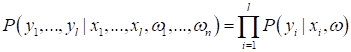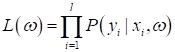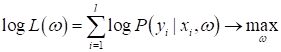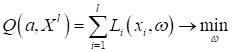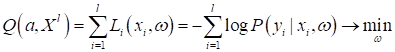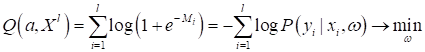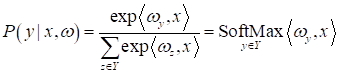|
Логистическая регрессия. Вероятностный взгляд на машинное обучениеПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Давайте представим следующую задачу бинарной классификации. Пусть некий банк выдает кредиты заемщикам. Для этого он требует следующие сведения (помимо персональных данных):
Смотрите, что здесь получается. Для одинаковых объектов (наблюдений) целевое значение может меняться: кредит иногда возвращают, а иногда нет. То есть, у нас должна быть параметрическая модель, например, линейная:
которая для
одного и того же вектора
Данная условная
вероятность показывает вероятность появления прогнозируемого класса моделью
вероятность:
А противоположную вероятность (для класса -1), можно вычислить как:
Фактически, наша модель должна выдавать вещественное число в диапазоне [0;1]:
и это, в некотором смысле, роднит ее с задачей регрессии. Чтобы решить
поставленную задачу, нам нужно понять, как вычислять вектор весов
То есть, мы
выбираем такое Если вы не знакомы с методом максимального правдоподобия, то советую посмотреть занятие, посвященное этой теме: https://www.youtube.com/watch?v=hO-pATDf75k Однако, у нас с вами не одно какое-то наблюдение, а целая обучающая выборка, которая описывается, в общем случае, многомерной величиной:
Но для задачи
оптимизации нам нужно как-то конкретизировать это выражение. И вот здесь, в
машинном обучении, делают довольно сильное предположение: пусть все объекты
Такое упрощение многомерного распределения соответствует задаче, известной под названием наивный байесовский классификатор (Naive Bayes classifier). Причем, в эту
формулу мы подставляем конкретные значения
Такая функция
получила название функции правдоподобия и для поиска наилучших значений
вектора
Но искать максимум от произведения величин не очень удобно. Поэтому часто переходят к логарифму правдоподобия (log-likelihood, log-loss):
Мы всегда можем это делать, так как функция логарифма монотонно-возрастающая, а значит, никак не влияет на положение точки максимума функции. А теперь смотрите, ранее при решении задач классификации, мы с вами вводили функционал, аппроксимирующий эмпирический риск некоторой выбранной функцией потерь:
Видите сходство этих двух критериев качества? Только в одном случае мы максимизируем, а в другом – минимизируем. Но это легко свести к единой задаче минимизации и записать следующее равенство:
Отсюда следует важный, ключевой вывод: вероятностный взгляд на задачи машинного обучения и взгляд через определение моделей с функциями потерь – это, фактически, одно и то же. Мы совершенно спокойно можем переходить из модельной плоскости в вероятностную и обратно при решении любых задач машинного обучения. Если теперь в качестве функции потерь выбрать логарифмическую:
чтобы сходство обеих сумм было еще больше. Я напомню, что
отступ для i-го образца,
показывающий, насколько далеко он находится от разделяющей гиперплоскости. Для
корректного вычисления отступа для обоих классов, целевые выходы должны быть
В результате, мы имеем:
Откуда следует, что:
или в виде:
То есть, логарифмическая функция потерь приводит нас к достаточно простой формуле построения оценок вероятностей для прогнозируемого класса. Причем, функция:
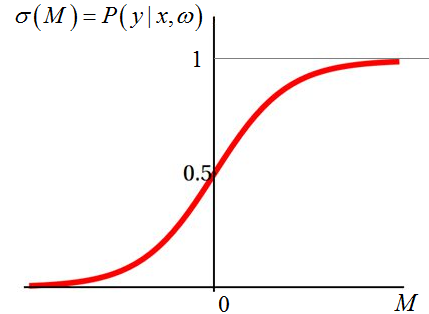
называется сигмоидальной и непосредственно связана с логарифмической (логистической) функцией потерь. Отсюда и пошло название такого класса задач – логистическая регрессия. График сигмоиды выглядит, следующим образом:
И из него хорошо
видно, что чем дальше от разделяющей гиперплоскости находится правильно
спрогнозированный класс (M > 0), тем выше значение вероятности
(уверенности) классификатора, что прогноз верен. И, наоборот, если знак отступа
отрицательный (M < 0), значит, произошла ошибка классификации и
вероятность будет меньше 0,5. Если же образ оказался точно на разделяющей
гиперплоскости, то на выходе увидим значение 0,5, то есть, классификатор не
уверен, к какому классу отнести текущий вектор Многоклассовая логистическая регрессияВ заключение
этого занятия скажу несколько слов про многоклассовую логистическую регрессию.
Она используется, когда решается задача M-классовой
классификации, причем образы не пересекаются. В этом случае для каждого класса
наибольшее. Затем, для вычисления вероятности правильного выбора, можно воспользоваться следующей формулой:
которая носит название функции softmax. Она довольно часто используется на практике, в частности в нейронных сетях, когда входной вектор нужно отнести к одному из M классов. Тогда на выходе сети прописывают функцию softmax и получают некий аналог вероятностей отнесения объекта к тому или иному классу. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |