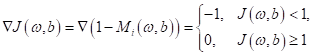|
Реализация метода опорных векторов (SVM)Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами рассмотрели оптимизационную задачу для метода опорных векторов, получили следующую систему:
и из нее пришли к алгоритму для поиска параметров ω и b:
Для минимизации этого функционала обычные градиентные методы нам не подходят, т.к. функция потерь здесь непрерывная, но не гладкая (производные не существуют в точке перегиба). Как вариант можно воспользоваться субградиентными методами, то есть, вычислять производную по правилу:
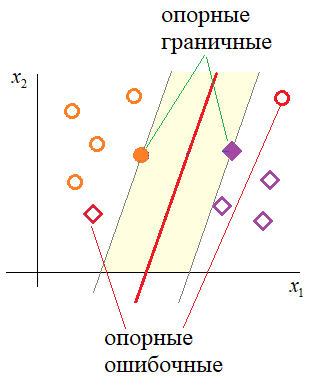
Но изначально решение задачи оптимизации метода опорных векторов сводился к решению системы (*). То есть задаче квадратичного программирования, минимизации коэффициентов ω при линейных ограничениях в виде неравенств. Такой подход приводит к достаточно эффективным численным методам и, кроме того, позволяет выделить объекты (наблюдения), на основе которых рассчитываются коэффициенты ω и b. Это интересная дополнительная информация о структуре обучающей выборки. Я не буду приводить подробный вывод задачи квадратичного программирования для системы (*). Для тех, кто хочет погрузиться в эту математику, скажу лишь, что здесь используется условие Каруша-Куна-Таккера с поиском седловой точки функции Лагранжа. В итоге мы приходим к тому, что коэффициенты ω могут быть вычислены по формуле:
где Вообще, значения коэффициентов λ можно интерпретировать, следующим образом:
Реализация SVM на PythonДавайте теперь посмотрим, как можно применить всю эту математику в конкретной практической задаче бинарной классификации. Я снова возьму ту же самую задачу линейно разделимых образов гусениц и божьих коровок:
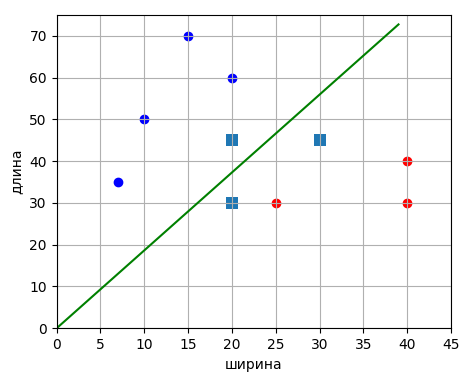
И воспользуемся готовой реализацией метода опорных векторов из библиотеки Scikit-Learn: from sklearn import svm Готовую реализацию можно посмотреть в файле: После запуска программы увидим следующие значения коэффициентов вектора ω: [ 0.24371833 -0.13071248 0.01218592] (здесь последний
коэффициент – это смещение b). А также список опорных векторов, для
которых [[20. 45. 1.] [20. 30. 1.] [30. 45. 1.]] Визуализация этих данных дает нам следующую картину:
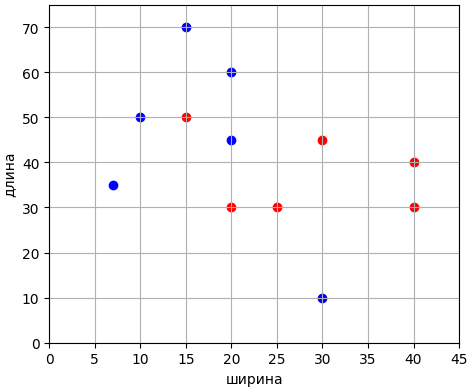
Как видим, разделяющая линия действительно проходит по центру полосы, образованной опорными векторами. Давайте добавим в выборку два новых образа, которые будут являться выбросами и сделают выборку линейно неразделимой:
Получим следующее распределение наблюдений:
Реализуем SVM для такого случая. Здесь мы будем использовать только класс SVC, так как прежний LinearSVC применим только к линейно разделимой выборке. Программу можно посмотреть в файле: После запуска мы увидим качество классификации: [-2 2 0 0 0 0 0 0 0 0 0 0] (здесь нули соответствуют верной классификации, а не нулевые значения – ошибочной). Как видим, классификатор ошибся только на двух первых наблюдениях, в которые мы прописали выбросы, то есть, он корректно построил разделяющую гиперплоскость. Кроме того, видим список опорных векторов: [[30. 10. 1.] [20. 60. 1.] [20. 45. 1.] [ 7. 35. 1.] [15. 50. 1.] [20. 30. 1.] [25. 30. 1.] [30. 45. 1.]] и их стало заметно больше предыдущего случая (при линейно разделимой выборке). Я надеюсь, что из последних двух занятий у вас сложилось представление о принципах работы метода опорных векторов и его реализации на Python с использованием пакета Scikit-Learn и линейным классификатором. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
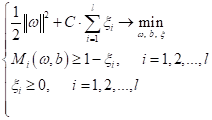 (*)
(*)