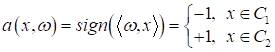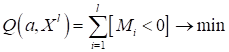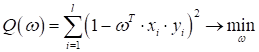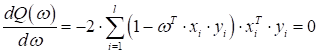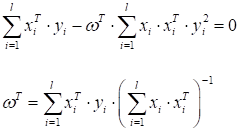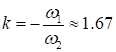|
Функции потерь в задачах линейной бинарной классификацииПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs На предыдущем занятии мы с вами рассмотрели простейший пример обучения модели бинарной линейной классификации вот в таком виде:
где
Кроме того, мы, фактически, придумали алгоритм для нахождения этого единственного коэффициента. Однако, хотелось бы свести эту задачу к задаче математической оптимизации по некоторому критерию качества, а также обобщить на произвольное число коэффициентов. Начнем с определения показателя качества. На предыдущем занятии он у нас вычислялся по количеству неверно классифицируемых наблюдений (входных векторов):
Напомню, что здесь в качестве отступа мы используем величину:
а в качестве функции потерь:
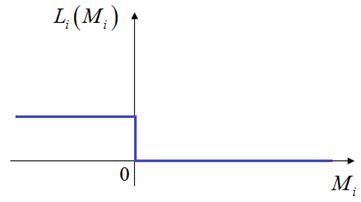
(Здесь квадратные скобки – это индикатор ошибки. В соответствии с нотацией Айверсона они возвращают 1 для True и 0 – для False). Если изобразить эту функцию потерь, зависящую от отступа, то получим ступенчатый график:
Как вы
понимаете, он не имеет производных в точках перегиба, да и во всех остальных
производные будут равны 0. То есть, эта функция не подходит для задачи
математической оптимизации при поиске весовых коэффициентов
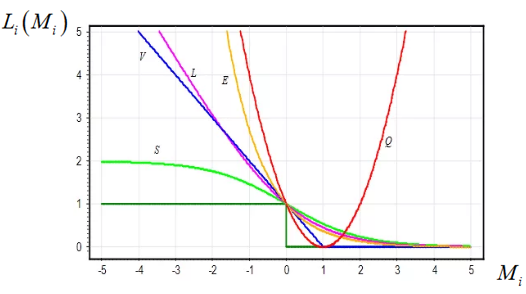
Особенность всех этих функций (помимо того, что они всюду дифференцируемы) в том, что они по значению больше, либо раны исходной пороговой. Следовательно, минимизируя любую из них, мы автоматически будем минимизировать потери и при пороговой функции. Давайте посмотрим, как это можно использовать для квадратичной функции потерь:
Тогда функционал качества запишется в виде:
Здесь мы можем
найти оптимальный вектор коэффициентов
откуда
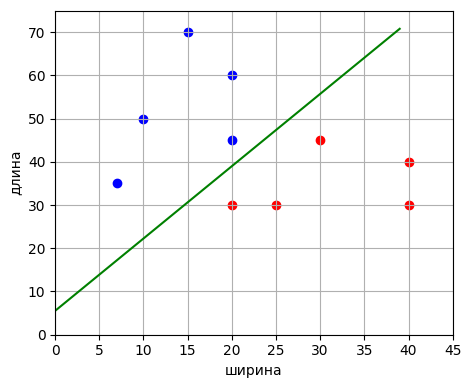
Давайте сделаем вычисления по этой формуле в программе на Python, применительно к нашей задаче бинарной классификации гусениц и божьих коровок:
Здесь каждое
наблюдение представлено двумя признаками: ширина и длина. Но у нас, в общем
виде вектор параметров
(добавляется еще смещение), так как уравнение разделяющей прямой записывается в виде:
Поэтому мы добавим к нашим наблюдениям еще один признак – константу 1:
Программа на Python будет следующей: После выполнения увидим значения коэффициентов: [ 0.05793234 -0.0346272 0.1912188 ] и график разделяющей линии:
То есть, здесь
и угловой коэффициент прямой:
Вот так просто мы решили ту же самую задачу бинарной классификации, но при этом использовали математический аппарат для поиска оптимальных коэффициентов. В этом одно из преимуществ замены пороговой не дифференцируемой функции на гладкие и всюду дифференцируемые. В различных известных методах классификации именно так и поступают – выбирают подходящие функции потерь и решают задачу минимизации эмпирического риска. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме |