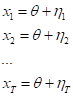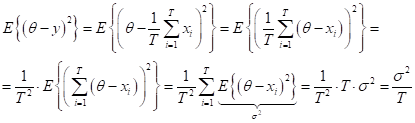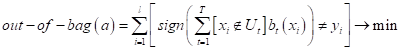|
Случайные деревья и случайный лес. Бутстрэп и бэггингПрактический курс по ML: https://stepik.org/course/209247/ На предыдущих занятиях мы с вами познакомились с идеей построения решающих бинарных деревьев для задач классификации и регрессии. Однако на практике в чистом виде их почти не используют. Но активно применяют в ансамблевых методах, которые включают в себя два весьма эффективных подхода: бэггинг и бустинг. Именно о бэггинге с использованием деревьев и пойдет речь на этом занятии.
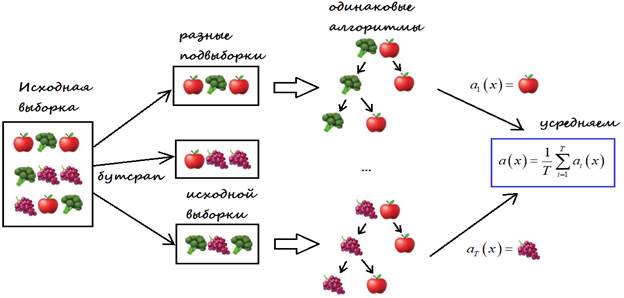
Идея алгоритма очень проста и была предложена Лео Брейманом в 1994 году. Этот подход оказался весьма эффективным и используется до сих пор. Итак, предположим изначально у нас имеется некоторая обучающая выборка:
На ее основе мы
хотим сформировать несколько разных и, в общем случае, независимых алгоритмов
обработки входного вектора
А, затем, усреднить ответы каждого алгоритма для формирования общего решения. Наверное, здесь сразу возникает вопрос, зачем нам искусственно создавать несколько независимых алгоритмов, а потом усреднять их выходы? На самом деле, этому есть вполне логичное объяснение. Одна известная история гласит, как в 1906 году математик Фрэнсис Гальтон посетил рынок и увидел, как продавец быка предложил покупателям небольшую лотерею: угадать точный вес этого быка, который весил 1198 фунтов. От крестьян посыпались самые разные предположения. Но ни один не назвал точное значение. Однако, усреднив все ответы, получилось значение 1197 – очень близкое к истинному. Вот так «мудрость толпы» решила эту непростую задачу.
Эта же идея заложена в бэггинге, когда мы формируем множество независимых алгоритмов, каждый выдает свой вариант ответа, а затем, мы его усредняем, чтобы получить более точное значение. Этот эффект уменьшения ошибки при усреднении ответов легко объяснить с позиции теории вероятностей. Предположим, что верное значение – вес быка – это величина θ. Тогда ответы крестьян можно представить в виде следующей аддитивной модели:
Здесь
с дисперсиями ошибок:
Для простоты, я буду считать, что все ошибки имеют единую дисперсию (разброс значений):
Тогда, дисперсия усредненного ответа:
при условии независимости каждой СВ:
и несмещенности ошибки (нулевого среднего):
равна:
То есть,
дисперсия Обратите внимание, я здесь постоянно подчеркиваю – независимых ответов. Если ответы (предположения о весе быка) будут зависеть друг от друга, то простое усреднение станет уже не лучшим подходом, а в ряде случаев может даже ухудшить отдельные результаты. Поэтому независимость работы алгоритмов при бэггинге является ключевым условием. Бутстрэп (bootstrap)Так как же нам
сформировать T независимых
алгоритмов, используя всего одну обучающую выборку? Здесь есть несколько идей,
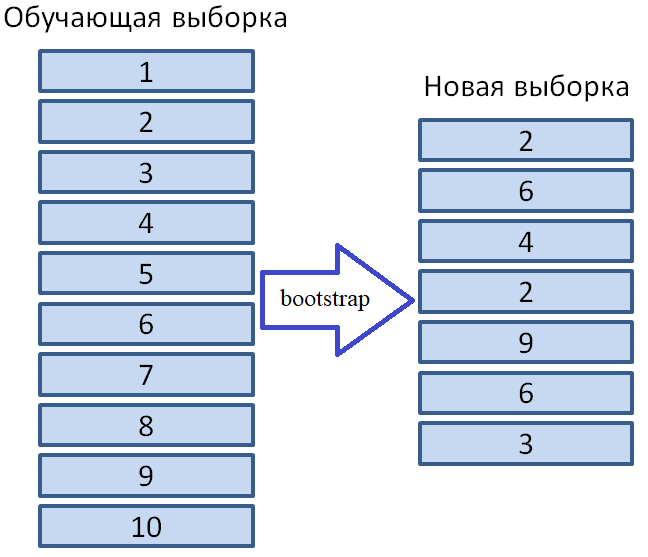
но в бэггинге используется очень простой подход, который носит название бутстрэп
