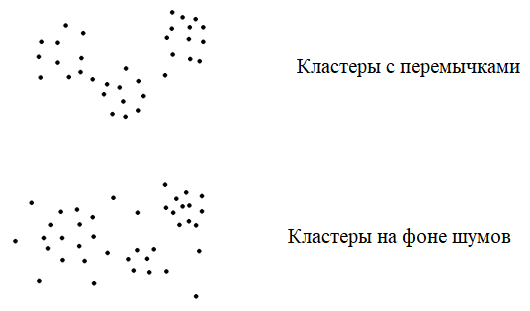
Здесь результат кластеризации может зависеть и от выбора метрики и от применяемого алгоритма и от начальных исходных данных, которые зачастую определяются случайным образом. Поэтому, для одних и тех же данных могут получаться совершенно разные результаты кластеризации. Второе. Сами кластеры также могут образовывать разные типы структур. Вот, наиболее характерные из них:
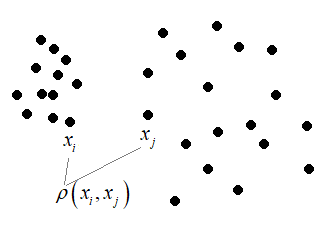
Обратите внимание, в последних двух примерах нет кластеров, как таковых. Геометрические фигуры, как правило, это не тот набор данных, который интересует заказчика (несмотря на то, что наш мозг хорошо их различает). А ниже вообще представлен один кластер. При таком распределении объектов выборки задачу кластеризации ставить бессмысленно. Тем не менее, на практике нередко бывает, что заказчик ставит задачу кластеризации для данных, которые по всем осям образуют такое единое распределение в виде одного кластера и выделить какие-либо отдельные структуры практически невозможно. В этом случае задачу следует скорректировать и решать другими методами. Критерии качества кластеризацииТеперь, когда мы в целом представляем задачу кластеризации, нужно сформулировать критерии для оценки качества разбиения образов по группам. Если мы можем измерять только расстояния между парами любых образов:
и имеем модель, которая выдает номер кластера:
то в качестве критериев можно выделить среднее внутрикластерное расстояние:
(оно должно стремиться к минимуму) и среднее межкластерное расстояние:
(очевидно, оно должно быть как можно больше). Объединить эти две характеристики можно, например, взяв их отношение:
Если же объекты описываются координатами в признаковом пространстве:
то можно дополнительно ввести понятие центра кластера:
и вычислять
Объединить эти две характеристики можно также путем их отношения:
У вас здесь
может возникнуть вопрос, а что это за объекты, для которых можно вычислить
только расстояния между ними, но не центры кластеров? Что значит они не
представлены в признаковом пространстве? Например, это могут быть расстояния
между словами. Само по себе слово – это объект без числовых признаков. Но, тем
не менее, существуют методики, позволяющие определять, насколько одно слово
близко (или далеко) от другого слова. То же самое можно проделывать и со
звуками, последовательностями нуклеотидов в ДНК и РНК и т. п. Существует немало
задач, где мы можем задавать расстояния (метрику), но не признаковое
пространство. Или же, нам отдельные признаки ни к чему и делать дополнительную
работу просто не имеет смысла. Во всех этих случаях можно воспользоваться
характеристиками Постановка задачи частичного обучения (Semi-Supervised Learning – SSL)В заключение этого вводного занятия сформулирую постановку задачи частичного обучения с учителем на основе кластеризации. Давайте предположим, что в обучающей выборке есть небольшая часть (k штук) размеченных объектов:
а, остальные не размеченные:
то есть, мы не
знаем для них целевых значений Очевидно, часть
размеченных данных нам может помочь в задачах кластеризации остальных
которая формирует выходные значения
для неразмеченных данных. И здесь различают два общих подхода к решению этой задачи:
Где используется такой подход частичного обучения? Например, при каталогизации текстов. Когда их нужно сгруппировать по похожести, то есть, соотнести с ранее размеченными текстами (для которых имеются метки категории). То же самое касается любых типов данных, вплоть до изображений, звуков, последовательностей ДНК, и т.д. На этом мы завершим вводное занятие по кластеризации. На следующих продолжим эту тему и рассмотрим конкретные алгоритмы разделения объектов по категориям. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |