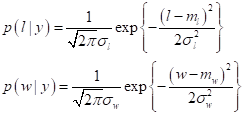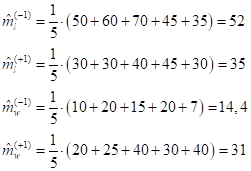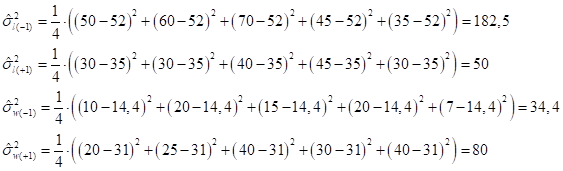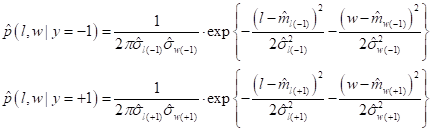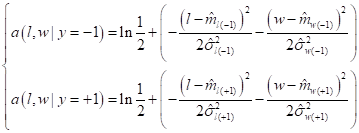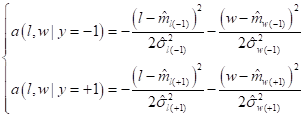|
Байесовский вывод. Наивная байесовская классификацияПрактический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Давайте
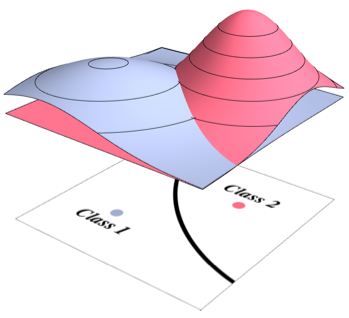
предположим, что мы рассматриваем некоторую задачу классификации. Для простоты,
бинарную (двухклассовую):
Эти данные
подчиняются некоторой совместной плотности распределения вероятностей (ПРВ)
Наша задача
отнести каждый конкретный входной вектор (образ)
Используя теорему Байеса, это выражение можно расписать, следующим образом:
Я здесь через заглавную букву P обозначил вероятность события, а через малую букву p – ПРВ. В этой формуле
множитель Предположим, мы
знаем величины
Обратите
внимание, я здесь отбросил распределение Вот так, с позиции теоремы Байеса, ставится задача классификации в машинном обучении. Причем, число классов может быть не два, а сколько угодно, ограничений здесь никаких нет. Оптимальный байесовский классификаторВообще, на
практике в эту модель добавляют еще множители
Существует теорема, которая доказывает, что в этом случае будут минимизироваться средние ошибки, то есть, функционал вида:
Минимизация данного критерия соответствует оптимальному байесовскому классификатору. Подробно о нем я уже рассказывал: https://www.youtube.com/watch?v=OhIp6qJkvCI По этой ссылке вы также найдете пример простой байесовской классификации мужчин и женщин по двум признакам: высота и вес. Получается, что
если бы мы знали совместную ПРВ
по обучающей выборке. Конечно, после того, как в байесовский классификатор подставляются оценки ПРВ, то он перестает быть оптимальным. Поэтому оптимальность здесь, скорее, представляет теоретический интерес. На практике, реальные классификаторы могут лишь приближаться к оптимальному. Наивный байесовский классификаторГлавная проблема
в реализации байесовского классификатора – это оценить условные ПРВ
То есть, так,
как это мы делали с самого начала. Значит, байесовский (вероятностный) подход к
задачам машинного обучения – это лишь интересный теоретический трюк? Не совсем.
Во-первых, как мы уже видели, он дает лучшее понимание работы алгоритмов
машинного обучения. А, во-вторых, мы можем упростить задачу оценки многомерной
условной ПРВ
независимы между собой. В этом случае многомерная ПРВ расписывается через произведение соответствующих одномерных ПРВ:
Такое, вообще говоря, сильное предположение о независимости признаков, приводит нас к алгоритму, известному под названием наивный байесовский классификатор:
Или, эквивалентный вывод часто делают по логарифму от произведения величин (уходят от произведений):
Как видите, мы здесь оперируем только одномерными ПРВ и это сильно упрощает задачу, т.к. восстановить одномерную плотность гораздо проще, чем многомерную. И еще одно важно
замечание. Часто в сторонних библиотеках алгоритм наивного байесовского
классификатора реализуют с использованием гауссовских ПРВ Пример задачи классификации наивным байесовским классификаторомВ заключение этого занятия приведу пример использования наивного байесовского классификатора для уже знакомой нам задачи разделения гусениц и божьих коровок. Обучающая
выборка задана таблицей с двумя классами
Будем предполагать, что признаки ширина и длина независимы и подчиняются нормальному закону распределения:
где l (length) – длина жука; w (width) – ширина; Наша задача определить параметры гауссовских распределений по обучающей выборке. Сначала найдем МО (средние значения) признаков для обоих классов (как средние арифметические):
А, затем, дисперсии по формуле:
получим:
Далее, сформируем условные ПРВ для первого и второго классов по правилу:
И в итоге получаем следующее:
Осталось определить априорные вероятности появления классов в выборке. В нашем случае они будут равны:
так как имеем по 5 объектов каждого класса. Все вероятности и ПРВ определены. Теперь можно построить классификатор по правилу:
Величины штрафов возьмем одинаковыми для обоих классов:
получим:
И, так как
слагаемое
Все, мы с вами
получили алгоритм классификации. Здесь нужно вычислить величины Реализацию этого алгоритма на Python можно посмотреть по ссылке: Я, думаю, что вы теперь представляете общий принцип построения байесовского классификатора и реализацию его в простейшем случае по методу наивного байеса. Практический курс по ML: https://stepik.org/course/209247/?utm_source=proproprogs Видео по теме | |||||||||||||||||||||||||||||||||||||||||||||||||||||||