(bootstrap). Суть бутстрэпа
заключается в формировании T новых обучающих
выборок на основе одной исходной
Можно показать,
что формируя, таким образом, новую обучающую выборку длиной
Здесь Бэггинг с решающими деревьями. Случайный лесСобственно, само
слово bagging произошло
от сокращения двух английских слов: bootstrap aggregation. Итак, имея T случайных
выборок длиной m элементов (
можно сформировать T наборов весовых векторов:
каждая для своей обучающей выборки. В результате получаем T различных алгоритмов:
А, затем, усредняя ответы от них, формируем общий результат:
Или, устраивая голосование, решаем задачу классификации:
Как видите, в
теории все просто. Но здесь есть один важный нюанс: алгоритмы в своей
совокупности должны охватывать как можно больше возможных исходов для каждого
входного вектора Как ни странно,
приверженность деревьев к переобучению играет положительную роль. Они,
во-первых, получаются довольно разнообразными и, во-вторых, описывают самые
разные исходы для входных векторов Чтобы решающие
деревья получались еще более разнообразными и формировали менее зависимые
ответы, предлагается при их обучении в каждой промежуточной вершине случайным
образом отбирать некоторое количество признаков
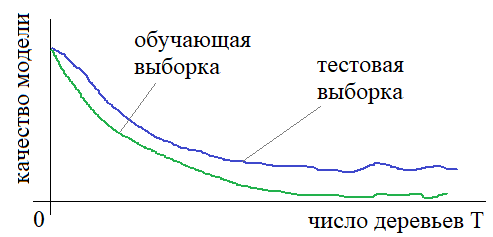
То есть, с ростом числа T решающих деревьев в случайном лесе итоговая модель не переобучается, а лишь достигает некоторого предельного уровня качества. Это очень хорошее свойство случайного леса, так как мы, фактически, получаем алгоритм, в котором нет сложно настраиваемых гиперпараметров. Единственный параметр T можно взять, например, 100, а затем, 500 и сравнить результаты на тестовой выборке. То есть, подобрать его очень просто. Остальные гиперпараметры для построения решающих деревьев можно выбирать с позиции некоего здравого смысла. Главное, чтобы деревья получались глубокими, гарантируя малые смещения в ответах. Напомню, что под смещением здесь понимается стремление к нулю (в среднем) ошибки прогноза:
Реализация случайного леса на PythonВот идея бэггинга с применением случайного леса. Для ее реализации на языке Python в библиотеке Scikit-Learn имеются два класса:
У каждого класса есть следующий набор основных параметров:
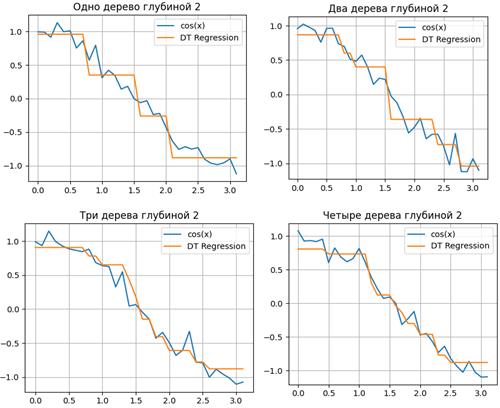
Подробнее о них можно почитать на странице русскоязычной документации: https://scikit-learn.ru/1-11-ensemble-methods/ Ниже представлены результаты аппроксимации функции косинуса с небольшим гауссовским шумом случайными деревьями:
Программу можно скачать по ссылке: machine_learning_41_regression.py
Как видите, при увеличении числа деревьев одной и той же глубины, повышается точность описания исходной функции. Это пример реализации бэггинга на случайных деревьях. Преимущества и недостатки случайного лесаКак и любой алгоритм, случайные леса имеют свои преимущества и недостатки. К преимуществам можно отнести:
Недостатки случайного леса
Практический курс по ML: https://stepik.org/course/209247/ Видео по теме |