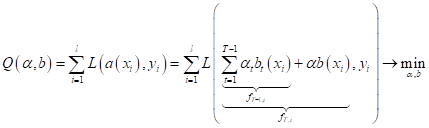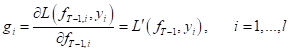|
Градиентный бустинг и стохастический градиентный бустингПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущих занятиях мы с вами разобрались в принципе бустинга простых алгоритмов – формирования их композиции для задач регрессии и классификации:
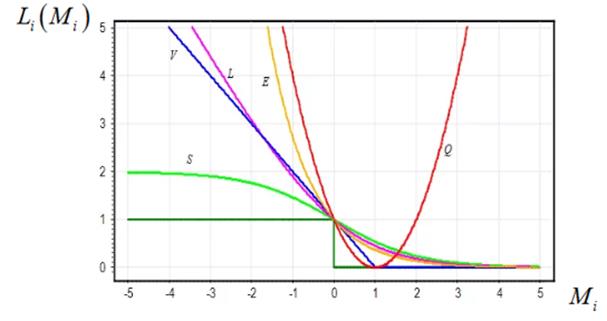
При этом, мы увидели, что в разных задачах используются разные функции потерь в функционале качества композиции:
по обучающей
выборке
И так далее. Можно придумать много других функций для разработки (синтеза) новых алгоритмов бустинга. И здесь возникает естественный вопрос. А можно ли создать универсальный алгоритм бустинга, который бы работал с произвольной гладкой и дифференцируемой функцией потерь? Оказывается да, можно и такой подход получил название градиентного бустинга. Впервые градиентный бустинг представил Jerome Friedman (Джером Фридман) в 1999 году. Эта идея оказалась настолько продуктивной, что градиентный бустинг стал одним из стандартных инструментов для попыток решить ту или иную задачу машинного обучения. В частности, знаменитый Матрикснет от компании Яндекс использует его над небрежными решающими деревьями (ODT) при ранжировании поисковой выдачи. И, как видите, это работает вполне неплохо. Давайте вначале разберемся в принципах работы градиентного бустинга. Я взял фрагмент его вывода из лекций профессора Воронцова, как наиболее простой и понятный. Итак, все начинается с построения взвешенной композиции алгоритмов:
и выбора
функционала качества для поиска весов
Я здесь сразу
расписал композицию через T-1 уже известных алгоритмов (найденных
на предыдущих T-1 шагах) и
текущего Выходы
композиции по T-1 алгоритмам
для каждого образа
А выходы по всем T алгоритмам – через вектор:
Тогда смотрите,
что получается. На следующем шаге T мы должны выбрать такой вектор
то корректировку i-го компонента можно записать, следующим образом:
А у нас в формуле (согласно композиции алгоритмов) эта же самая корректировка выглядит, как:
Сходство
очевидно. И, так как, коэффициент
Здесь используется квадратическая функция, как мера близости i-х значений и суммируется все по обучающей выборке. Почему именно квадратическая функция? Потому что она, в ряде случаев, позволяет аналитически найти решение по методу наименьших квадратов (МНК). Мало того, решающие деревья для задач регрессии часто по умолчанию используют именно этот критерий. Итак, мы
довольно просто можем найти наилучший алгоритм
Ее можно достаточно быстро (в вычислительном плане) решить численными методами. Современные методы оптимизации с этим легко справляются (например, метод половинного деления). Все, мы только что с вами разобрали принцип работы градиентного бустинга. И чтобы было все понятнее, приведу его псевдокод: Вход: обучающая
выборка Выход: набор базовых
алгоритмов 1: начальная
инициализация: 2: для
всех
3: найти наилучший текущий алгоритм, приближающий антиградиент:
4: нахождение весового коэффициента:
5: обновление вектора значений на объектах выборки:
Фактически, это универсальная обертка над множеством выбранного семейства базовых алгоритмов и функции потерь. На выходе получаем композицию алгоритмов, найденных по конкретной обучающей выборке. Часто в качестве семейства базовых алгоритмов выбирают решающие деревья. Из них получаются хорошие композиции, способные конкурировать с лучшими алгоритмами машинного обучения. Стохастический градиентный бустингВ алгоритмах градиентного бустинга, что мы рассматривали, предполагалось использование всей обучающей выборки для вычисления весов и определения алгоритмов. Но что делать, если выборка очень большая и избыточная? Тогда объем вычислений также может стать очень большим. Джером Фридман в том же 1999 году предложил очень простое решение. Давайте на каждой t-й итерации формировать выборку меньшей длины из случайно выбранных объектов исходной обучающей выборки. И оказалось, что это может приводить даже к лучшим результатам, чем использование каждый раз всей выборки. В частности было замечено:
Такой подход (с использованием случайных выборок) стали называть стохастическим градиентным бустингом (Stochastic Gradient Boosting – SGB). Реализация градиентного бустинга на PythonНа языке Python очень легко реализовывать различные алгоритмы бустинга. Начиная с простого AdaBoost и заканчивая продвинутым градиентным бустингом XGBoost (быстрый алгоритм градиентного бустинга над решающими деревьями). Для этого имеются следующие классы библиотеки Scikit-Learn:
А для использования XGBoost следует установить дополнительную библиотеку: pip install xgboost Подробную информацию можно посмотреть на странице официальной документации: https://xgboost.readthedocs.io/en/stable/ По умолчанию все представленные алгоритмы бустинга использую решающие деревья для формирования композиции. И, скорее всего, вам не придется менять этот базовый функционал, т.к. деревья, как я уже отмечал, используются в 99% при бустинге. Вот, что в целом из себя представляет бустинг простых алгоритмов и как его можно обобщить на произвольные функции потерь с помощью градиентного бустинга. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |