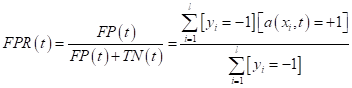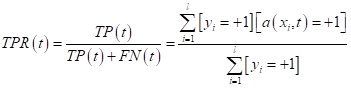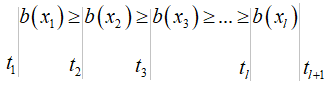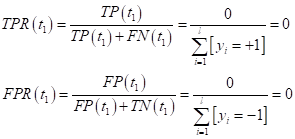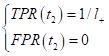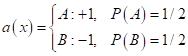|
Метрики качества ранжирования. ROC-криваяПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Продолжаем знакомиться с метриками качества оценок моделей при бинарной классификации. И на этом занятии мы затронем вопрос весьма важный вопрос оценки качества моделей ранжирования. Но вначале определимся, что это за класс моделей. Рассмотрим
классический пример удержания клиентов банка, сотового оператора или еще
какой-либо организации. Нам поставили задачу по разработке модели, которая бы
прогнозировала по некоторым признакам
Конечно, модель делает лишь предположение. Уйдет клиент на самом деле или нет нам неизвестно. Мы можем это узнать только спустя какое-то время. Но на всякий случай таких «неуверенных» клиентов было бы хорошо обзвонить и сделать им «приятное» предложение, чтобы удержать. Однако, ресурсы любой организации ограничены и обзванивать всех таких клиентов может оказаться очень накладно. Поэтому здесь лучше выделить самых «неуверенных», которые с наибольшей вероятностью собираются перейти в другой банк. И возникает вопрос, как определить этих самых «неуверенных»? Для этого поступают следующим образом. Сортируют всех клиентов по значениям скалярного произведения:
Получаем таблицу:
Здесь самые
первые (верхние) клиенты – это наиболее «неуверенные», те, что с наибольшей
вероятностью покинут учреждение в ближайшем будущем, а чем ниже, тем все более
лояльные. Причем, мы можем по историческим данным (или спустя какое-то время)
определить, как реально себя повел тот или иной клиент (ушел или остался) – это
целевые значения Так вот, при ограниченных ресурсах call-центра, было бы логично выделить в этой таблице несколько первых клиентов и именно им делать предложение, от которого они не смогут отказаться и, таким образом, удержать их. Математически это можно записать, следующим образом:
Здесь t – это некоторый
порог (число), по которому разделяются клиенты на нелояльных (+1) и лояльных
(-1). Устанавливая, например, этот порог больше нуля, мы будем выделять
наименее лояльных клиентов с точки зрения модели. Причем, пороговое значение –
это переменная величина и может меняться, выделяя более или менее лояльных
клиентов, например, в зависимости от нагрузки call-центра. В этом
ключевая особенность работы алгоритмов ранжирования. Нам приходится
разрабатывать модель, не зная конкретного порогового значения, то есть, она в
целом (для любых порогов) должна давать хорошие прогнозы поведения
пользователей. Например, если при некотором пороге t, упорядоченные по
убыванию значения скалярного произведения, будут соответствовать чередованию
целевых значений ROC-криваяВообще,
идеальная модель ранжирования – это та, у которой после сортировки целевые
значения
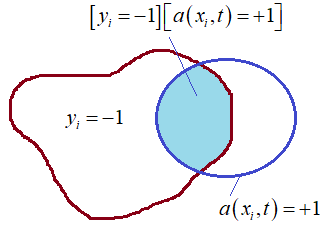
Величину
Внимательный зритель здесь сразу отметит, что метрика
то, что мы
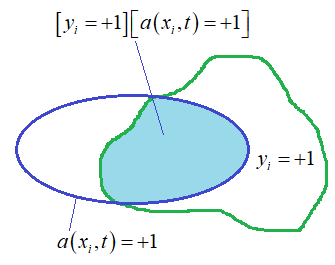
рассматривали на предыдущем занятии. Причем, формально величины Итак, у нас есть
две характеристики
Для этого мы будем перебирать значение параметра t в диапазоне:
где Сначала выбираем
порог
Получаем, что
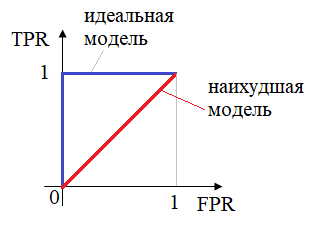
график ROC-кривой исходит
из нуля (0; 0). Далее предположим, что у нас идеальная модель, т.е. она не
совершает ошибок (полностью совпадает с целевыми значениями
(здесь Далее, переходя к отрицательным классам, у нас все будет наоборот – TPR остается без изменений, равный 1, а FPR станет постепенно увеличиваться, доходя до 1. В результате, для идеальной модели график ROC-кривой будет иметь вид (синяя линия):
А вот для наихудшей модели, которая прогнозирует значения бинарного класса с вероятностью 1/2:
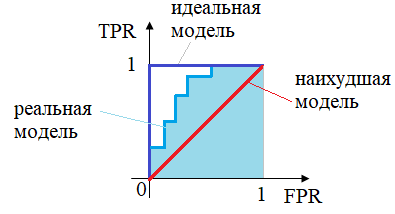
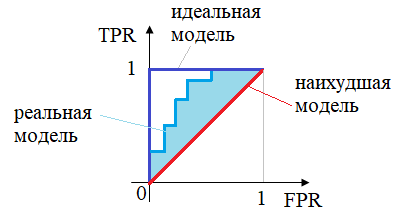
ROC-кривая будет примерно лежать на диагонали (красная линия). Как вы уже догадались, реальные модели с небольшим числом ошибок прогнозов, лежат между красной и синей кривыми:
Отлично, ROC-кривую мы научились строить, но как теперь по ней получить числовую характеристику качества модели? Здесь есть два распространенных подхода. В первом случае просто берут площадь под ROC-кривой. Такая характеристика называется AUC-ROC, и чем она больше, тем качественнее модель. Для идеальной модели площадь равна 1, а для худшей – 1/2. Хорошими считаются модели, у которых площади больше 0,9. То есть, показатель AUC-ROC показывает, насколько хорошо модель сортирует (ранжирует) объекты класса. Во втором случае вычисляют меру разности площадей между ROC-кривыми реальной модели и наихудшей, по следующей формуле:
То есть, это удвоенная разность между площадью ROC-кривой анализируемой модели и наихудшим случаем:
Такой показатель называют индексом Джини или коэффициентом Джини. Но это лишь несколько иной взгляд на ту же самую площадь под ROC-кривой. Основным недостатком этих показателей (AUC-ROC и индекс Джини) является плохой учет в их значениях несбалансированности классов. Например, если к положительному класс относятся 100 объектов, а к отрицательному 1 000 000, то площадь под ROC-кривой получится большой (выше 0,9), но при этом ранжирование объектов может быть очень плохим. Вот этот момент следует учитывать, пользуясь данными характеристиками качества ранжирования. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |