|
Сокращение размерности признакового пространства с помощью PCAПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами познакомились с идеей метода главных компонент (PCA – principal component analysis), который позволяет формировать новую ортонормированную систему координат в виде системы собственных векторов матрицы Грама признакового пространства:
В результате, информация локализуется в первых координатных осях:
И здесь
возникает вопрос, почему такая локализация в принципе возможна? За счет чего
это достигается? Ответ прост – за счет наличия линейных зависимостей между
различными признаками
то здесь метод главных компонент позволит выделить такие данные и, при необходимости, исключить их. Давайте я покажу, как это работает на конкретном примере. Пусть первые два признака формируются как нормальные случайные величины с нулевым средним и единичной дисперсией:
(Здесь
Очевидно, третий
признак не несет какой-либо новой информации и приводит только к усложнению
модели. Такие признаки являются коллинеарными к признакам Давайте, теперь, для нашего трехмерного признакового пространства:
вычислим собственные векторы и числа, согласно уравнению:
Я это сделаю на языке Python с использованием пакета NumPy: import numpy as np import matplotlib.pyplot as plt SIZE = 1000 np.random.seed(123) x = np.random.normal(size=SIZE) y = np.random.normal(size=SIZE) z = (x + y)/2 F = np.vstack([x, y, z]) FF = 1/ SIZE * F @ F.T L, W = np.linalg.eig(FF) WW = sorted(zip(L, W.T), key=lambda lx: lx[0], reverse=True) WW = np.array([w[1] for w in WW]) В конце я отсортировал собственные векторы по убыванию собственных чисел. Если теперь вывести на экран собственные значения: print(sorted(L, reverse=True)) то увидим величины: [1.4018930165258354, 0.9841864212968794, 0.0] Смотрите, последнее значение равно нулю. Оно, как раз, соответствует третьему признаку, который мы сформировали, как сумму первых двух. То есть, нулевое (или близкое к нулевому) значение собственного числа говорит нам о сильной линейной зависимости данного признака от других. А, значит, в новом признаковом пространстве:
его можно отбросить. Можно сделать даже несколько радикальнее и отбросить все признаки, у которых собственные числа ниже заданного порога θ:
В результате, мы уйдем от проблемы мультиколлинеарности, сократим сложность модели и с большой вероятностью заметно уменьшим степень переобученности модели. Конечно, порог θ нужно подбирать индивидуально для каждой задачи. Универсального значения здесь нет. Да и метод главных компонент имеет смысл применять, если размерность исходного признакового пространства не превышает десятков тысяч. Если же число коэффициентов модели миллион и более, то здесь уже нужно смотреть в сторону L1-регуляризатора, который, как вы уже знаете, тоже позволяет отбирать признаки, зануляя незначимые коэффициенты. Общность метода главных компонент и L2-регуляризацииИтак, получается, что бороться с переобучением моделей можно, как с помощью регуляризаторов, так и с помощью метода главных компонент, сокращая признаковое пространство. Давайте попробуем понять, что общего у этих двух подходов, а в чем различия. Существует гипотеза, которая гласит: Если собственные
числа Именно это мы
делаем, когда с помощью метода главных компонент отбрасываем признаки А что делает L2-регуляризатор? Давайте посмотрим. На одном из занятий я уже рассказывал, что если применить к задаче регрессии метод наименьших квадратов, то функционал качества можно записать в виде:
Здесь Этот показатель качества удобнее представить в векторно-матричном виде, если ввести следующие обозначения:
Тогда:
Решая аналитически задачу минимизации данного функционала относительно вектора весовых коэффициентов ω:
получаем оптимальное решение:
Так вот,
переобучение здесь возникает, если матрица
где Здесь же нам
интересно узнать, как увеличение элементов главной диагонали
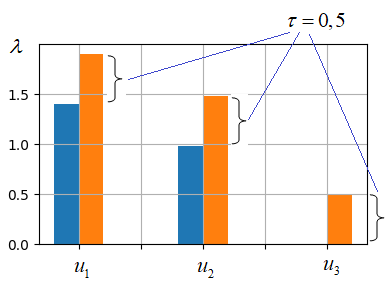
Видите, у нас
все собственные значения увеличились на величину τ и нулевых (или близких
к нулевым) значений теперь нет. Это означает, что каждая координатная ось Таким образом, получается, что и метод главных компонент и L2-регуляризация, по сути, избавляются от мультиколлинеарности векторов признакового пространства. Как следствие, это приводит к заметно не нулевым значениям собственных чисел. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |


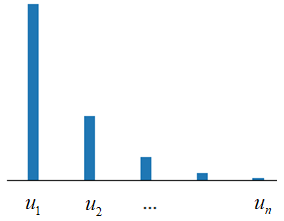
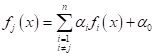



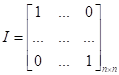 -
единичная матрица. Такой подход еще называют гребневой регрессией и
соответствует L2-регуляризации
коэффициентов ω. Об этом мы также уже подробно говорили, когда
рассматривали L2-регуляризатор.
-
единичная матрица. Такой подход еще называют гребневой регрессией и
соответствует L2-регуляризации
коэффициентов ω. Об этом мы также уже подробно говорили, когда
рассматривали L2-регуляризатор.