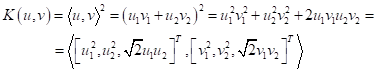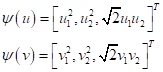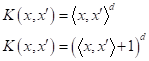|
Метод опорных векторов (SVM) с нелинейными ядрамиПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии я отметил, что для линейного бинарного классификатора вида:
коэффициенты ω в методе опорных векторов могут быть вычислены по формуле:
где Если объединить эти две формулы, то получается, что:
(здесь сумма
взята не по всем объектам, а только по опорным, для которых Отсюда хорошо
видно, что классификатор вычисляет взвешенную сумму скалярных произведений
опорных векторов
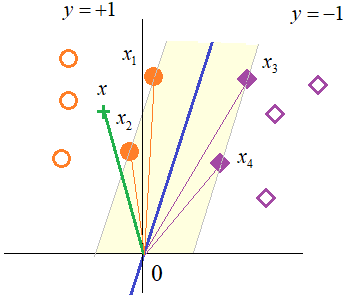
Пусть у нас
линейно разделимая выборка с четырьмя граничными векторами
Или, ее можно записать в таком виде. Сначала суммируем опорные векторы для одного и второго классов образов:
А, затем, на который из них приходится наибольшая проекция вектора x:
Классификатор просто берет знак от этой величины и выдает свое решение:
Вот так можно интерпретировать работу линейного бинарного классификатора в методе опорных векторов. SVM с нелинейными ядрамиНо давайте вернемся к общей формуле модели линейного классификатора:
и зададимся вопросом, а что если линейные преобразования:
в исходном признаковом пространстве заменить какими-либо нелинейными? Например, взять, и возвести это скалярное произведение в квадрат:
Сможем ли мы
тогда повторить все те же вычисления для нахождения опорных векторов и
коэффициентов Вообще существует теорема, которая гласит: Функция
для любой Я привел эту теорему лишь формально. На практике ей руководствоваться достаточно сложно (как говорят, она не конструктивна). Но, в частности, преобразование:
удовлетворяет этой теореме. Давайте распишем его для двумерных векторов:
получим:
То есть, возведение скалярного произведения в квадрат двумерных векторов – это аналог скалярного произведения трехмерных векторов:
Фактически,
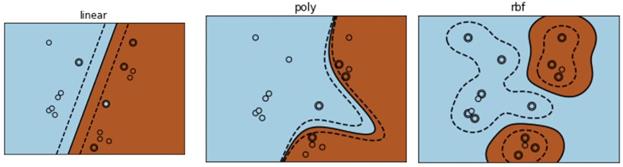
функция Я приведу характерные рисунки, взятые из официальной документации Scikit-Learn разделяющих гиперплоскостей для разных типов ядер:
Здесь linear – обычное скалярное произведение; poly – полиномиальное ядро, образуемое функциональными преобразованиями вида:
rbf – радиальные ядра, определяемые выражением:
В практике SVM еще можно встретить ядро вида:
На его основе получается аналог двухслойной нейронной сети с сигмоидальными функциями активации. SVM как двухслойная нейронная сетьВас может немного удивить, причем здесь нейронная сеть, когда мы говорим о совершенно иной структуре алгоритма на основе разделяющей гиперплоскости? Но на самом деле SVM можно представить в виде следующей вычислительной структуры. Так как выход модели при произвольных ядрах вычисляется по формуле:
то имеем:
То на скрытом
слое у нас вычисляются свертки входного вектора x с опорными
векторами Способы синтеза ядерВ заключение этого занятия отмечу несколько простых правил синтеза ядер для метода опорных векторов. К основным можно отнести следующие подходы:
Существуют и некоторые другие способы синтеза ядер. Но часто на практике использует довольно ограниченный класс – это линейные, полиномиальные, радиальные и гиперболический тангенс. Обычно их вполне хватает для большинства задач и именно такие ядра встроены в пакет Scikit-Learn для метода опорных векторов. Причем, для каждого типа ядра вычислительная схема SVM несколько меняется. Поэтому нельзя сформировать универсальный функционал для произвольных ядер (если, конечно, не использовать субградиентные методы). Преимущества и недостатки SVMИтак, если нам удается свести задачу к методу опорных векторов, то мы автоматически получаем следующие преимущества перед субградиентыми методами и нейронными сетями:
Конечно, универсальных методов в природе не существует и SVM присущи ряд недостатков:
Тем не менее, считается, что SVM является лучшим методом классификации среди прочих линейных классификаторов. Благодаря максимизации ширины полосы между классами, он, как правило, приводит к лучшим обобщающим способностям на реальных данных. Его относительно легко модифицировать для нелинейного случая (для разных ядер), а также дополнительно использовать L1-регуляризатор. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |