|
Решающие деревья в задачах регрессии. Алгоритм CARTПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущих
занятиях мы с вами рассматривали решающие деревья для задач классификации. Однако,
в ряде случаев, их применяют и для задач регрессии, когда алгоритм на выходе
формирует одно вещественное значение (или несколько значений) для каждого
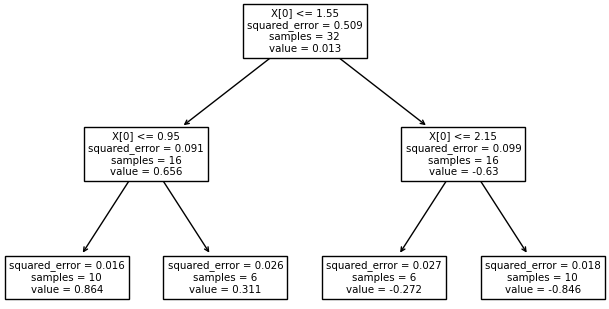
входного вектора Давайте, для определенности, я сразу приведу пример такого решающего дерева.
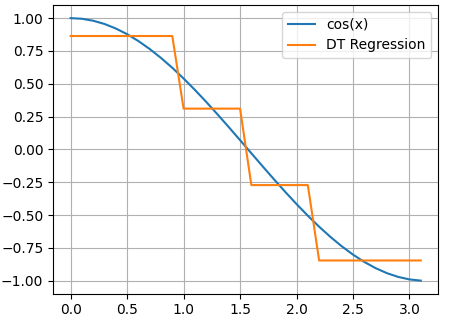
Смотрите, изначально наши данные представляют собой точки функции cos(x):
Здесь аргумент
функции cos() – это
признак, а значения функции в каждой точке – целевые переменные. Затем, по
признаку Вот общая идея использования решающих деревьев для задач регрессии. И здесь возникают два главных вопроса:
Хорошая новость, что на оба этих вопроса имеется единый ответ. Я начну с последнего. Часто в задачах регрессии требуется обеспечить минимум среднеквадратичной ошибки прогноза:
Здесь Так как при
использовании решающих деревьев каждое подмножество
то для
минимизации квадратичного критерия, величину
Можно легко
доказать, что эта величина будет наилучшим образом описывать значения Так как величина
То есть, мы
будем выбирать порог t так, чтобы impurity левого и
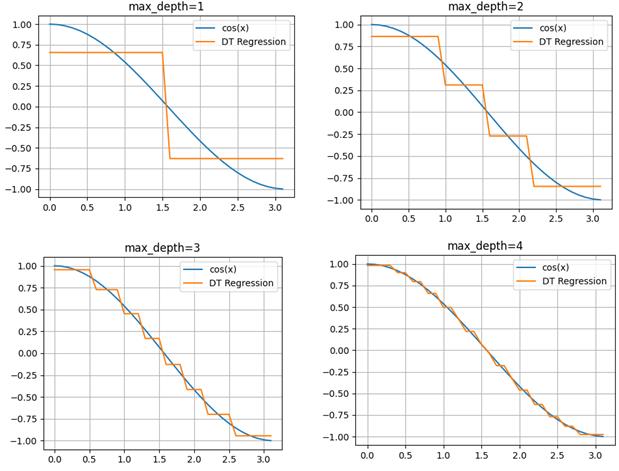
правого подмножеств Вот примеры разбиения исходной последовательности деревом глубиной от единицы до четырех:
Как видите, вначале выделяются два равных подмножества и две константы, которые грубо описывают график косинусоиды. И это описание наилучшее с точки зрения квадратического критерия. При увеличении глубины, получаем все больше и больше информации об исходном сигнале, и для глубины 4 вполне угадывается график косинусоиды. Реализация решающих деревьев на Python с помощью Scikit-LearnИтак, мы с вами в целом познакомились с идеей решающих деревьев для задач классификации и регрессии. Осталось узнать, как можно реализовать эти подходы при решении практических задач. В самом простом варианте это можно сделать на языке Python с использованием библиотеки Scikit-Learn. В этой библиотеке имеется ветка: from sklearn import tree которая отвечает за построение решающих деревьев. Разработчики Scikit-Learn использовали алгоритм: Classification and Regression Trees (CART) с помощью которого можно выполнять как классификацию, так и решать задачи регрессии. Подробнее об этом можно почитать на странице официальной документации: https://scikit-learn.org/stable/modules/tree.html Давайте, вначале построим решающее дерево для задачи регрессии. Для этого сформируем обучающее множество в виде значений функции косинуса: import numpy as np import matplotlib.pyplot as plt x = np.arange(0, np.pi, 0.1).reshape(-1, 1) y = np.cos(x) И, затем, по этому набору данных построим решающее дерево с максимальной глубиной 3: clf = tree.DecisionTreeRegressor(max_depth=3) clf = clf.fit(x, y) После этого выполним прогноз по значениям x: yy = clf.predict(x) и отобразим полученные графики (результаты): plt.plot(x, y, label="cos(x)") plt.plot(x, yy, label="DT Regression") plt.grid() plt.legend() plt.show() Вот так достаточно просто используются решающие деревья, применительно к задачам регрессии. Дополнительно можно вывести структуру полученного дерева с помощью команды: tree.plot_tree(clf) По умолчанию класс DecisionTreeRegressor использует критерий минимума квадрата ошибки прогноза так, как мы говорили на этом занятии. Но, при необходимости, можно воспользоваться и другим критерием – минимума модуля ошибки прогноза. Подробно об этом написано в официальной документации (по ссылке, что приведена выше). Дополнительно у класса DecisionTreeRegressor имеются и другие параметры для управления построением дерева. Все это можно посмотреть в документации. Решающие деревья для задач классификацииПри решении задач классификации используется класс DecisionTreeClassifier библиотеки Scikit-Learn: from sklearn.tree import DecisionTreeClassifier У него также много разных входных параметров для управления построением дерева. Обо всем подробно можно почитать в официальной документации. Здесь же отмечу, что по умолчанию используется критерий Джини в качестве impurity и методика усечения дерева (pruning). Давайте применим этот класс для разделения цветков ирисов по видам. Программу можно посмотреть по адресу: machine_learning_40_classification.py Думаю, из этих занятий у вас сложилось общее представлении об идее решающих деревьев для задач классификации и регрессии. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |