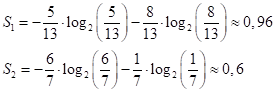|
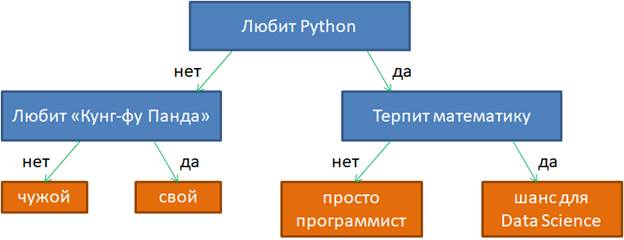
Критерии качества для построения решающих деревьевПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами познакомились с общей идеей логических методов. Здесь же продолжим эту тему и подробнее поговорим о бинарных решающих деревьях. Приведу пример такого дерева из предыдущего занятия:
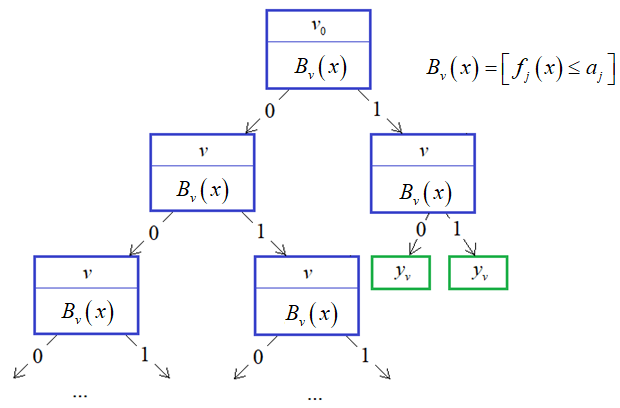
Фактически это связный ациклический граф, в котором есть корень, внутренние вершины и листы (вершины без потомков). Причем, каждая внутренняя вершина имеет ровно два ответвления, соответствующие стрелкам «да» и «нет». Именно поэтому дерево с такой структурой называют бинарным. Если у нас есть уже построенное дерево по множеству данных, то логический вывод делается очень просто. Предположим, мы классифицируем вектор
с n признаками.
Тогда, начиная с корневой вершины
То есть, мы
смотрим на j-й признак для
вектора В следующей
промежуточной вершине повторяем этот процесс и с помощью предиката Как только дошли
до листа, относим вектор
Однако, чтобы
проделать такой вывод, мы с вами должны знать структуру дерева, набор
предикатов Итак, главный
вопрос, как построить бинарное решающее дерево по множеству данных обучающей
выборки
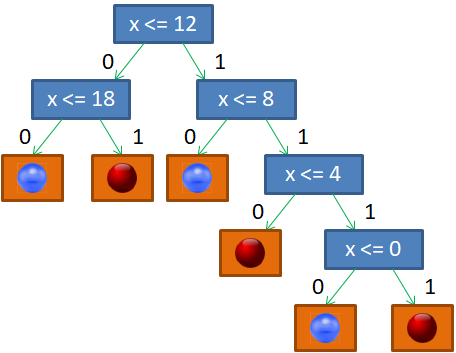
Здесь вектор
И, так как
признак всего один, то Если бы разбиение делал я сам, то предложил бы следующее решающее дерево:
Почему именно так? В действительности, можно было бы придумать и другие варианты. Я руководствовался простым принципом: в каждой вершине порог t следует выбирать так, чтобы в одной части было как можно больше представителей только одного какого-либо класса (шаров одного цвета), а в другой – все оставшиеся. То есть, это некий критерий здравого смысла, естественная эвристика, которая сокращает глубину дерева. Но вы можете сказать, а зачем нам минимизировать глубину решающего дерева? Пусть оно получается таким, каким сделает его алгоритм. Например, будем поочередно перебирать пороги t от 0 до 19 и рано или поздно гарантированно разобьем последовательность шаров на красные и синие. Да, дерево будет значительно глубже, ну и что? Однако, здесь всегда следует помнить, что данная последовательность всего лишь обучающая выборка. Мы предполагаем использовать это дерево и для других подобных последовательностей с несколько другим распределением синих и красных шаров. Иначе, это была бы не задача машинного обучения, а просто разбиение конкретной выборки. Так вот, можно заметить, что чем меньше глубина решающего дерева, тем меньше используется порогов разбиения и тем выше, в среднем, обобщающая способность такого дерева. Именно поэтому стараются строить деревья минимальной глубины. Но как это сделать? В самом простом варианте можно выполнить полный перебор всех возможных разбиений и выбрать дерево минимальной глубины. Для нашей задачи это еще как-то можно было бы реализовать. Но, как вы понимаете, в общем случае, это займет так много времени, что не хватит и жизни всего человечества. Поэтому здесь нужно искать другие подходы. Если вернуться к моему варианту бинарного дерева, то, как я отмечал, в каждой промежуточной вершине старался порог t выбирать так, чтобы в одной части было как можно больше представителей одного класса (шаров одного цвета), а в другой как получится, т.е. все оставшиеся. Это некая эвристика. Наша цель, наделить алгоритм примерно такой же эвристикой. Как это сделать? Математики обратили свои взоры в ранние наработки самых разных формул и представили миру несколько критериев качества предикатов. Одним из популярных стала энтропия:
где
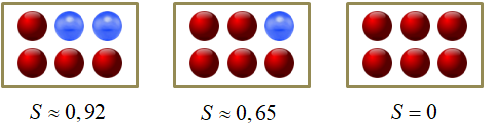
Такую характеристику в решающих деревьях называют impurity (информативностью). Чем она меньше, тем лучше (качественнее) набор данных в вершине. И, наоборот, чем она больше, тем разнообразнее (хаотичнее) данные в вершине. Вернемся, теперь, к примеру разбиения последовательности красных и синих шаров. Последовательность состоит из N=2 классов с вероятностями появления каждого из них:
Следовательно, impurity (в данном случае энтропия) корневой вершины дерева, равна:
Далее, мы выбираем предикат с порогом t = 12:
и получаем две подвыборки с impurity (энтропиями):
Величина 0,6 значительно меньше начального значения 0,993, а значит, во второй последовательности больше порядка, чем в исходной. И это очень хорошо. Именно этого мы и добиваемся, выбирая порог t. Теперь, нам
нужно на основе величин
где
Если посчитать этот критерий для других порогов t, то окажется, что при t = 12 имеем наибольшее значение. А, значит, наилучшее разбиение с точки зрения выбранных критериев: энтропии и информационного выигрыша. Математически поиск наилучшего предиката в текущей вершине дерева, можно записать так:
Или, в общем
случае, учитывая, что мы подбираем не только пороги, но и признаки
А в качестве impurity, помимо энтропии также используют:
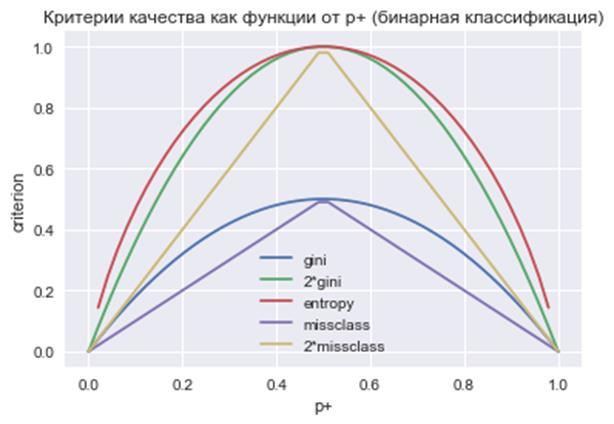
(Критерий Джини не следует путать с индексом Джини, о котором мы ранее говорили – это две совершенно разные характеристики.) На практике критерий Джини работает почти также, как и энтропия. Это хорошо видно из графиков данных критериев при бинарной классификации:
Здесь по оси
абсцисс (горизонтальной оси) отложена вероятность На следующем занятии мы рассмотрим два алгоритма построения решающих деревьев, используя рассмотренные критерии качества разбиения. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |