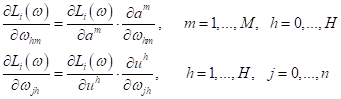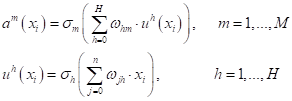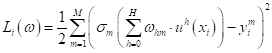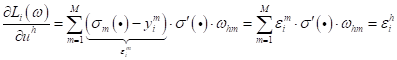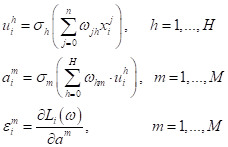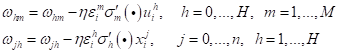|
Обучение нейронной сети. Алгоритм back propagationПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами в целом познакомились с идеей полносвязных нейронных сетей (НС) и рассмотрели несколько простейших примеров. И здесь самой главной и сложной задачей является обучение таких структур. Я напомню, что нейронные сети относятся к параметрическим алгоритмам:
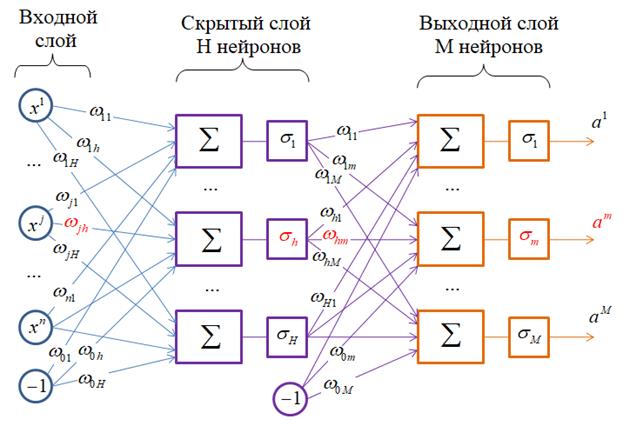
где Давайте, для определенности, возьмем структуру двухслойной НС:
Здесь весовые
коэффициенты – это веса связей
и минимизировать функционал качества (эмпирический риск):
В общем случае задачу минимизации можно решить численно с помощью градиентного алгоритма. Учитывая, что обучающие выборки для НС, как правило, очень большие, то применяют стохастический градиентный алгоритм: Вход: обучающая
выборка Выход: вектор весовых
коэффициентов 1: инициализировать
веса 2: повторять 3: выбрать
случайный образ 4: вычислить
значение функции потерь: 5: корректировка
весов: 6: пересчет
значения функционала: 7: пока значение Но оказывается
такой классический подход, который мы применяли к линейным алгоритмам с
небольшим числом параметров вектора
где K – число слоев НС. Алгоритм получил название back propagation (обратное распространение ошибки). В плейлистах по НС я приводил принцип его работы без математического вывода. Поэтому здесь восполню этот пробел и приведу математический вывод этого алгоритма применительно к полносвязной двухслойной НС прямого распространения. Но этот результат, затем, легко обобщается на НС с произвольным числом слоев. Вывод алгоритма back propagationВывод алгоритма back propagation я взял из курса лекций профессора Воронцова, как наиболее простой из всего, что я видел: https://www.youtube.com/watch?v=zbdgUZAzfQg Наша цель
научиться корректировать веса
Для дальнейших выкладок нам нужно определиться с видом функции потерь. Для простоты возьмем квадратическую функцию (но те же самые выкладки можно повторить с любой другой дифференцируемой функцией потерь):
где
Теперь мы можем записать конкретное выражение для частной производной:
А перед
вычислением другой частной производной
Отсюда мы явно
видим зависимость функции потерь от
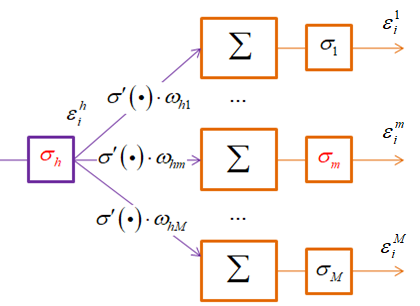
Эта последняя
формула показывает, как вычисляется величина
По аналогии мы можем вычислять такие ошибки для любых промежуточных слоев в многослойных НС. Теперь у нас есть все, чтобы вычислить итоговые градиенты функции потерь по весам НС:
и
Все, мы знаем как вычисляются частные производные по всем весам связей НС и можем их корректировать с помощью градиентного алгоритма. Псевдокод алгоритма back propagation для нашей двухслойной НС можно записать следующим образом: Вход: обучающая
выборка Выход: вектор весовых
коэффициентов 1: инициализировать
веса 2: повторять 3: выбрать
объект 4: прямой ход: 5: пересчитываем
функционал качества: 6: обратный ход: 7: градиентный шаг: 8: пока Преимущества и недостатки алгоритма back propagationИтак, благодаря алгоритму back propagation мы получаем следующие преимущества:
К недостаткам этого подхода можно отнести:
Но все эти проблемы, в общем то, вытекают из самого градиентного алгоритма и присущи всем оптимизационным подходам такого типа. Нейросети здесь не исключение. Но эти недостатки относительно успешно преодолеваются различными эвристиками. В частности, против застревания в локальных оптиумах используют оптимизаторы, о которых мы подробно говорили вначале этого курса. Проблема переобучения преодолевается с помощью метода Dropout, о котором я подробно рассказываю в плейлите по НС. А ускорение обучения в глубоких НС достигается за счет применения идеи статистической нормализации по мини-батчам – Batch Normalization. Обо всем этом и многих других моментах, связанных с проектированием и обучением нейронных сетей различных структур, смотрите в плейлистах по нейронным сетям на этом канале. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |