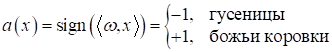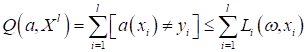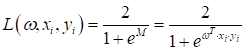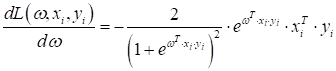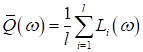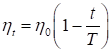|
Пример использования SGD при бинарной классификации образовПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами познакомились с двумя подходами к реализации псевдоградиентных алгоритмов – это SGD и SAG. Чтобы в дальнейшем этот теоретический материал лучше воспринимался, на этом занятии я приведу пример использования SGD для все той же задачи бинарной классификации гусениц и божьих коровок. Напомню, что у нас с вами имеется следующая обучающая выборка:
И нужно построить линейный классификатор:
который выдает
-1 гусениц и +1 – для божьих коровок. То есть, целевые выходы Как всегда будем минимизировать эмпирический риск непрерывной функцией потерь:
В этот раз выберем сигмоидную функцию в качестве loss function:
Ее производная
по
Таким образом, у
нас есть все исходные данные для нахождения вектора параметров
1) инициализация
весов 2) начальное вычисление функционала качества:
3) цикл 4) случайный выбор
наблюдения 5) вычисление
функции потерь 6) шаг
псевдоградиентного алгоритма: 7) пересчет
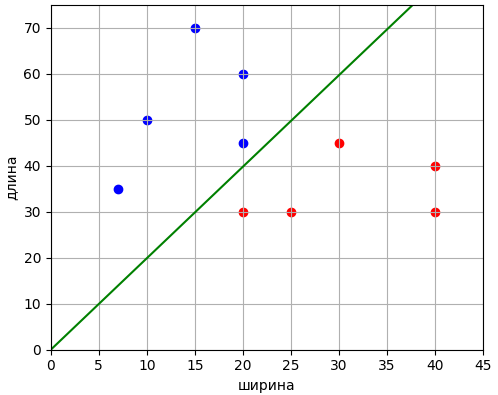
функционала качества: 8) пока Реализуем теперь эти шаги на языке Python. Программу можно скачать по ссылке: После запуска увидим следующие значения коэффициентов: [ 0.32536188 -0.16612466 0.00541073] и график разделяющей линии для двух классов:
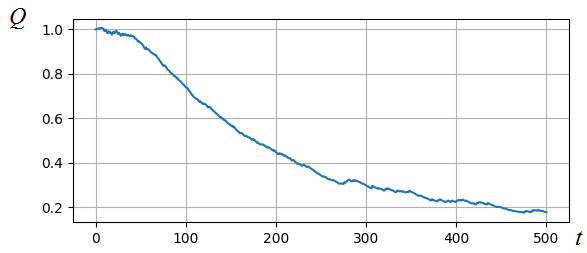
Как видите, мы смогли найти решение с помощью довольно простой реализации алгоритма стохастического градиентного спуска. Если дополнительно посмотреть на график показателя качества на разных итерациях, то видно, как он на протяжении всех 500 итераций постепенно уменьшается:
Конечно, это не самое лучшее решение и, очевидно, можно подобрать параметры так, чтобы сходимость была более быстрой. Например, уменьшать шаг по линейному закону:
или экспоненциальному:
Здесь T – параметр, определяющий скорость уменьшения шага обучения. Некоторые другие рекомендации по выбору шага обучения можно посмотреть на занятии, посвященном градиентному алгоритму: https://www.youtube.com/watch?v=OKeZEbJgQKc&list=PLA0M1Bcd0w8yZNgl5J814WQykTZnzj771&index=3 Я предлагаю вам в качестве практики поиграться гиперпараметрами этого алгоритма и попробовать найти лучшее решение. Вообще, глядя на реализацию SGD, можно увидеть следующие его преимущества:
Ну а недостатки общие, присущие всем градиентным алгоритмам:
На последующих занятиях мы с вами посмотрим, как можно бороться с проблемами переобучения и застревания в локальных оптимумах градиентных алгоритмов. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме | |||||||||||||||||||||||||||||||||||||||||||||||||||||||