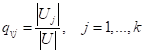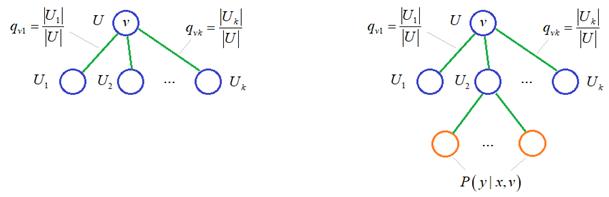|
Усечение (prunning) дерева, обработка пропусков и категориальных признаковПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами рассмотрели алгоритм классификации ID3, который реализует жадную стратегию при построении решающих деревьев и использует энтропию для вычисления информативности (impurity) текущих вершин.
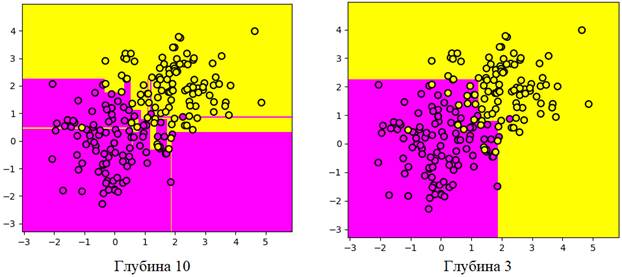
Однако, часто дерево в результате получается сильно переобученным, то есть, слишком хорошо подгоняется под данные обучающей выборки, что резко снижает качество прогнозирования на отложенной (тестовой) выборке. Разумным решением здесь кажется ограничить глубину решающего дерева и, таким образом, повысить его обобщающие способности. Как я уже отмечал, процедура усечения дерева после его построения по обучающей выборке, называется pruning. В отличие от контроля глубины непосредственно при его построении. Этот процесс уже носит название pre-pruning или early stopping. Сейчас речь пойдет именно о pruning – усечения дерева после его обучения (построения). Усечение дерева (pruning)Так как мы имеем дело с переобучением (overfitting), то нам понадобится контрольная выборка. Именно на ней следует определять качество прогноза решающего дерева. Контрольная выборка, как правило, формируется из 30% объектов исходных размеченных данных, а 70% составляет, собственно, обучающая выборка. Далее, мы перебираем все внутренние вершины дерева:
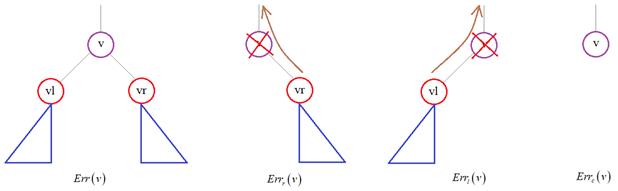
Опустим детали, в каком порядке это делается: вершины в одних алгоритмах перебираются снизу вверх, проходя все выше и выше до корня дерева, а в других, наоборот, от корня – до листовых. Для каждой
текущей внутренней вершины v мы определяем множество объектов Если же
множество объектов
Выбираем вариант с наименьшей ошибкой, которая вычисляется по контрольной выборке. В результате, мы либо оставляем все как есть, либо усекаем правое или левое поддерево, либо превращаем вершину в листовую. Вот в целом идея обрезки решающего дерева. И такая процедура рекомендуется, когда дерево строится в соответствии с жадным алгоритмом, т.к. высока вероятность, что оно окажется переобученным. Обработка пропусков в данныхНа данном этапе вы
должны хорошо себе представлять идею построения решающих деревьев по жадному
алгоритму и их усечение для повышения обобщающих способностей. Но один важный
вопрос у нас остался в стороне. Как выполнять обработку реальных данных
(входных векторов О чем здесь речь?
Давайте представим, что у нас имеется следующий фрагмент решающего дерева. Чтобы
обработать вектор
Здесь существует
несколько подходов решения этой задачи. Я приведу математический алгоритм, как
приверженец строгой математики. Итак, у нас имеется обучающая выборка
Если вершина v является
листовой, то вероятность того, что вектор
То есть, мы в
листовой вершине подсчитываем представителей класса Зная вероятности:
мы можем рекуррентно их пересчитывать для любой промежуточной вершины по формуле:
То есть,
проходим по ветвям вершины v и суммируем вероятности листовых вершин
А дальше все
просто. Если в какой-либо промежуточной вершине v для вектора
На мой взгляд,
это достаточно стройный и логичный алгоритм обработки пропущенных признаков для
входных векторов Обработка категориальных признаковДо сих пор мы
считали, что вектор
Но не редко встречаются задачи, когда какой-либо признак (а может быть и несколько) относятся к категориальным, то есть, принимают одно из заданного множества значений. Например, это может быть пол человека, или город, в котором он живет, и т.п.:
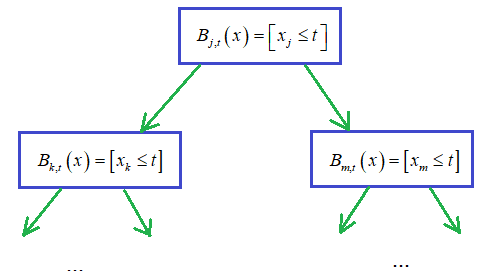
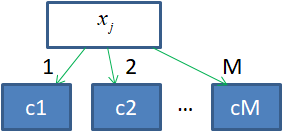
Как правильно их обрабатывать с помощью решающих деревьев? Давайте вначале обобщим запись для категориальных признаков, следующим образом:
Здесь C – это множество
из M возможных
категорий. И j-й признак
вектора
Если мы теперь будем вычислять показатель качества разбиения для такой вершины так, как это делали для обычных числовых признаков, то получим выражение вида:
Напомню, что здесь
это impurity
(информативность) вершины дерева. Так вот, выражение Существуют
методики обхода этих проблем, например, через добавление регуляризационного
множителя в формуле Опять же, в самом простом варианте, мы можем просто-напросто разбить все множество категорий на два непересекающихся множества:
А, затем, определить предикат, например, вида:
То есть, здесь
нам необходимо определить (подобрать) содержимое множеств
вариантов разбиений. Как вы понимаете, даже при небольшом числе M (от 10 и выше) мы получаем огромное количество вариантов. Выбрать из них лучшее простым перебором оказывается вычислительно очень сложно. Вы можете сказать, а почему бы нам не воспринимать номера категорий, как числовой признак и не использовать его наряду с другими? И формировать предикат уже знакомого нам вида:
Это вполне
разумная идея, только здесь есть один нюанс. Давайте представим, что наше
решающее дерево связано с определением (прогнозом) уровня оплаты труда для
некоторого индивида, представленного признаками входного вектора
Как видите, здесь уровень заработной платы то возрастает, то убывает с номером категории. Поэтому, увеличение порога t здесь не будет иметь прямую взаимосвязь с размером заработка. Например, если взять предикат:
то последняя 5-я категория не будет соответствовать максимальной оплате труда. А числовые признаки должны интерпретироваться именно так: чем больше номер категории, тем выше оплата труда. По этому примеру, я думаю, вы уже догадались, что достаточно упорядочить категории по целевому значению и тогда их номера можно воспринимать как числовые признаки:
Вот общий принцип, положенный в основу обработки категориальных признаков как числовых. На практике, именно он чаще всего и используется. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |